NVIDIA チャット
NVIDIA LLM API (英語) は、さまざまなプロバイダー (英語) の幅広いモデルを提供するプロキシ AI 推論エンジンです。
Spring AI は、既存の OpenAI クライアントを再利用して NVIDIA LLM API と統合します。そのためには、ベース URL を https://integrate.api.nvidia.com に設定し、提供されている LLM モデル (英語) の 1 つを選択して、それに対する api-key を取得する必要があります。
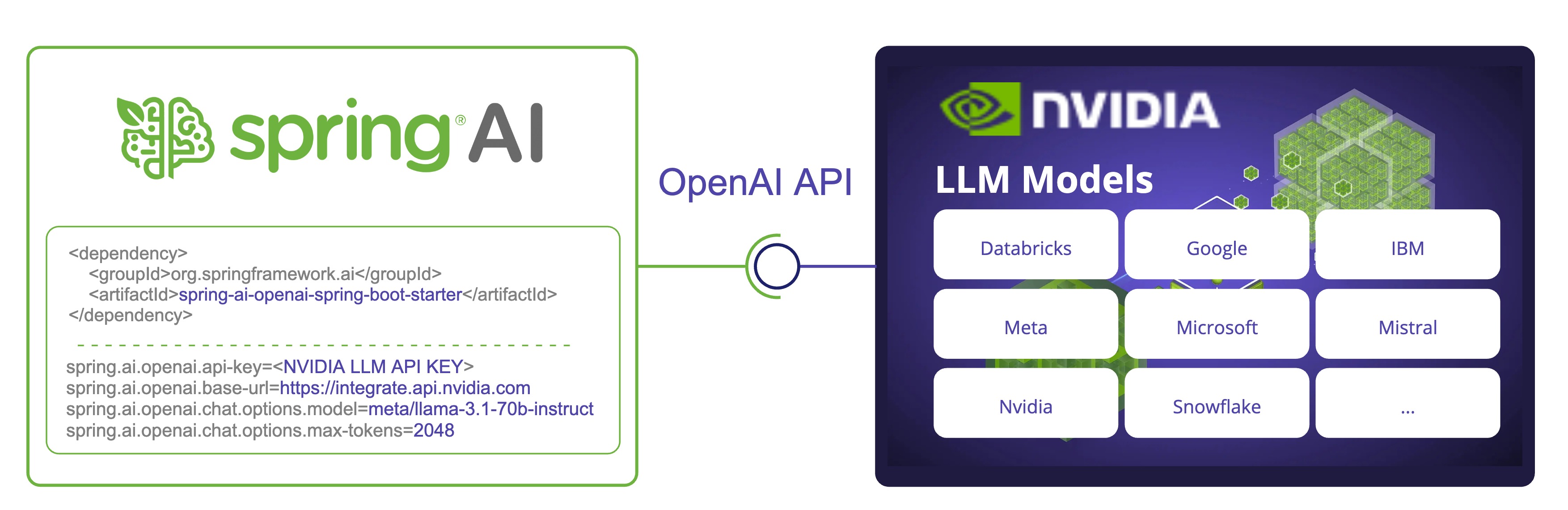
NVIDIA LLM API では、max-tokens パラメーターを明示的に設定する必要があります。そうしないと、サーバーエラーがスローされます。 |
Spring AI で NVIDIA LLM API を使用する例については、NvidiaWithOpenAiChatModelIT.java [GitHub] (英語) テストを確認してください。
前提条件
十分なクレジットで NVIDIA (英語) アカウントを作成します。
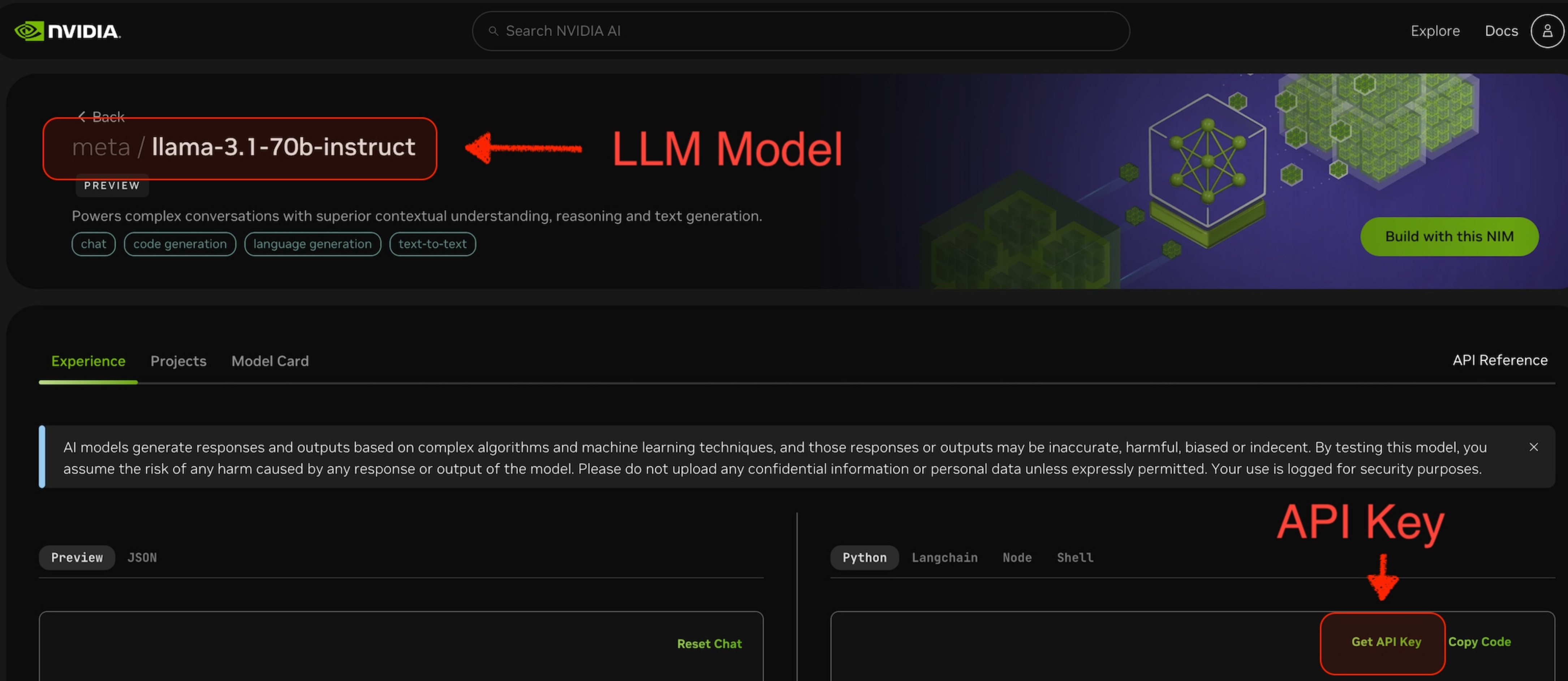
使用する LLM モデルを選択します。たとえば、下のスクリーンショットの
meta/llama-3.1-70b-instructです。選択したモデルのページから、このモデルにアクセスするための
api-keyを取得できます。
自動構成
Spring AI 自動構成、スターターモジュールのアーティファクト名に大きな変更がありました。詳細については、アップグレードノートを参照してください。 |
Spring AI は、OpenAI チャットクライアント用の Spring Boot 自動構成を提供します。これを有効にするには、プロジェクトの Maven pom.xml ファイルに次の依存関係を追加します。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency> または、Gradle build.gradle ビルドファイルに保存します。
dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
}| Spring AI BOM をビルドファイルに追加するには、"依存関係管理" セクションを参照してください。 |
チャットのプロパティ
再試行プロパティ
プレフィックス spring.ai.retry は、OpenAI チャットモデルの再試行メカニズムを構成できるプロパティプレフィックスとして使用されます。
| プロパティ | 説明 | デフォルト |
|---|---|---|
spring.ai.retry.max-attempts | 再試行の最大回数。 | 10 |
spring.ai.retry.backoff.initial-interval | 指数関数的バックオフポリシーの初期スリープ期間。 | 2 秒 |
spring.ai.retry.backoff.multiplier | バックオフ間隔の乗数。 | 5 |
