バッチのドメイン言語
経験豊富なバッチアーキテクトにとって、Spring Batch で使用されるバッチ処理の全体的な概念は、親しみやすく快適なものです。「ジョブ」と「ステップ」、および ItemReader と ItemWriter と呼ばれる開発者提供の処理ユニットがあります。ただし、Spring のパターン、操作、テンプレート、コールバック、イディオムがあるため、次の可能性があります。
関心事の明確な分離への遵守の大幅な改善。
インターフェースとして提供される明確に描かれたアーキテクチャ層とサービス。
迅速な採用とすぐに使える使いやすさを可能にするシンプルでデフォルトの実装。
拡張性が大幅に向上しました。
次の図は、何十年も使用されてきたバッチリファレンスアーキテクチャの簡易版です。バッチ処理のドメイン言語を構成するコンポーネントの概要を提供します。このアーキテクチャフレームワークは、過去数世代のプラットフォーム (メインフレームでは COBOL、Unix では C、現在はどこでも Java) で数十年にわたって実装されてきた設計図です。JCL および COBOL の開発者は、C、C#、Java の開発者と同じように概念に慣れている可能性があります。Spring Batch は、単純なバッチアプリケーションから複雑なバッチアプリケーションの作成に対応するために使用される堅牢で保守可能なシステムに一般的に見られるレイヤー、コンポーネント、技術サービスの物理的な実装を提供し、非常に複雑な処理のニーズに対応するインフラストラクチャと拡張機能を備えています。
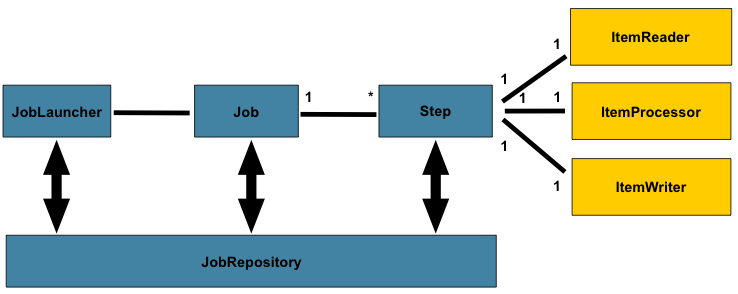
上の図は、Spring Batch のドメイン言語を構成する主要な概念を示しています。Job には 1 つ以上のステップがあり、各ステップには必ず 1 つの ItemReader、オプションの ItemProcessor、1 つの ItemWriter が含まれます。ジョブは JobOperator によって操作(開始、停止など)され、現在実行中のプロセスに関するメタデータは JobRepository に保存され、そこから復元されます。
ジョブ
このセクションでは、バッチジョブの概念に関連するステレオタイプについて説明します。Job は、バッチプロセス全体をカプセル化するエンティティです。他の Spring プロジェクトと同様に、Job は XML 構成ファイルまたは Java ベースの構成と一緒に接続されます。この構成は、「ジョブ構成」と呼ばれることがあります。ただし、次の図に示すように、Job は階層全体の最上位にすぎません。

Spring Batch では、Job は単に Step インスタンスのコンテナーです。これは、フロー内で論理的に一緒に属する複数のステップを結合し、再開可能性など、すべてのステップにグローバルなプロパティの構成を可能にします。ジョブ構成には次が含まれます。
ジョブの名前。
Stepインスタンスの定義と順序。ジョブが再開可能かどうか。
Java
XML
Java 構成を使用するユーザー向けに、Spring Batch は SimpleJob クラスの形式で Job インターフェースのデフォルト実装を提供し、Job の上にいくつかの標準機能を作成します。Java ベースの構成を使用する場合、次の例に示すように、ビルダーのコレクションを Job のインスタンス化に使用できるようになります。
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}XML 構成を使用するユーザー向けに、Spring Batch は SimpleJob クラスの形式で Job インターフェースのデフォルト実装を提供し、Job の上にいくつかの標準機能を作成します。ただし、バッチ名前空間により、直接インスタンス化する必要がなくなりました。代わりに、次の例に示すように、<job> 要素を使用できます。
<job id="footballJob">
<step id="playerload" next="gameLoad"/>
<step id="gameLoad" next="playerSummarization"/>
<step id="playerSummarization"/>
</job>JobInstance
JobInstance は、論理ジョブ実行の概念を指します。前の図の EndOfDay Job など、1 日の終わりに 1 回実行する必要があるバッチジョブを考えてみましょう。EndOfDay ジョブは 1 つありますが、Job の個々の実行は個別に追跡する必要があります。このジョブの場合、1 日あたり 1 つの論理 JobInstance があります。例: 1 月 1 日の実行、1 月 2 日の実行などがあります。1 月 1 日の実行が最初に失敗し、次の日に再度実行された場合でも、1 月 1 日の実行のままです。(通常、これは処理中のデータにも対応します。つまり、1 月 1 日の実行で 1 月 1 日のデータが処理されます)。各 JobInstance は複数の実行を持つことができ (JobExecution については、この章の後半で詳しく説明します)、特定の時間に実行できる JobInstance (特定の Job に対応し、JobParameters を識別する) は 1 つだけです。
