一般的なバッチパターン
一部のバッチジョブは、Spring Batch の既製のコンポーネントから純粋に組み立てることができます。たとえば、ItemReader および ItemWriter 実装は、さまざまなシナリオをカバーするように構成できます。ただし、ほとんどの場合、カスタムコードを記述する必要があります。アプリケーション開発者向けの主要な API エントリポイントは、Tasklet、ItemReader、ItemWriter、さまざまなリスナーインターフェースです。ほとんどの単純なバッチジョブでは、Spring Batch ItemReader からの既製の入力を使用できますが、開発者が ItemWriter または ItemProcessor を実装する必要がある処理および記述にカスタムの懸念がある場合がよくあります。
この章では、カスタムビジネスロジックの一般的なパターンの例をいくつか示します。これらの例は、主にリスナーインターフェースを特徴としています。ItemReader または ItemWriter は、必要に応じてリスナーインターフェースも実装できることに注意してください。
アイテムの処理と失敗のログ
一般的な使用例は、ステップごとのエラーをアイテムごとに特別に処理する必要があることです。おそらく、特別なチャネルにログを記録するか、データベースにレコードを挿入します。チャンク指向の Step (ステップファクトリ Bean から作成)を使用すると、ユーザーは read のエラー用の単純な ItemReadListener と write のエラー用の ItemWriteListener を使用してこのユースケースを実装できます。次のコードスニペットは、読み取りと書き込みの両方の失敗を記録するリスナーを示しています。
public class ItemFailureLoggerListener extends ItemListenerSupport {
private static Log logger = LogFactory.getLog("item.error");
public void onReadError(Exception ex) {
logger.error("Encountered error on read", e);
}
public void onWriteError(Exception ex, List<? extends Object> items) {
logger.error("Encountered error on write", ex);
}
}このリスナーを実装したら、ステップに登録する必要があります。
Java
XML
次の例は、リスナーをステップ Java に登録する方法を示しています。
@Bean
public Step simpleStep(JobRepository jobRepository) {
return new StepBuilder("simpleStep", jobRepository)
...
.listener(new ItemFailureLoggerListener())
.build();
}次の例は、XML のステップにリスナーを登録する方法を示しています。
<step id="simpleStep">
...
<listeners>
<listener>
<bean class="org.example...ItemFailureLoggerListener"/>
</listener>
</listeners>
</step> リスナーが onError() メソッドで何かを行う場合、ロールバックされるトランザクション内になければなりません。onError() メソッド内でデータベースなどのトランザクションリソースを使用する必要がある場合は、そのメソッドに宣言トランザクションを追加し(詳細については Spring コアリファレンスガイドを参照)、その伝播属性に REQUIRES_NEW の値を与えることを検討してください。 |
ビジネス上の理由でジョブを手動で停止する
Spring Batch は JobOperator インターフェースを介して stop() メソッドを提供しますが、これは実際にはアプリケーションプログラマーではなくオペレーターが使用するためのものです。場合によっては、ビジネスロジック内からジョブの実行を停止する方が便利な場合や意味がある場合があります。
最も簡単なことは、RuntimeException (無期限に再試行もスキップもされないもの)をスローすることです。例: 次の例に示すように、カスタム例外型を使用できます。
public class PoisonPillItemProcessor<T> implements ItemProcessor<T, T> {
@Override
public T process(T item) throws Exception {
if (isPoisonPill(item)) {
throw new PoisonPillException("Poison pill detected: " + item);
}
return item;
}
} 次の例に示すように、ステップの実行を停止するもう 1 つの簡単な方法は、ItemReader から null を返すことです。
public class EarlyCompletionItemReader implements ItemReader<T> {
private ItemReader<T> delegate;
public void setDelegate(ItemReader<T> delegate) { ... }
public T read() throws Exception {
T item = delegate.read();
if (isEndItem(item)) {
return null; // end the step here
}
return item;
}
} 前の例は、処理されるアイテムが null である場合にバッチ全体を通知する CompletionPolicy 戦略のデフォルト実装があるという事実に実際に依存しています。より洗練された完了ポリシーを実装し、SimpleStepFactoryBean を介して Step に挿入できます。
Java
XML
次の例は、Java のステップに完了ポリシーを挿入する方法を示しています。
@Bean