spring.ai.retry.backoff.max-interval | 最大バックオフ期間。 | 3 分 |
spring.ai.retry.on-client-errors | false の場合、NonTransientAiException をスローし、 | false |
spring.ai.retry.exclude-on-http-codes | 再試行をトリガーすべきではない HTTP ステータスコードのリスト (NonTransientAiException をスローするなど)。 | 空 |
spring.ai.retry.on-http-codes | 再試行をトリガーする必要がある HTTP ステータスコードのリスト (例: TransientAiException をスローする)。 | 空 |
接続プロパティ
接頭辞 spring.ai.openai は、OpenAI への接続を可能にするプロパティ接頭辞として使用されます。
| プロパティ | 説明 | デフォルト |
|---|---|---|
spring.ai.openai.base-url | 接続先の URL。 | - |
spring.ai.openai.api-key | NVIDIA API キー | - |
プロパティの構成
チャットの自動構成の有効化と無効化は、プレフィックス 有効にするには、spring.ai.model.chat=openai (デフォルトで有効になっています) 無効にするには、spring.ai.model.chat=none (または openai と一致しない値) この変更は、複数のモデルの構成を可能にするために行われます。 |
プレフィックス spring.ai.openai.chat は、OpenAI のチャットモデル実装を構成できるプロパティプレフィックスです。
| プロパティ | 説明 | デフォルト |
|---|---|---|
spring.ai.openai.chat.enabled (削除され、無効になりました) | OpenAI チャットモデルを有効にします。 | true |
spring.ai.model.chat | OpenAI チャットモデルを有効にします。 | 開く |
spring.ai.openai.chat.base-url | オプションで spring.ai.openai.base-url をオーバーライドしてチャット固有の URL を提供します。 | - |
spring.ai.openai.chat.api-key | オプションで spring.ai.openai.api-key をオーバーライドしてチャット固有の API キーを提供します | - |
spring.ai.openai.chat.model | 使用する NVIDIA LLM モデル (英語) | - |
spring.ai.openai.chat.temperature | 生成される補完の見かけの創造性を制御するために使用するサンプリング温度。値を高くすると出力がよりランダムになり、値を低くすると結果がより集中的で決定的になります。これら 2 つの設定の相互作用を予測するのは難しいため、同じ完了リクエストに対して温度と top_p を変更することはお勧めできません。 | 0.8 |