JobInstance の定義は、ロードされるデータにはまったく関係ありません。データのロード方法を決定するのは、ItemReader の実装次第です。例: EndOfDay シナリオでは、データが属する effective date または schedule date を示す列がデータにある場合があります。1 月 1 日の実行では 1 日目のデータのみがロードされ、1 月 2 日の実行では 2 日目のデータのみが使用されます。この決定はビジネス上の決定である可能性が高いため、決定は ItemReader に任されています。ただし、同じ JobInstance を使用すると、以前の実行からの「状態」(つまり、この章で後述する ExecutionContext) が使用されるかどうかが決まります。新しい JobInstance を使用することは「最初から開始する」ことを意味し、既存のインスタンスを使用することは一般的に「中断したところから開始する」ことを意味します。
JobParameters
JobInstance とそれが Job とどのように異なるかについて説明したため、「ある JobInstance と他の JobInstance はどのように区別されるのですか ? 」という質問をするのは自然なことです。答えは: JobParameters です。JobParameters オブジェクトは、バッチジョブの開始に使用される一連のパラメーターを保持します。次の図に示すように、これらは識別のために、または実行中の参照データとしても使用できます。

ジョブインスタンスセクションの例では、1 月 1 日用と 1 月 2 日用の 2 つのインスタンスが存在しますが、実際には Job は 1 つだけです。しかし、このインスタンスには 2 つの JobParameter オブジェクトがあります。1 つはジョブパラメーター 01-01-2017 で開始され、もう 1 つはパラメーター 01-02-2017 で開始されています。契約は次のように定義できます。JobInstance = Job + 識別 JobParameters。これにより、開発者は渡されるパラメーターを制御できるため、JobInstance の定義方法を効果的に制御できます。
すべてのジョブパラメーターが JobInstance の識別にコントリビュートする必要はありません。デフォルトでは、そうします。ただし、このフレームワークでは、JobInstance の ID にコントリビュートしないパラメーターを使用して Job を送信することもできます。 |
JobExecution
JobExecution は、ジョブの実行を 1 回試行するという技術的概念を指します。実行は失敗または成功で終了する可能性がありますが、実行が正常に完了しない限り、特定の実行に対応する JobInstance は完了したとは見なされません。例として前に説明した EndOfDay Job を使用して、初めて実行したときに失敗した 01-01-2017 の JobInstance を考えてみましょう。最初の実行 (01-01-2017) と同じ識別ジョブパラメーターを使用して再度実行すると、新しい JobExecution が作成されます。ただし、JobInstance はまだ 1 つしかありません。
Job は、ジョブとは何か、どのように実行するかを定義します。JobInstance は、主に正しい再起動セマンティクスを有効にするために、実行をグループ化するための純粋に組織的なオブジェクトです。ただし、JobExecution は、実行中に実際に発生した内容の主要なストレージメカニズムであり、次の表に示すように、制御および永続化する必要があるさらに多くのプロパティが含まれています。
プロパティ | 定義 |
| 実行のステータスを示す |
| 実行が開始された現在のシステム時刻を表す |
| 実行が成功したかどうかに関係なく、実行が完了した時点のシステム時刻を表す |
| 実行結果を示す |
|
|
|
|
| 実行間で永続化する必要があるユーザーデータを含む「プロパティバッグ」。 |
|
|
これらのプロパティは永続化され、実行のステータスを完全に判断するために使用できるため、重要です。例: 01-01 の EndOfDay ジョブが 9:00 PM で実行され、9:30 で失敗した場合、次のエントリがバッチメタデータテーブルに作成されます。
JOB_INST_ID | JOB_NAME |
1 | EndOfDayJob |
JOB_EXECUTION_ID | TYPE_CD | KEY_NAME | DATE_VAL | IDENTIFYING |
1 | DATE | schedule.Date | 2017-01-01 | TRUE |
JOB_EXEC_ID | JOB_INST_ID | START_TIME | END_TIME | STATUS |
1 | 1 | 2017-01-01 21:00 | 2017-01-01 21:30 | FAILED |
| 列名は、明確さとフォーマットのために省略または削除されている場合があります。 |