public Step simpleStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("simpleStep", jobRepository)
.<String, String>chunk(new SpecialCompletionPolicy(), transactionManager)
.reader(reader())
.writer(writer())
.build();
}次の例は、XML のステップに完了ポリシーを挿入する方法を示しています。
<step id="simpleStep">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="10"
chunk-completion-policy="completionPolicy"/>
</tasklet>
</step>
<bean id="completionPolicy" class="org.example...SpecialCompletionPolicy"/> 代替方法は、StepExecution にフラグを設定することです。これは、アイテム処理の間にフレームワークの Step 実装によってチェックされます。この代替を実装するには、現在の StepExecution にアクセスする必要があり、これは StepListener を実装して Step に登録することで実現できます。次の例は、フラグを設定するリスナーを示しています。
public class CustomItemWriter extends ItemListenerSupport implements StepListener {
private StepExecution stepExecution;
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
public void afterRead(Object item) {
if (isPoisonPill(item)) {
stepExecution.setTerminateOnly();
}
}
} フラグが設定されている場合、デフォルトの動作では、ステップが JobInterruptedException をスローします。この動作は、StepInterruptionPolicy を介して制御できます。ただし、唯一の選択肢は例外をスローするかしないかであるため、これは常にジョブの異常終了です。
フッターレコードを追加する
多くの場合、フラットファイルに書き込む場合、すべての処理が完了した後、「フッター」レコードをファイルの最後に追加する必要があります。これは、Spring Batch が提供する FlatFileFooterCallback インターフェースを使用して実現できます。FlatFileFooterCallback (およびそ版である FlatFileHeaderCallback)は FlatFileItemWriter のオプションのプロパティであり、アイテムライターに追加できます。
Java
XML
次の例は、Java で FlatFileHeaderCallback および FlatFileFooterCallback を使用する方法を示しています。
@Bean
public FlatFileItemWriter<String> itemWriter(Resource outputResource) {
return new FlatFileItemWriterBuilder<String>()
.name("itemWriter")
.resource(outputResource)
.lineAggregator(lineAggregator())
.headerCallback(headerCallback())
.footerCallback(footerCallback())
.build();
} 次の例は、XML で FlatFileHeaderCallback および FlatFileFooterCallback を使用する方法を示しています。
<bean id="itemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator" ref="lineAggregator"/>
<property name="headerCallback" ref="headerCallback" />
<property name="footerCallback" ref="footerCallback" />
</bean>フッターコールバックインターフェースには、次のインターフェース定義に示すように、フッターを記述する必要があるときに呼び出されるメソッドが 1 つだけあります。
public interface FlatFileFooterCallback {
void writeFooter(Writer writer) throws IOException;
}サマリーフッターの作成
フッターレコードに関連する一般的な要件は、出力プロセス中に情報を集約し、この情報をファイルの最後に追加することです。このフッターは、多くの場合、ファイルの要約として機能するか、チェックサムを提供します。
例: バッチジョブが Trade レコードをフラットファイルに書き込み、すべての Trades からの合計金額をフッターに配置する必要がある場合、次の ItemWriter 実装を使用できます。
public class TradeItemWriter implements ItemWriter<Trade>,
FlatFileFooterCallback {
private ItemWriter<Trade> delegate;
private BigDecimal totalAmount = BigDecimal.ZERO;
public void write(Chunk<? extends Trade> items) throws Exception {
BigDecimal chunkTotal = BigDecimal.ZERO;
for (Trade trade : items) {
chunkTotal = chunkTotal.add(trade.getAmount());
}
delegate.write(items);
