データベース
ほとんどのエンタープライズアプリケーションスタイルと同様に、データベースはバッチの主要ストレージメカニズムです。ただし、システムが動作するデータセットのサイズが大きいため、バッチは他のアプリケーションスタイルとは異なります。SQL ステートメントが 100 万行を返す場合、結果セットはすべての行が読み取られるまで、返されたすべての結果をメモリに保持している可能性があります。Spring Batch は、この問題に対して 2 つの型のソリューションを提供します。
カーソルベースの ItemReader 実装
データベースカーソルを使用することは、リレーショナルデータの「ストリーミング」の問題に対するデータベースのソリューションであるため、ほとんどのバッチ開発者のデフォルトのアプローチです。Java ResultSet クラスは、本質的にはカーソルを操作するためのオブジェクト指向のメカニズムです。ResultSet は、現在のデータ行へのカーソルを維持します。ResultSet で next を呼び出すと、このカーソルが次の行に移動します。Spring Batch カーソルベースの ItemReader 実装は、初期化時にカーソルを開き、read の呼び出しごとにカーソルを 1 行前方に移動して、処理に使用できるマップされたオブジェクトを返します。次に、close メソッドが呼び出され、すべてのリソースが解放されます。Spring コア JdbcTemplate は、コールバックパターンを使用して ResultSet のすべての行を完全にマッピングし、メソッド呼び出し元に制御を戻す前に閉じることにより、この問題を回避します。ただし、バッチでは、ステップが完了するまで待機する必要があります。次のイメージは、カーソルベースの ItemReader がどのように機能するかの一般的な図を示しています。この例では SQL を使用していますが(SQL は広く知られているため)、どの技術でも基本的なアプローチを実装できます。

この例は、基本的なパターンを示しています。ID、NAME、BAR という 3 つの列を持つ "FOO" テーブルがある場合、ID が 1 より大きく 7 より小さいすべての行を選択します。これにより、カーソルの先頭(行 1)が ID2 に配置されます。完全にマップされた Foo オブジェクト。read() を再度呼び出すと、カーソルが次の行、つまり ID が 3 の Foo に移動します。これらの読み取りの結果は各 read の後に書き出され、オブジェクトをガベージコレクションできるようになります(インスタンス変数がオブジェクトへの参照を維持していない場合))。
JdbcCursorItemReader
JdbcCursorItemReader は、カーソルベースの手法の JDBC 実装です。ResultSet で直接動作し、DataSource から取得した接続に対して実行する SQL ステートメントが必要です。例として、次のデータベーススキーマを使用します。
CREATE TABLE CUSTOMER (
ID BIGINT IDENTITY PRIMARY KEY,
NAME VARCHAR(45),
CREDIT FLOAT
); 多くの人は各行にドメインオブジェクトを使用することを好むため、次の例では RowMapper インターフェースの実装を使用して CustomerCredit オブジェクトをマップします。
public class CustomerCreditRowMapper implements RowMapper<CustomerCredit> {
public static final String ID_COLUMN = "id";
public static final String NAME_COLUMN = "name";
public static final String CREDIT_COLUMN = "credit";
public CustomerCredit mapRow(ResultSet rs, int rowNum) throws SQLException {
CustomerCredit customerCredit = new CustomerCredit();
customerCredit.setId(rs.getInt(ID_COLUMN));
customerCredit.setName(rs.getString(NAME_COLUMN));
customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN));
return customerCredit;
}
}JdbcCursorItemReader は JdbcTemplate とキーインターフェースを共有するため、ItemReader と対比するために、JdbcTemplate でこのデータを読み込む方法の例を見ると便利です。この例では、CUSTOMER データベースに 1,000 行があると想定しています。最初の例では JdbcTemplate を使用しています。
//For simplicity sake, assume a dataSource has already been obtained
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER",
new CustomerCreditRowMapper()); 上記のコードスニペットを実行した後、customerCredits リストには 1,000 CustomerCredit オブジェクトが含まれます。クエリメソッドでは、DataSource から接続が取得され、指定された SQL が実行され、ResultSet の各行に対して mapRow メソッドが呼び出されます。これを、次の例に示す JdbcCursorItemReader のアプローチと比較してください。
JdbcCursorItemReader itemReader = new JdbcCursorItemReader();
itemReader.setDataSource(dataSource);
itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER");
itemReader.setRowMapper(new CustomerCreditRowMapper());