ジョブが失敗したため、課題を特定するのに一晩かかったと仮定して、「バッチウィンドウ」を閉じます。さらに、ウィンドウが 9:00 PM で開始すると仮定すると、ジョブは 01-01 に対して再び開始され、中断したところから開始され、9:30 で正常に完了します。現在は翌日であるため、01-02 ジョブも実行する必要があり、その直後に 9:31 で開始され、10:30 で通常の 1 時間で完了します。2 つのジョブが同じデータにアクセスしようとして、データベースレベルでのロックの問題が発生する可能性がない限り、JobInstance を次々に開始する必要はありません。Job を実行するタイミングを決定するのは、完全にスケジューラ次第です。これらは別々の JobInstances であるため、Spring Batch はそれらが同時に実行されるのを止めようとはしません。(別の JobInstance がすでに実行されているときに同じ JobInstance を実行しようとすると、JobExecutionAlreadyRunningException がスローされます)。次の表に示すように、JobInstance テーブルと JobParameters テーブルの両方に追加のエントリがあり、JobExecution テーブルに 2 つの追加エントリがあるはずです。
JOB_INST_ID | JOB_NAME |
1 | EndOfDayJob |
2 | EndOfDayJob |
JOB_EXECUTION_ID | TYPE_CD | KEY_NAME | DATE_VAL | IDENTIFYING |
1 | DATE | schedule.Date | 2017-01-01 00:00:00 | TRUE |
2 | DATE | schedule.Date | 2017-01-01 00:00:00 | TRUE |
3 | DATE | schedule.Date | 2017-01-02 00:00:00 | TRUE |
JOB_EXEC_ID | JOB_INST_ID | START_TIME | END_TIME | STATUS |
1 | 1 | 2017-01-01 21:00 | 2017-01-01 21:30 | FAILED |
2 | 1 | 2017-01-02 21:00 | 2017-01-02 21:30 | COMPLETED |
3 | 2 | 2017-01-02 21:31 | 2017-01-02 22:29 | COMPLETED |
| 列名は、明確さとフォーマットのために省略または削除されている場合があります。 |
ステップ
Step は、バッチジョブの独立した順次フェーズをカプセル化するドメインオブジェクトです。すべての Job は 1 つ以上のステップから構成されます。Step には、実際のバッチ処理を定義および制御するために必要なすべての情報が含まれています。これは必然的に漠然とした説明になります。なぜなら、特定の Step の内容は Job を作成する開発者の裁量に委ねられるからです。Step は、開発者の要求に応じて単純にも複雑にもできます。単純な Step は、ファイルからデータベースにデータをロードし、コードはほとんどまたはまったく必要ありません (使用する実装によって異なります)。より複雑な Step では、処理の一部として適用される複雑なビジネスルールが存在する場合があります。Job と同様に、Step には、次の図に示すように、一意の JobExecution と相関する個別の StepExecution があります。

StepExecution
StepExecution は、Step を実行する 1 回の試行を表します。JobExecution と同様に、Step が実行されるたびに新しい StepExecution が作成されます。ただし、失敗する前のステップが原因でステップの実行が失敗した場合、その実行は持続しません。StepExecution は、その Step が実際に開始されたときにのみ作成されます。
Step 実行は、StepExecution クラスのオブジェクトによって表されます。各実行には、対応するステップと JobExecution への参照、およびコミットとロールバックの数、開始時間と終了時間などのトランザクション関連データが含まれます。さらに、各ステップの実行には ExecutionContext が含まれます。これには、再起動に必要な統計情報や状態情報など、開発者がバッチ実行全体で保持する必要があるデータが含まれます。次の表に、StepExecution のプロパティを示します。
プロパティ | 定義 |
| 実行のステータスを示す |
| 実行が開始された現在のシステム時刻を表す |
| 実行が成功したかどうかに関係なく、実行が完了した時点の現在のシステム時刻を表す |
| 実行結果を示す |
| 実行間で永続化する必要があるユーザーデータを含む「プロパティバッグ」。 |
| 正常に読み取られたアイテムの数。 |
| 正常に書き込まれたアイテムの数。 |
| この実行のためにコミットされたトランザクションの数。 |
|
|
|
|
|
|
|
|
|
|
ExecutionContext
ExecutionContext は、StepExecution オブジェクトまたは JobExecution オブジェクトにスコープされた永続状態を格納する場所を開発者に提供するために、フレームワークによって永続化および制御されるキーと値のペアのコレクションを表します。( Quartz に精通している方にとっては、JobDataMap と非常によく似ています) 最適な使用例は、再起動を容易にすることです。例としてフラットファイル入力を使用すると、個々の行を処理している間、フレームワークは定期的にコミットポイントで ExecutionContext を永続化します。そうすることで、実行中に致命的なエラーが発生した場合や電源が切れた場合でも、ItemReader はその状態を保存できます。次の例に示すように、必要なのは現在の行数をコンテキストに入れることだけで、あとはフレームワークが行います。