// After successfully writing all items
totalAmount = totalAmount.add(chunkTotal);
}
public void writeFooter(Writer writer) throws IOException {
writer.write("Total Amount Processed: " + totalAmount);
}
public void setDelegate(ItemWriter delegate) {...}
} この TradeItemWriter は、書き込まれた各 Trade 項目から amount とともに増加する totalAmount 値を保管します。最後の Trade が処理された後、フレームワークは writeFooter を呼び出し、totalAmount をファイルに入れます。write メソッドは、チャンクに Trade の合計量を格納する一時変数 chunkTotal を使用することに注意してください。これは、write メソッドでスキップが発生した場合に、totalAmount が変更されないようにするために行われます。write メソッドの最後にのみ、例外がスローされないことが保証されたら、totalAmount を更新します。
writeFooter メソッドを呼び出すには、TradeItemWriter (FlatFileFooterCallback を実装)を footerCallback として FlatFileItemWriter に接続する必要があります。
Java
XML
次の例は、Java で TradeItemWriter をワイヤリングする方法を示しています。
@Bean
public TradeItemWriter tradeItemWriter() {
TradeItemWriter itemWriter = new TradeItemWriter();
itemWriter.setDelegate(flatFileItemWriter(null));
return itemWriter;
}
@Bean
public FlatFileItemWriter<String> flatFileItemWriter(Resource outputResource) {
return new FlatFileItemWriterBuilder<String>()
.name("itemWriter")
.resource(outputResource)
.lineAggregator(lineAggregator())
.footerCallback(tradeItemWriter())
.build();
} 次の例は、TradeItemWriter を XML でワイヤリングする方法を示しています。
<bean id="tradeItemWriter" class="..TradeItemWriter">
<property name="delegate" ref="flatFileItemWriter" />
</bean>
<bean id="flatFileItemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator" ref="lineAggregator"/>
<property name="footerCallback" ref="tradeItemWriter" />
</bean>TradeItemWriter のこれまでの記述方法は、Step が再始動可能でない場合にのみ正しく機能します。これは、クラスがステートフル(totalAmount を格納するため)であるが、totalAmount はデータベースに永続化されないためです。再起動のイベントでは取得できません。このクラスを再起動可能にするには、次の例に示すように、ItemStream インターフェースをメソッド open および update とともに実装する必要があります。
public void open(ExecutionContext executionContext) {
if (executionContext.containsKey("total.amount") {
totalAmount = (BigDecimal) executionContext.get("total.amount");
}
}
public void update(ExecutionContext executionContext) {
executionContext.put("total.amount", totalAmount);
}update メソッドは、オブジェクトがデータベースに永続化される直前に、totalAmount の最新バージョンを ExecutionContext に保存します。open メソッドは、既存の totalAmount を ExecutionContext から取得し、それを処理の開始点として使用して、TradeItemWriter が再始動時に Step が実行された前回の中断から再開できるようにします。
クエリベースの ItemReader の駆動
リーダーとライターに関する章では、ページングを使用したデータベース入力について説明しました。DB2 などの多くのデータベースベンダーは、読み取り中のテーブルをオンラインアプリケーションの他の部分でも使用する必要がある場合に課題を引き起こす可能性がある非常に悲観的なロック戦略を持っています。さらに、非常に大きなデータセット上でカーソルを開くと、特定のベンダーのデータベースで問題が発生する可能性があります。多くのプロジェクトでは、データの読み取りに「駆動クエリ」アプローチを使用することを好みます。このアプローチは、次の図に示すように、返される必要のあるオブジェクト全体ではなく、キーを反復処理することで機能します。
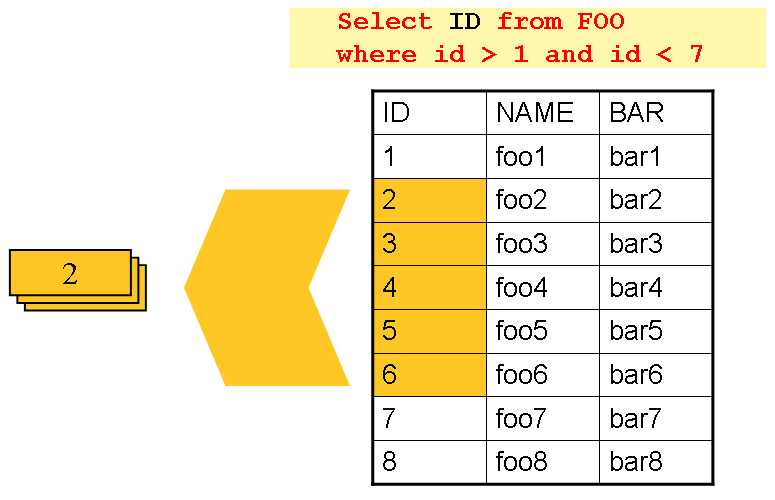
ご覧のとおり、前のイメージに示されている例では、カーソルベースの例で使用されたものと同じ 'FOO' テーブルが使用されています。ただし、行全体を選択するのではなく、SQL ステートメントで ID のみが選択されました。FOO オブジェクトが read から返されるのではなく、Integer が返されます。この番号は、次のイメージに示すように、完全な Foo オブジェクトである「詳細」の照会に使用できます。

