スケーリングと並列処理
多くのバッチ処理の問題は、シングルスレッドのシングルプロセスジョブで解決できるため、より複雑な実装について考える前に、それがニーズを満たしているかどうかを適切に確認することを常にお勧めします。現実的なジョブのパフォーマンスを測定し、最も単純な実装が最初にニーズを満たすかどうかを確認します。標準的なハードウェアでも、数百メガバイトのファイルを 1 分もかからずに読み書きできます。
いくつかの並列処理を使用してジョブの実装を開始する準備ができたら、Spring Batch にはさまざまなオプションが用意されています。これらのオプションについては、この章で説明します。大まかに言うと、並列処理には 2 つのモードがあります。
シングルプロセス、マルチスレッド
マルチプロセス
これらは、次のようにカテゴリにも分類されます。
マルチスレッドステップ (single-process)
並行ステップ (single-process)
ステップのローカルチャンク化 (single-process)
リモートステップのチャンキング (multi-process)
ステップの分割 (シングルまたはマルチプロセス)
リモートステップ (multi-process)
最初に、単一プロセスのオプションを確認します。次に、マルチプロセスオプションを確認します。
マルチスレッドステップ
並列処理を開始する最も簡単な方法は、TaskExecutor をステップ構成に追加することです。
Java
XML
Java 構成を使用する場合、次の例に示すように、ステップに TaskExecutor を追加できます。
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10).transactionManager(transactionManager)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.build();
} 例: 次のように、属性を tasklet に追加できます。
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step> この例では、taskExecutor は、TaskExecutor インターフェースを実装する別の Bean 定義への参照です。TaskExecutor (Javadoc) は標準の Spring インターフェースです。使用可能な実装の詳細については、Spring ユーザーガイドを参照してください。最も単純なマルチスレッド TaskExecutor は SimpleAsyncTaskExecutor です。
上記の構成の結果、Step はタスクエグゼキュータの複数のスレッドを使用してアイテムを並行処理します。そのため、ItemProcessor は複数のスレッドから同時に呼び出されます。つまり、ItemProcessor はスレッドセーフである必要があります。処理にステートフルコンポーネントを使用する場合は、同時アクセスのために適切に同期されていることを確認する必要があります。
Spring トランザクションはスレッドに紐づいているため、ワーカースレッドで実行されるアイテムプロセッサー呼び出しは、ステップで構成されたチャンクトランザクションには参加しません。アイテムプロセッサーがトランザクション管理を必要とする場合は、たとえば REQUIRED の伝播を使用して独自のトランザクションを開始する必要があります。たとえば MANDATORY の伝播を使用するなど、既存のトランザクションを必要とするプロセッサーは、ワーカースレッドですでにトランザクションがアクティブになっていない限り失敗します。デリゲートがチャンク周辺のトランザクションを管理できるワーカースレッドでチャンク全体を処理する必要性がある場合は、代わりにローカルチャンキングの使用を検討してください。
アイテムの読み取りと書き込みは、ステップを実行するメインスレッドによって引き続きシリアルに実行されるため、ItemReader と ItemWriter はスレッドセーフである必要も、同期されている必要もありません。ただし、ステップのスループットは読み取りと書き込みの速度によって制限される可能性があります。その場合は、ローカルチャンクやローカルパーティショニングなどの別の同時実行手法の使用を検討してください。
また、ステップで使用されるプールされたリソース(DataSource など)によって並行性に制限が設定される場合があることに注意してください。これらのリソースのプールは、少なくともステップで必要な同時スレッドの数と同じ大きさにしてください。
並行ステップ
並列化が必要なアプリケーションロジックを個別のロールに分割し、個々のステップに割り当てることができる限り、単一のプロセスで並列化できます。Parallel Step の実行は、設定と使用が簡単です。
Java
XML
Java 構成を使用する場合、次のように、ステップ (step1,step2) を step3 と並行して実行するのは簡単です。
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
.start(splitFlow())
.next(step4())
.build() //builds FlowJobBuilder instance
.build(); //builds Job instance
}
@Bean
public Flow splitFlow() {
return new FlowBuilder<SimpleFlow>("splitFlow")
.split(taskExecutor())
.add(flow1(), flow2())