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());Job ステレオタイプセクションの EndOfDay の例を例として使用し、ファイルをデータベースにロードする loadData という 1 つのステップがあるとします。最初の失敗した実行の後、メタデータテーブルは次の例のようになります。
JOB_INST_ID | JOB_NAME |
1 | EndOfDayJob |
JOB_INST_ID | TYPE_CD | KEY_NAME | DATE_VAL |
1 | DATE | schedule.Date | 2017-01-01 |
JOB_EXEC_ID | JOB_INST_ID | START_TIME | END_TIME | STATUS |
1 | 1 | 2017-01-01 21:00 | 2017-01-01 21:30 | FAILED |
STEP_EXEC_ID | JOB_EXEC_ID | STEP_NAME | START_TIME | END_TIME | STATUS |
1 | 1 | loadData | 2017-01-01 21:00 | 2017-01-01 21:30 | FAILED |
STEP_EXEC_ID | SHORT_CONTEXT |
1 | {piece.count=40321} |
前のケースでは、Step は 30 分間実行され、このシナリオではファイル内の行を表す 40,321 の「断片」を処理しました。この値は、フレームワークによる各コミットの直前に更新され、ExecutionContext 内のエントリに対応する複数の行を含めることができます。コミット前に通知を受けるには、さまざまな StepListener 実装 (または ItemStream) のいずれかが必要です。これについては、このガイドの後半で詳しく説明します。前の例と同様に、Job は翌日再始動されると想定されています。再起動すると、最後の実行の ExecutionContext の値がデータベースから再構成されます。ItemReader が開かれると、次の例に示すように、コンテキストに格納された状態があるかどうかを確認し、そこから自身を初期化できます。
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
} この場合、前のコードが実行された後、現在の行は 40,322 であり、Step は中断したところから再開されます。ExecutionContext は、実行自体について永続化する必要がある統計に使用することもできます。例: フラットファイルに複数の行にわたって存在する処理のオーダーが含まれている場合、処理されたオーダーの数 (読み取られた行数とは大きく異なります) を保存する必要がある場合があります。本体で処理されたオーダーの総数を含む Step の末尾。フレームワークは、開発者のためにこれを保存して、個々の JobInstance で正しくスコープを設定します。既存の ExecutionContext を使用する必要があるかどうかを判断するのは非常に難しい場合があります。例: 上記の EndOfDay の例を使用すると、01-01 の実行が 2 回目に再び開始されると、フレームワークはそれが同じ JobInstance であり、個々の Step ベースであることを認識し、データベースから ExecutionContext を引き出し、それを (一部として) 渡します。StepExecution の) を Step 自体に接続します。逆に、01-02 の実行では、フレームワークはそれが別のインスタンスであることを認識するため、空のコンテキストを Step に渡す必要があります。適切なタイミングで状態が与えられるようにするために、フレームワークが開発者のために行うこれらの種類の決定の多くがあります。また、常に StepExecution ごとに 1 つの ExecutionContext が存在することに注意することも重要です。これにより共有キースペースが作成されるため、ExecutionContext のクライアントは注意が必要です。そのため、データが上書きされないように、値を入れるときは注意が必要です。ただし、Step はコンテキストにデータをまったく保存しないため、フレームワークに悪影響を与える方法はありません。
JobExecution ごとに少なくとも 1 つの ExecutionContext と StepExecution ごとに 1 つの ExecutionContext があることに注意してください。例: 次のコードスニペットを検討してください。
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob コメントで記述されていたように、ecStep は ecJob と等しくありません。それらは 2 つの異なる ExecutionContexts です。Step を対象とするものは Step のすべてのコミットポイントで保存されますが、ジョブを対象とするものは Step の実行のたびに保存されます。