spring.ai.openai.chat.frequency-penalty | -2.0 から 2.0 までの数値。正の値を指定すると、これまでのテキスト内の既存の頻度に基づいて新しいトークンにペナルティが課され、モデルが同じ行をそのまま繰り返す可能性が低くなります。 | 0.0f |
spring.ai.openai.chat.max-tokens | チャット補完で生成するトークンの最大数。入力トークンと生成されたトークンの合計の長さは、モデルのコンテキストの長さによって制限されます。 | NOTE: NVIDIA LLM API では、 |
spring.ai.openai.chat.n | 各入力メッセージに対して生成するチャット補完の選択肢の数。すべての選択肢にわたって生成されたトークンの数に基づいて料金が請求されることに注意してください。コストを最小限に抑えるために、n を 1 に保ちます。 | 1 |
spring.ai.openai.chat.presence-penalty | -2.0 から 2.0 までの数値。正の値を指定すると、これまでにテキストに出現したかどうかに基づいて新しいトークンにペナルティが課され、モデルが新しいトピックについて話す可能性が高まります。 | - |
spring.ai.openai.chat.response-format | モデルが出力する必要がある形式を指定するオブジェクト。 | - |
spring.ai.openai.chat.seed | この機能はベータ版です。指定した場合、システムは、同じシードとパラメーターを使用した繰り返しリクエストが同じ結果を返すように、決定論的にサンプリングするために最善の努力をします。 | - |
spring.ai.openai.chat.stop | API がさらなるトークンの生成を停止する最大 4 つのシーケンス。 | - |
spring.ai.openai.chat.top-p | 核サンプリングと呼ばれる、温度によるサンプリングの代替方法。モデルは、top_p 確率質量を使用してトークンの結果を考慮します。0.1 は、上位 10% の確率質量を構成するトークンのみが考慮されることを意味します。通常、これまたは温度を変更することをお勧めしますが、両方を変更することは推奨しません。 | - |
spring.ai.openai.chat.tools | モデルが呼び出す可能性のあるツールのリスト。現在、ツールとしては関数のみがサポートされています。これを使用して、モデルが JSON 入力を生成する可能性のある関数のリストを提供します。 | - |
spring.ai.openai.chat.tool-choice | モデルによって呼び出される関数 (存在する場合) を制御します。none は、モデルが関数を呼び出さず、代わりにメッセージを生成することを意味します。auto は、モデルがメッセージを生成するか関数を呼び出すかを選択できることを意味します。{"type: "function" , "function" : {"name" : "my_function" }} で特定の関数を指定すると、モデルは強制的にその関数を呼び出します。関数が存在しない場合は none がデフォルトです。auto はデフォルトです。機能が存在します。 | - |