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
}
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
} 例: 次のように、ステップ (step1,step2) を step3 と並行して実行するのは簡単です。
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/> 構成可能なタスクエグゼキューターは、個々のフローを実行する TaskExecutor 実装を指定するために使用されます。デフォルトは SyncTaskExecutor ですが、ステップを並行して実行するには非同期 TaskExecutor が必要です。このジョブは、終了ステータスを集約して移行する前に、分割内のすべてのフローが確実に完了することに注意してください。
詳細については、フローの分割のセクションを参照してください。
ローカルチャンキング
ローカルチャンキングは、v6.0 の新機能で、複数のスレッドを使用して同じ JVM 内でアイテムのチャンクを並列処理できます。これは、処理するアイテムの数が多く、マルチコアプロセッサーを活用したい場合に特に便利です。ローカルチャンキングを使用すると、チャンク指向のステップを構成して、複数のスレッドを使用してアイテムのチャンクを同時に処理できます。
この機能は、TaskExecutor からローカルワーカーにチャンクリクエストを送信するアイテムライターである ChunkTaskExecutorItemWriter を使用することで可能になります。
@Bean
public ChunkTaskExecutorItemWriter<Vet> itemWriter(ChunkProcessor<Vet> chunkProcessor) {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(4);
taskExecutor.setThreadNamePrefix("worker-thread-");
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.afterPropertiesSet();
return new ChunkTaskExecutorItemWriter<>(chunkProcessor, taskExecutor);
}ChunkTaskExecutorItemWriter は、チャンクを並行処理するための TaskExecutor と、各チャンクの処理方法を定義するための ChunkProcessor を必要とします。タスク実行子からの各スレッドは、それぞれ独自のアイテムのチャンクを受け取り、そのチャンクの処理を担当します。そして、ステップは結果の全体的な集約を管理します。
以下は、アイテムの各チャンクをリレーショナルデータベーステーブルに書き込むチャンクプロセッサーの例です。
@Bean
public ChunkProcessor<Vet> chunkProcessor(DataSource dataSource, TransactionTemplate transactionTemplate) {
String sql = "insert into vets (firstname, lastname) values (?, ?)";
JdbcBatchItemWriter<Vet> itemWriter = new JdbcBatchItemWriterBuilder<Vet>().dataSource(dataSource)
.sql(sql)
.itemPreparedStatementSetter((item, ps) -> {
ps.setString(1, item.firstname());
ps.setString(2, item.lastname());
})
.build();
return (chunk, contribution) -> transactionTemplate.executeWithoutResult(transactionStatus -> {
try {
itemWriter.write(chunk);
contribution.incrementWriteCount(chunk.size());
contribution.setExitStatus(ExitStatus.COMPLETED);
}
catch (Exception e) {
transactionStatus.setRollbackOnly();
contribution.incrementWriteSkipCount(chunk.size());
contribution.setExitStatus(ExitStatus.FAILED.addExitDescription(e));
}
});
} チャンクのトランザクション管理およびフォールトトレランス機能(再試行、スキップ、チャンクスキャンなど)は、 |
このスケーリング手法の例は、ローカルチャンクサンプル [GitHub] (英語) にあります。
リモートチャンキング
リモートチャンキングでは、Step 処理は複数のプロセスに分割され、いくつかのミドルウェアを介して相互に通信します。次のイメージはパターンを示しています。
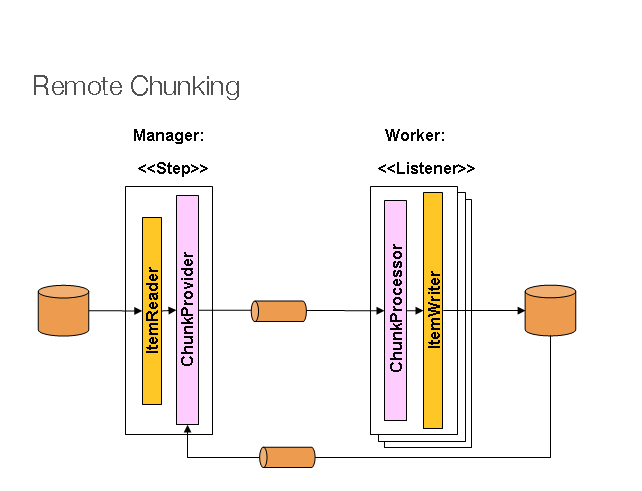
マネージャーコンポーネントは単一のプロセスであり、ワーカーは複数のリモートプロセスです。このパターンは、マネージャーがボトルネックでない場合に最適に機能するため、処理はアイテムの読み取りよりも高負荷でなければなりません(実際によくあることです)。