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close(); 上記のコードスニペットを実行した後、カウンターは 1,000 に等しくなります。上記のコードが返された customerCredit をリストに入れていた場合、結果は JdbcTemplate の例とまったく同じになります。ただし、ItemReader の大きな利点は、アイテムを「ストリーミング」できることです。read メソッドは 1 回呼び出すことができ、アイテムは ItemWriter によって書き出され、次のアイテムは read で取得できます。これにより、アイテムの読み取りと書き込みを「チャンク」で実行し、定期的にコミットすることができます。これは、高性能バッチ処理の本質です。さらに、Spring Batch Step への注入用に簡単に構成できます。
Java
XML
次の例は、Java で ItemReader を Step に注入する方法を示しています。
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
} 次の例は、XML で ItemReader を Step に挿入する方法を示しています。
<bean id="itemReader" class="org.spr...JdbcCursorItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="sql" value="select ID, NAME, CREDIT from CUSTOMER"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>追加プロパティ
Java でカーソルを開くための非常に多くのさまざまなオプションがあるため、次の表で説明するように、設定できる JdbcCursorItemReader には多くのプロパティがあります。
ignoreWarnings | SQLWarnings がログに記録されるか、例外を引き起こすかどうかを決定します。デフォルトは |
fetchSize |
|
maxRows | 基になる |
queryTimeout | ドライバーが |
verifyCursorPosition |
|
saveState | リーダーの状態を |
driverSupportsAbsolute | JDBC ドライバーが |
setUseSharedExtendedConnection | カーソルに使用される接続を他のすべての処理で使用する必要があるかどうかを示します。同じトランザクションを共有します。これが |
StoredProcedureItemReader
場合によっては、ストアドプロシージャを使用してカーソルデータを取得する必要があります。StoredProcedureItemReader は JdbcCursorItemReader と同様に機能しますが、カーソルを取得するクエリを実行する代わりに、カーソルを返すストアドプロシージャを実行します。ストアドプロシージャは、3 つの異なる方法でカーソルを返すことができます。
返される
ResultSet(SQL Server、Sybase、DB2、Derby、MySQL で使用)。出力パラメーターとして返される ref-cursor として(Oracle および PostgreSQL で使用)。
ストアド関数呼び出しの戻り値。
Java
XML
次の Java の設定例では、前の例と同じ「顧客クレジット」の例を使用しています。
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
return reader;
}次の XML の設定例では、前の例と同じ「顧客クレジット」の例を使用しています。
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean> 上記の例では、ストアドプロシージャを使用して、返される結果として ResultSet を提供しています(以前のオプション 1)。
ストアドプロシージャが ref-cursor (オプション 2)を返した場合、返された ref-cursor である out パラメーターの位置を指定する必要があります。
Java
XML
次の例は、Java で最初のパラメーターが ref-cursor である場合の操作方法を示しています。
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setRefCursorPosition(1);
return reader;
}次の例は、XML の ref-cursor である最初のパラメーターを操作する方法を示しています。
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean> ストアド関数(オプション 3)からカーソルが返された場合は、プロパティ "function" を true に設定する必要があります。デフォルトは false です。
Java
XML
次の例は、Java での true のプロパティを示しています。
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setFunction(true);
return reader;
} 次の例は、XML で true のプロパティを示しています。
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="function" value="true"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean> これらのすべてのケースで、RowMapper、DataSource、実際のプロシージャ名を定義する必要があります。
ストアドプロシージャまたは関数がパラメーターを受け取る場合は、parameters プロパティを使用して宣言および設定する必要があります。次の例では、Oracle の場合、3 つのパラメーターを宣言します。1 つ目は ref-cursor を返す out パラメーターであり、2 つ目と 3 つ目は型 INTEGER の値をとるパラメーターです。
Java
XML
次の例は、Java でパラメーターを操作する方法を示しています。
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
List<SqlParameter> parameters = new ArrayList<>();