ExecutionContext では、すべての非一時エントリは Serializable である必要があります。実行コンテキストの適切な直列化は、ステップとジョブの再起動機能を支えます。ネイティブに直列化できないキーまたは値を使用する場合は、カスタマイズされた直列化アプローチを採用する必要があります。実行コンテキストの直列化に失敗すると、状態の永続化プロセスが危険にさらされ、失敗したジョブを適切に回復できなくなる可能性があります。 |
JobRepository
JobRepository は、前述のすべてのステレオタイプの持続メカニズムです。JobLauncher、Job、Step 実装に CRUD 操作を提供します。Job が最初に起動されると、リポジトリから JobExecution が取得されます。また、実行の過程で、StepExecution および JobExecution の実装は、リポジトリに渡すことによって永続化されます。
Java
XML
Java 構成を使用する場合、@EnableBatchProcessing アノテーションは、自動的に構成されるコンポーネントの 1 つとして JobRepository を提供します。
次の例に示すように、Spring Batch XML 名前空間は、<job-repository> タグを使用して JobRepository インスタンスを構成するためのサポートを提供します。
<job-repository id="jobRepository"/>JobOperator
JobOperator は、次の例に示すように、ジョブの開始、停止、再開などの操作のためのシンプルなインターフェースを表します。
public interface JobOperator {
JobExecution start(Job job, JobParameters jobParameters) throws Exception;
JobExecution startNextInstance(Job job) throws Exception;
boolean stop(JobExecution jobExecution) throws Exception;
JobExecution restart(JobExecution jobExecution) throws Exception;
JobExecution abandon(JobExecution jobExecution) throws Exception;
}Job は、与えられた JobParameters のセットから開始されます。実装は、JobRepository から有効な JobExecution を取得し、Job を実行することが期待されます。
ItemReader
ItemReader は、Step の入力を一度に 1 つずつ取得することを表す抽象化です。ItemReader が提供できるアイテムを使い果たすと、null を返すことでこれを示します。ItemReader インターフェースとそのさまざまな実装の詳細については、リーダーとライターを参照してください。
ItemWriter
ItemWriter は、Step の出力、一度に 1 つのバッチまたはアイテムのチャンクを表す抽象化です。一般に、ItemWriter は、次に受信する必要がある入力を認識しておらず、現在の呼び出しで渡されたアイテムのみを認識しています。ItemWriter インターフェースとそのさまざまな実装の詳細については、リーダーとライターを参照してください。
ItemProcessor
ItemProcessor は、アイテムのビジネス処理を表す抽象化です。ItemReader は 1 つの項目を読み取り、ItemWriter は 1 つの項目を書き込みますが、ItemProcessor は他のビジネス処理を変換または適用するためのアクセスポイントを提供します。アイテムの処理中にアイテムが有効でないと判断された場合、null を返すと、アイテムを書き出す必要がないことが示されます。リーダーとライターで ItemProcessor インターフェースの詳細を確認できます。
バッチ名前空間
前述のドメイン概念の多くは、Spring ApplicationContext で構成する必要があります。標準の Bean 定義で使用できる上記のインターフェースの実装がありますが、次の例に示すように、構成を容易にするために名前空間が提供されています。
<beans:beans xmlns="http://www.springframework.org/schema/batch"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch
https://www.springframework.org/schema/batch/spring-batch.xsd">
<job id="ioSampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
</tasklet>
</step>
</job>
</beans:beans> バッチ名前空間が宣言されている限り、その要素はどれでも使用できます。ジョブの構成と実行でジョブの構成に関する詳細情報を見つけることができます。ステップの構成で Step の構成に関する詳細情報を見つけることができます。
| バッチ XML 名前空間は Spring Batch 6.0 以降非推奨となり、バージョン 7.0 で削除されます。 |