マネージャーは Spring Batch Step の実装であり、ItemWriter は、アイテムのチャンクをメッセージとしてミドルウェアに送信する方法を知っている汎用バージョンに置き換えられています。ワーカーは、使用されているミドルウェア (たとえば、JMS では MesssageListener 実装) の標準リスナーであり、そのロールは、ChunkProcessor インターフェースを介して、標準 ItemWriter または ItemProcessor と ItemWriter を使用してアイテムのチャンクを処理することです。このパターンを使用する利点の 1 つは、リーダー、プロセッサー、ライターコンポーネントが既製であることです (ステップのローカル実行に使用されるものと同じ)。アイテムは動的に分割され、ミドルウェアを介して作業が共有されるため、リスナーがすべて先行したコンシューマーである場合、負荷分散は自動的に行われます。
ミドルウェアは耐久性があり、配信が保証され、メッセージごとに単一のコンシューマーが必要です。JMS は明らかな候補ですが、他のオプション(JavaSpaces など)はグリッドコンピューティングおよび共有メモリ製品スペースに存在します。
詳細については、Spring Batch Integration - リモートチャンキングのセクションを参照してください。
パーティショニング
Spring Batch は、Step 実行を分割してリモートで実行するための SPI も提供します。この場合、リモート参加者は Step インスタンスであり、ローカル処理に同様に簡単に構成および使用できます。次のイメージはパターンを示しています。
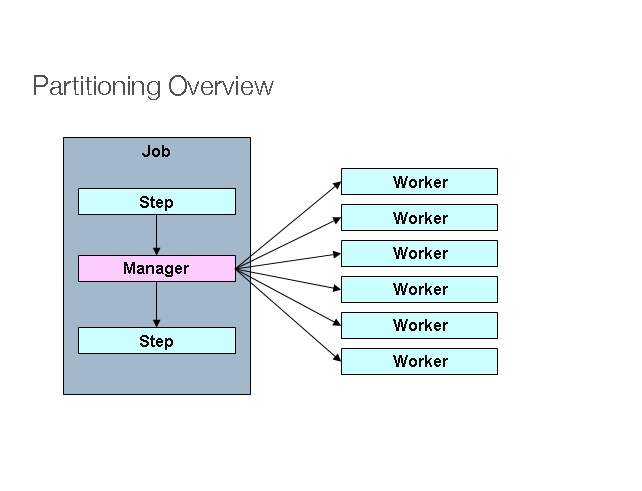
Job は、一連の Step インスタンスとして左側で実行され、Step インスタンスの 1 つはマネージャーとしてラベル付けされます。この図のワーカーは、すべて Step の同一インスタンスであり、実際にはマネージャーの代わりになり、結果として Job でも同じ結果になります。ワーカーは通常リモートサービスになりますが、実行のローカルスレッドになることもあります。このパターンでマネージャーからワーカーに送信されるメッセージは、永続的である必要も、配信が保証されている必要もありません。JobRepository の Spring Batch メタデータにより、各ワーカーは Job の実行ごとに 1 回だけ実行されます。
Spring Batch の SPI は、Step の特別な実装 ( PartitionStep と呼ばれる) と、特定の環境用に実装する必要がある 2 つの戦略インターフェースで構成されます。戦略インターフェースは PartitionHandler および StepExecutionSplitter であり、次のシーケンス図はそれらのロールを示しています。
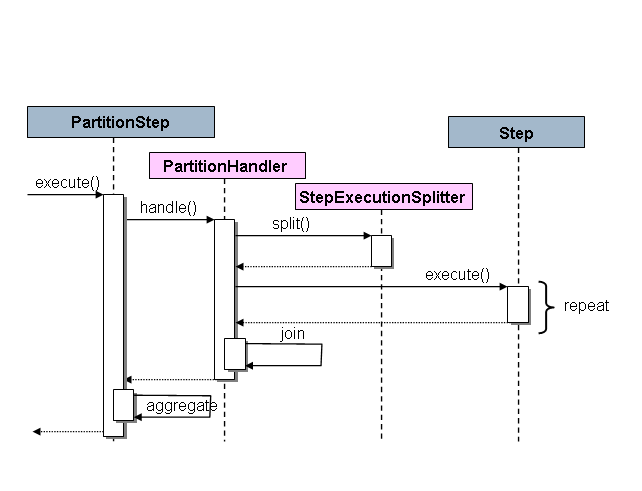
この場合の右側の Step は「リモート」ワーカーであるため、このロールを果たしているオブジェクトやプロセスが多数存在する可能性があり、実行を駆動する PartitionStep が示されています。
Java
XML
次の例は、Java 構成を使用する場合の PartitionStep 構成を示しています。
@Bean
public Step step1Manager(JobRepository jobRepository) {
return new StepBuilder("step1.manager", jobRepository)
.<String, String>partitioner("step1", partitioner())
.step(step1())
.gridSize(10)
.taskExecutor(taskExecutor())
.build();
}gridSize 方式は、タスク実行部が単一ステップからのリクエストで飽和状態になるのを防ぎます。
次の例は、XML 構成を使用する場合の PartitionStep 構成を示しています。
<step id="step1.manager">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>grid-size 属性は、タスク実行エンジンが単一ステップからのリクエストで飽和状態になるのを防ぎます。
Spring Batch は、step1:partition0 などと呼ばれるパーティションのステップ実行を作成します。多くの人は、一貫性のためにマネージャーのステップを step1:manager と呼ぶことを好みます。ステップに別名を使用できます (id 属性の代わりに name 属性を指定することにより)。
PartitionHandler
PartitionHandler は、リモーティングまたはグリッド環境の構造を認識するコンポーネントです。DTO などのファブリック固有のフォーマットでラップされた リモート Step インスタンスに StepExecution リクエストを送信できます。入力データを分割する方法や、複数の Step 実行の結果を集約する方法を知る必要はありません。一般的に言えば、多くの場合、回復力やフェイルオーバーはファブリックの機能であるため、それらについて知る必要はおそらくありません。いずれにせよ、Spring Batch は、ファブリックに関係なく、常に再始動可能性を提供します。失敗した Job はいつでも再起動でき、その場合、失敗した Steps だけが再実行されます。