parameters.add(new SqlOutParameter("newId", OracleTypes.CURSOR));
parameters.add(new SqlParameter("amount", Types.INTEGER);
parameters.add(new SqlParameter("custId", Types.INTEGER);
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("spring.cursor_func");
reader.setParameters(parameters);
reader.setRefCursorPosition(1);
reader.setRowMapper(rowMapper());
reader.setPreparedStatementSetter(parameterSetter());
return reader;
}次の例は、XML でパラメーターを操作する方法を示しています。
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="spring.cursor_func"/>
<property name="parameters">
<list>
<bean class="org.springframework.jdbc.core.SqlOutParameter">
<constructor-arg index="0" value="newid"/>
<constructor-arg index="1">
<util:constant static-field="oracle.jdbc.OracleTypes.CURSOR"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="amount"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="custid"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
</list>
</property>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper" ref="rowMapper"/>
<property name="preparedStatementSetter" ref="parameterSetter"/>
</bean> パラメーター宣言に加えて、呼び出しのパラメーター値を設定する PreparedStatementSetter 実装を指定する必要があります。これは、上記の JdbcCursorItemReader と同じように機能します。追加プロパティにリストされている追加プロパティはすべて、StoredProcedureItemReader にも適用されます。
ItemReader 実装のページング
データベースカーソルを使用する代わりに、各クエリが結果の一部をフェッチする複数のクエリを実行します。このパートをページと呼びます。各クエリでは、ページで返される開始行番号と行数を指定する必要があります。
JdbcPagingItemReader
ページング ItemReader の実装の 1 つは JdbcPagingItemReader です。JdbcPagingItemReader には、ページを構成する行を取得するために使用される SQL クエリを提供する PagingQueryProvider が必要です。各データベースにはページングサポートを提供する独自の戦略があるため、サポートされるデータベース型ごとに異なる PagingQueryProvider を使用する必要があります。使用されているデータベースを自動検出し、適切な PagingQueryProvider 実装を決定する SqlPagingQueryProviderFactoryBean もあります。これにより、構成が簡素化され、推奨されるベストプラクティスです。
SqlPagingQueryProviderFactoryBean では、select 節と from 節を指定する必要があります。オプションの where 句を指定することもできます。これらの句と必要な sortKey は、SQL ステートメントの構築に使用されます。
実行間でデータが失われないことを保証するために、sortKey に一意のキー制約を設定することが重要です。 |
リーダーが開かれた後、他の ItemReader と同じ基本的な方法で、read への呼び出しごとに 1 つのアイテムを返します。追加の行が必要な場合、ページングはバックグラウンドで発生します。
Java
XML
次の Java の設定例では、前に示したカーソルベースの ItemReader と同様の「顧客クレジット」の例を使用しています。
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
} 次の XML の構成例では、前に示したカーソルベースの ItemReader と同様の「顧客クレジット」の例を使用しています。
<bean id="itemReader" class="org.spr...JdbcPagingItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="queryProvider">
<bean class="org.spr...SqlPagingQueryProviderFactoryBean">
<property name="selectClause" value="select id, name, credit"/>
<property name="fromClause" value="from customer"/>
<property name="whereClause" value="where status=:status"/>
<property name="sortKey" value="id"/>
</bean>
</property>
<property name="parameterValues">
<map>
<entry key="status" value="NEW"/>
</map>
</property>
<property name="pageSize" value="1000"/>
<property name="rowMapper" ref="customerMapper"/>