ItemProcessor を使用して、駆動クエリから取得したキーを完全な Foo オブジェクトに変換する必要があります。既存の DAO を使用して、キーに基づいてオブジェクト全体を照会できます。
複数行レコード
通常、フラットファイルの場合、各レコードは 1 行に限定されますが、ファイルには複数の形式の複数の行にわたるレコードが含まれることがよくあります。ファイルからの次の抜粋は、そのような配置の例を示しています。
HEA;0013100345;2007-02-15 NCU;Smith;Peter;;T;20014539;F BAD;;Oak Street 31/A;;Small Town;00235;IL;US FOT;2;2;267.34
"HEA" で始まる行と "FOT" で始まる行の間のすべてが 1 つのレコードと見なされます。この状況を正しく処理するには、いくつかの考慮事項があります。
ItemReaderは、一度に 1 つのレコードを読み取る代わりに、複数行レコードのすべての行をグループとして読み取って、ItemWriterにそのまま渡すことができるようにする必要があります。各回線型は、異なるトークン化が必要になる場合があります。
1 つのレコードが複数の行にまたがっており、行数がわからない場合があるため、ItemReader は常にレコード全体を読み取るように注意する必要があります。これを行うには、カスタム ItemReader を FlatFileItemReader のラッパーとして実装する必要があります。
Java
XML
次の例は、Java でカスタム ItemReader を実装する方法を示しています。
@Bean
public MultiLineTradeItemReader itemReader() {
MultiLineTradeItemReader itemReader = new MultiLineTradeItemReader();
itemReader.setDelegate(flatFileItemReader());
return itemReader;
}
@Bean
public FlatFileItemReader flatFileItemReader() {
FlatFileItemReader<Trade> reader = new FlatFileItemReaderBuilder<>()
.name("flatFileItemReader")
.resource(new ClassPathResource("data/iosample/input/multiLine.txt"))
.lineTokenizer(orderFileTokenizer())
.fieldSetMapper(orderFieldSetMapper())
.build();
return reader;
} 次の例は、カスタム ItemReader を XML で実装する方法を示しています。
<bean id="itemReader" class="org.spr...MultiLineTradeItemReader">
<property name="delegate">
<bean class="org.springframework.batch.infrastructure.item.file.FlatFileItemReader">
<property name="resource" value="data/iosample/input/multiLine.txt" />
<property name="lineMapper">
<bean class="org.spr...DefaultLineMapper">
<property name="lineTokenizer" ref="orderFileTokenizer"/>
<property name="fieldSetMapper" ref="orderFieldSetMapper"/>
</bean>
</property>
</bean>
</property>
</bean> 各行が適切にトークン化されることを保証するために、固定長入力では特に重要ですが、デリゲート FlatFileItemReader で PatternMatchingCompositeLineTokenizer を使用できます。詳細については、リーダーとライターの章の FlatFileItemReader を参照してください。次に、デリゲートリーダーは PassThroughFieldSetMapper を使用して、各行の FieldSet を折り返し ItemReader に戻します。
Java
XML
次の例は、Java で各行が適切にトークン化されるようにする方法を示しています。
@Bean
public PatternMatchingCompositeLineTokenizer orderFileTokenizer() {
PatternMatchingCompositeLineTokenizer tokenizer =
new PatternMatchingCompositeLineTokenizer();
Map<String, LineTokenizer> tokenizers = new HashMap<>(4);
tokenizers.put("HEA*", headerRecordTokenizer());
tokenizers.put("FOT*", footerRecordTokenizer());
tokenizers.put("NCU*", customerLineTokenizer());
tokenizers.put("BAD*", billingAddressLineTokenizer());
tokenizer.setTokenizers(tokenizers);
return tokenizer;
}次の例は、各行が XML で適切にトークン化されていることを確認する方法を示しています。
<bean id="orderFileTokenizer" class="org.spr...PatternMatchingCompositeLineTokenizer">
<property name="tokenizers">
<map>
<entry key="HEA*" value-ref="headerRecordTokenizer" />