PartitionHandler インターフェースは、単純な RMI リモート処理、EJB リモート処理、カスタム Web サービス、JMS、Java Spaces、共有メモリグリッド (Terracotta や Coherence など)、グリッド実行ファブリック (GridGain など) など、さまざまなファブリック型に特化した実装を持つことができます)。Spring Batch には、独自のグリッドまたはリモートファブリックの実装は含まれていません。
ただし、Spring Batch は、Spring の TaskExecutor 戦略を使用して、Step インスタンスを個別の実行スレッドでローカルに実行する PartitionHandler の便利な実装を提供します。実装は TaskExecutorPartitionHandler と呼ばれます。
Java
XML
次のように、Java 構成を使用して TaskExecutorPartitionHandler を明示的に構成できます。
@Bean
public Step step1Manager(JobRepository jobRepository) {
return new StepBuilder("step1.manager", jobRepository)
.partitioner("step1", partitioner())
.partitionHandler(partitionHandler())
.build();
}
@Bean
public PartitionHandler partitionHandler() {
TaskExecutorPartitionHandler retVal = new TaskExecutorPartitionHandler();
retVal.setTaskExecutor(taskExecutor());
retVal.setStep(step1());
retVal.setGridSize(10);
return retVal;
}TaskExecutorPartitionHandler は、前に示した XML 名前空間で構成されたステップのデフォルトです。次のように、明示的に構成することもできます。
<step id="step1.manager">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>gridSize 属性は、作成する個別のステップ実行の数を決定するため、TaskExecutor のスレッドプールのサイズと一致させることができます。または、使用可能なスレッドの数よりも大きく設定して、作業ブロックを小さくすることもできます。
TaskExecutorPartitionHandler は、大量のファイルのコピーやコンテンツ管理システムへのファイルシステムの複製など、IO 集約型の Step インスタンスに役立ちます。リモート呼び出しのプロキシである Step 実装を提供することにより、リモートの実行にも使用できます(Spring Remoting の使用など)。
パーティショナー
Partitioner の責任は単純です: 新しいステップ実行のみの入力パラメーターとして実行コンテキストを生成します (再起動について心配する必要はありません)。次のインターフェース定義が示すように、単一のメソッドがあります。
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
} このメソッドからの戻り値は、各ステップ実行の一意の名前 ( String) を ExecutionContext の形式の入力パラメーターに関連付けます。名前は、パーティション化された StepExecutions のステップ名としてバッチメタデータに後で表示されます。ExecutionContext は名前と値のペアの袋にすぎないため、一連の主キー、行番号、入力ファイルの場所が含まれる場合があります。次に、リモート Step は通常、次のセクションで示すように、#{…} プレースホルダー (ステップスコープでの遅延バインディング) を使用してコンテキスト入力にバインドします。
ステップ実行の名前 (Partitioner が返す Map のキー) は、Job のステップ実行の中でユニークである必要がありますが、それ以外の特別な要件はありません。これを実現する最も簡単な方法は、プレフィックスとサフィックスの命名規則を使うことです。プレフィックスには実行中のステップの名前 (これ自体が Job で一意になります) を、サフィックスには単なるカウンターを指定します。フレームワークには、この命名規則を使用する SimplePartitioner があります。
PartitionNameProvider と呼ばれるオプションのインターフェースを使用して、パーティション名をパーティション自体とは別に指定できます。Partitioner がこのインターフェースを実装している場合、再始動時に名前のみが照会されます。パーティショニングが高負荷な場合、これは有用な最適化になる可能性があります。PartitionNameProvider によって提供される名前は、Partitioner によって提供される名前と一致する必要があります。
入力データをステップにバインドする
PartitionHandler によって実行されるステップが同一の構成を持ち、実行時に ExecutionContext から入力パラメーターがバインドされることは非常に効率的です。これは、Spring Batch の StepScope 機能を使用して簡単に実行できます(遅延バインディングのセクションで詳細に説明されています)。例: Partitioner が fileName という属性キーを使用して ExecutionContext インスタンスを作成し、各ステップ呼び出しごとに異なるファイル(またはディレクトリ)を指す場合、Partitioner 出力は次の表の内容のようになる場合があります。