</bean> この構成された ItemReader は、指定する必要がある RowMapper を使用して CustomerCredit オブジェクトを返します。'pageSize' プロパティは、クエリの実行ごとにデータベースから読み取られるエンティティの数を決定します。
'parameterValues' プロパティは、クエリのパラメーター値の Map を指定するために使用できます。where 句で名前付きパラメーターを使用する場合、各エントリのキーは、名前付きパラメーターの名前と一致する必要があります。従来の '?' プレースホルダを使用する場合、各エントリのキーは、1 から始まるプレースホルダの番号である必要があります。
JpaPagingItemReader
ページング ItemReader の別の実装は JpaPagingItemReader です。JPA には Hibernate StatelessSession に似た概念がないため、JPA 仕様で提供される他の機能を使用する必要があります。JPA はページングをサポートしているため、バッチ処理に JPA を使用する場合、これは当然の選択です。各ページが読み取られると、エンティティが切り離され、永続コンテキストがクリアされて、ページが処理されるとエンティティをガベージコレクションできるようになります。
JpaPagingItemReader を使用すると、JPQL ステートメントを宣言し、EntityManagerFactory を渡すことができます。次に、呼び出しごとに 1 つのアイテムを返し、他の ItemReader と同じ基本的な方法で読み取ります。追加のエンティティが必要な場合、ページングはバックグラウンドで行われます。
Java
XML
次の Java の設定例では、前に示した JDBC リーダーと同じ "customercredit" の例を使用しています。
@Bean
public JpaPagingItemReader itemReader() {
return new JpaPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.entityManagerFactory(entityManagerFactory())
.queryString("select c from CustomerCredit c")
.pageSize(1000)
.build();
}次の XML の設定例では、前に示した JDBC リーダーと同じ "customercredit" の例を使用しています。
<bean id="itemReader" class="org.spr...JpaPagingItemReader">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="queryString" value="select c from CustomerCredit c"/>
<property name="pageSize" value="1000"/>
</bean> この構成された ItemReader は、CustomerCredit オブジェクトに正しい JPA アノテーションまたは ORM マッピングファイルがあると仮定して、上記の JdbcPagingItemReader で説明したのとまったく同じ方法で CustomerCredit オブジェクトを返します。'pageSize' プロパティは、クエリ実行ごとにデータベースから読み取られるエンティティの数を決定します。
データベース ItemWriter
フラットファイルと XML ファイルの両方に特定の ItemWriter インスタンスがありますが、データベースの世界にはまったく同じものはありません。これは、トランザクションが必要な機能をすべて提供するためです。ItemWriter の実装は、トランザクションのように動作し、書かれたアイテムを追跡し、適切なタイミングでフラッシュまたはクリアする必要があるため、ファイルに必要です。書き込みはすでにトランザクションに含まれているため、データベースにはこの機能は必要ありません。ユーザーは、ItemWriter インターフェースを実装する独自の DAO を作成するか、一般的な処理の課題のために作成されたカスタム ItemWriter の DAO を使用できます。いずれにしても、課題なく機能するはずです。注意すべきことの 1 つは、出力のバッチ処理によって提供されるパフォーマンスとエラー処理機能です。これは、ItemWriter として休止状態を使用する場合に最も一般的ですが、JDBC バッチモードを使用する場合にも同じ問題が発生する可能性があります。データベース出力のバッチ処理に固有の欠陥はありません。フラッシュに注意し、データにエラーがないことを前提としています。ただし、次の図に示すように、個々のアイテムが例外を引き起こしたかどうか、個々のアイテムが原因であるかどうかを知る方法がないため、書き込み中のエラーは混乱を招く可能性があります。

項目が書き込まれる前にバッファリングされる場合、コミットの直前にバッファがフラッシュされるまでエラーはスローされません。例: 20 個のアイテムがチャンクごとに書き込まれ、15 番目のアイテムが DataIntegrityViolationException をスローすると仮定します。Step に関する限り、エラーが実際に書き込まれるまでエラーが発生したことを知る方法がないため、20 個のアイテムはすべて正常に書き込まれます。Session#flush() が呼び出されると、バッファーが空になり、例外がヒットします。こでは、Step でできることは何もありません。トランザクションをロールバックする必要があります。通常、この例外によりアイテムがスキップされる可能性があり(スキップ / 再試行ポリシーに応じて)、再度書き込まれることはありません。ただし、バッチシナリオでは、どのアイテムが課題を引き起こしたかを知る方法はありません。障害が発生したときにバッファ全体が書き込まれていました。この課題を解決する唯一の方法は、次の図に示すように、各アイテムの後にフラッシュすることです。
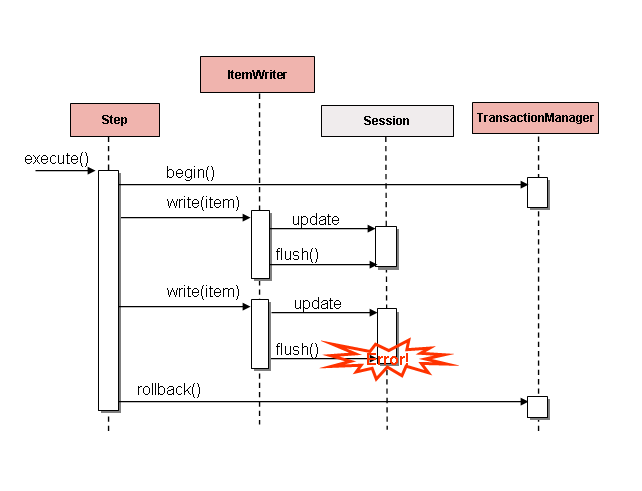
これは、特に Hibernate を使用する場合の一般的な使用例であり、ItemWriter の実装の簡単なガイドラインは、write() への各呼び出しでフラッシュすることです。そうすることで、Spring Batch がエラー後の ItemWriter への呼び出しの粒度を内部的に管理して、アイテムを確実にスキップすることができます。