<entry key="FOT*" value-ref="footerRecordTokenizer" />
<entry key="NCU*" value-ref="customerLineTokenizer" />
<entry key="BAD*" value-ref="billingAddressLineTokenizer" />
</map>
</property>
</bean> このラッパーは、レコードの終わりを認識できる必要があります。これにより、最後に到達するまで、デリゲートで read() を継続的に呼び出すことができます。読み取られる行ごとに、ラッパーは返されるアイテムを構築する必要があります。フッターに到達すると、次の例に示すように、アイテムを ItemProcessor および ItemWriter に配信するために返すことができます。
private FlatFileItemReader<FieldSet> delegate;
public Trade read() throws Exception {
Trade t = null;
for (FieldSet line = null; (line = this.delegate.read()) != null;) {
String prefix = line.readString(0);
if (prefix.equals("HEA")) {
t = new Trade(); // Record must start with header
}
else if (prefix.equals("NCU")) {
Assert.notNull(t, "No header was found.");
t.setLast(line.readString(1));
t.setFirst(line.readString(2));
...
}
else if (prefix.equals("BAD")) {
Assert.notNull(t, "No header was found.");
t.setCity(line.readString(4));
t.setState(line.readString(6));
...
}
else if (prefix.equals("FOT")) {
return t; // Record must end with footer
}
}
Assert.isNull(t, "No 'END' was found.");
return null;
}システムコマンドの実行
多くのバッチジョブでは、バッチジョブ内から外部コマンドを呼び出す必要があります。このようなプロセスは、スケジューラによって個別に開始できますが、実行に関する一般的なメタデータの利点は失われます。さらに、マルチステップジョブも複数のジョブに分割する必要があります。
必要性が非常に一般的であるため、Spring Batch はシステムコマンドを呼び出すための Tasklet 実装を提供します。
Java
XML
次の例は、Java で外部コマンドを呼び出す方法を示しています。
@Bean
public SystemCommandTasklet tasklet() {
SystemCommandTasklet tasklet = new SystemCommandTasklet();
tasklet.setCommand("echo hello");
tasklet.setTimeout(5000);
return tasklet;
}次の例は、XML で外部コマンドを呼び出す方法を示しています。
<bean class="org.springframework.batch.core.step.tasklet.SystemCommandTasklet">
<property name="command" value="echo hello" />
<!-- 5 second timeout for the command to complete -->
<property name="timeout" value="5000" />
</bean>入力が見つからない場合のステップ完了の処理
多くのバッチシナリオでは、データベースまたはファイル内で処理する行が見つからないことは例外ではありません。Step は、単に作業が見つからなかったと見なされ、0 項目の読み取りで完了します。Spring Batch でデフォルトで提供される ItemReader 実装はすべて、このアプローチがデフォルトです。これは、入力が存在する場合でも何も書き出されない場合、混乱を招く可能性があります(通常、ファイルの名前が間違っているか、同様の問題が発生した場合に起こります)。このため、フレームワークが処理されていることがわかった作業量を判断するために、メタデータ自体をインスペクションする必要があります。ただし、入力がないことが例外と見なされた場合はどうなるでしょうか? この場合、メタデータをプログラムで処理してアイテムが処理されておらず、失敗の原因になっていないかをプログラムで確認することが最善のソリューションです。これは一般的な使用例であるため、Spring Batch は、NoWorkFoundStepExecutionListener のクラス定義に示されているように、リスナーにまさにこの機能を提供します。
public class NoWorkFoundStepExecutionListener implements StepExecutionListener {
public ExitStatus afterStep(StepExecution stepExecution) {
if (stepExecution.getReadCount() == 0) {
return ExitStatus.FAILED;
}
return null;
}
} 先行する StepExecutionListener は、'afterStep' フェーズ中に StepExecution の readCount プロパティをインスペクションして、読み取られた項目がないかどうかを判断します。読み取られた項目がない場合、終了コード FAILED が返され、Step が失敗することを示します。それ以外の場合は、null が返されますが、これは Step の状態には影響しません。
データを将来のステップに渡す