ステップ実行名(キー) | ExecutionContext(値) |
filecopy:partition0 | fileName =/home/data/one |
filecopy:partition1 | fileName =/home/data/two |
filecopy:partition2 | fileName =/home/data/three |
次に、実行コンテキストへの遅延バインディングを使用して、ファイル名をステップにバインドできます。
Java
XML
次の例は、Java で遅延バインディングを定義する方法を示しています。
@Bean
public MultiResourceItemReader itemReader(
@Value("#{stepExecutionContext['fileName']}/*") Resource [] resources) {
return new MultiResourceItemReaderBuilder<String>()
.delegate(fileReader())
.name("itemReader")
.resources(resources)
.build();
}次の例は、XML で遅延バインディングを定義する方法を示しています。
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resources" value="#{stepExecutionContext[fileName]}/*"/>
</bean>完全な例はパーティショニングのサンプル [GitHub] (英語) にあります。
リモートステップ実行
v6.0 以降、Spring Batch はリモートステップ実行をサポートし、バッチジョブのステップをリモートマシンまたはクラスター上で実行できるようになりました。この機能は、パフォーマンスとスケーラビリティを向上させるためにワークロードを複数のノードに分散させたい大規模なバッチ処理シナリオで特に役立ちます。リモートステップ実行は RemoteStep クラスによって提供され、Spring Integration メッセージングチャネルを使用して、ローカルジョブ実行環境とリモートステップエグゼキューター間の通信を可能にします。
RemoteStep は、リモートステップ名と、ステップ実行リクエストを リモートワーカーに送信するためのメッセージングテンプレートを提供することにより、通常のステップとして構成されます。
@Bean
public Step step(MessagingTemplate messagingTemplate, JobRepository jobRepository) {
return new RemoteStep("step", "workerStep", jobRepository, messagingTemplate);
} ワーカー側では、実行する リモートステップ (この例では workerStep ) を定義し、ステップ実行リクエストをインターセプトして StepExecutionRequestHandler を呼び出すように Spring Integration フローを構成する必要があります。
@Bean
public Step workerStep(JobRepository jobRepository, JdbcTransactionManager transactionManager) {
return new StepBuilder("workerStep", jobRepository)
// define step logic
.build();
}
/*
* Configure inbound flow (requests coming from the manager)
*/
@Bean
public DirectChannel requests() {
return new DirectChannel();
}
@Bean
public IntegrationFlow inboundFlow(ActiveMQConnectionFactory connectionFactory, JobRepository jobRepository,
StepLocator stepLocator) {
StepExecutionRequestHandler stepExecutionRequestHandler = new StepExecutionRequestHandler();
stepExecutionRequestHandler.setJobRepository(jobRepository);
stepExecutionRequestHandler.setStepLocator(stepLocator);
return IntegrationFlow.from(Jms.messageDrivenChannelAdapter(connectionFactory).destination("requests"))
.channel(requests())
.handle(stepExecutionRequestHandler, "handle")
.get();
}
@Bean
public StepLocator stepLocator(BeanFactory beanFactory) {
BeanFactoryStepLocator beanFactoryStepLocator = new BeanFactoryStepLocator();
beanFactoryStepLocator.setBeanFactory(beanFactory);
return beanFactoryStepLocator;
}完全な例はリモートステップサンプル [GitHub] (英語) にあります。