多くの場合、あるステップから別のステップに情報を渡すと便利です。これは、ExecutionContext を介して実行できます。キャッチは、2 つの ExecutionContexts があることです。1 つは Step レベルで、もう 1 つは Job レベルです。Step ExecutionContext はステップの間だけ残りますが、Job ExecutionContext は Job 全体を通して残ります。一方、Step ExecutionContext は、Step がチャンクをコミットするたびに更新されますが、Job ExecutionContext は、各 Step の最後でのみ更新されます。
この分離の結果、Step の実行中に、すべてのデータを Step ExecutionContext に配置する必要があります。そうすることで、Step の実行中にデータが適切に保存されるようになります。データが Job ExecutionContext に保存されている場合、そのデータは Step の実行中に保持されません。Step に障害が発生すると、そのデータは失われます。
public class SavingItemWriter implements ItemWriter<Object> {
private StepExecution stepExecution;
public void write(Chunk<? extends Object> items) throws Exception {
// ...
ExecutionContext stepContext = this.stepExecution.getExecutionContext();
stepContext.put("someKey", someObject);
}
@BeforeStep
public void saveStepExecution(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
} データを将来の Steps で利用できるようにするには、ステップが終了した後、データを Job ExecutionContext に「プロモート」する必要があります。Spring Batch は、この目的のために ExecutionContextPromotionListener を提供します。リスナーは、プロモートする必要がある ExecutionContext のデータに関連するキーを使用して構成する必要があります。オプションで、プロモーションを実行する必要のある終了コードパターンのリストを使用して構成することもできます(COMPLETED がデフォルトです)。すべてのリスナーと同様に、Step に登録する必要があります。
Java
XML
次の例は、Java で Job ExecutionContext へのステップをプロモートする方法を示しています。
@Bean
public Job job1(JobRepository jobRepository, Step step1, Step step2) {
return new JobBuilder("job1", jobRepository)
.start(step1)
.next(step2)
.build();
}
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.<String, String>chunk(10).transactionManager(transactionManager)
.reader(reader())
.writer(savingWriter())
.listener(promotionListener())
.build();
}
@Bean
public ExecutionContextPromotionListener promotionListener() {
ExecutionContextPromotionListener listener = new ExecutionContextPromotionListener();
listener.setKeys(new String[] {"someKey"});
return listener;
} 次の例は、XML で Job ExecutionContext へのステップをプロモートする方法を示しています。
<job id="job1">
<step id="step1">
<tasklet>
<chunk reader="reader" writer="savingWriter" commit-interval="10"/>
</tasklet>
<listeners>
<listener ref="promotionListener"/>
</listeners>
</step>
<step id="step2">
...
</step>
</job>
<beans:bean id="promotionListener" class="org.spr....ExecutionContextPromotionListener">
<beans:property name="keys">
<list>
<value>someKey</value>
</list>
</beans:property>
</beans:bean> 最後に、次の例に示すように、保存された値を Job ExecutionContext から取得する必要があります。
public class RetrievingItemWriter implements ItemWriter<Object> {
private Object someObject;
public void write(Chunk<? extends Object> items) throws Exception {
// ...
}
@BeforeStep
public void retrieveInterstepData(StepExecution stepExecution) {
JobExecution jobExecution = stepExecution.getJobExecution();
ExecutionContext jobContext = jobExecution.getExecutionContext();
this.someObject = jobContext.get("someKey");
}
}