spring.ai.openai.chat.user | エンドユーザーを表す一意の識別子。OpenAI が不正使用を監視および検出できます。 | - |
spring.ai.openai.chat.stream-usage | (ストリーミングのみ) リクエスト全体のトークン使用統計を含む追加のチャンクを追加するように設定します。このチャンクの | false |
spring.ai.openai.chat.tool-callbacks | ChatModel に登録するツールコールバック。 | - |
spring.ai.openai.chat というプレフィックスが付いたすべてのプロパティは、リクエスト固有のランタイムオプションを Prompt 呼び出しに追加することで実行時にオーバーライドできます。 |
ランタイムオプション
OpenAiChatOptions.java [GitHub] (英語) は、使用するモデル、温度、周波数ペナルティなどのモデル構成を提供します。
起動時に、OpenAiChatModel(api, options) コンストラクターまたは spring.ai.openai.chat.* プロパティを使用してデフォルトのオプションを構成できます。
実行時に、新しいリクエスト固有のオプションを Prompt 呼び出しに追加することで、デフォルトのオプションをオーバーライドできます。たとえば、特定のリクエストのデフォルトのモデルと温度をオーバーライドするには、次のようにします。
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OpenAiChatOptions.builder()
.model("mixtral-8x7b-32768")
.temperature(0.4)
.build()
));| モデル固有の OpenAiChatOptions [GitHub] (英語) に加えて、ChatOptions#builder() [GitHub] (英語) で作成されたポータブル ChatOptions [GitHub] (英語) インスタンスを使用できます。 |
関数呼び出し
NVIDIA LLM API は、それをサポートするモデルを選択した場合にツール / 関数の呼び出しをサポートします。

ChatModel にカスタム Java 関数を登録し、提供されたモデルに、登録された関数の 1 つまたは複数を呼び出すための引数を含む JSON オブジェクトを出力するようインテリジェントに選択させることができます。これは、LLM 機能を外部ツールや API に接続するための強力な手法です。
ツールの例
NVIDIA LLM API ツールを Spring AI で使用する簡単な例を以下に示します。
spring.ai.openai.api-key=${NVIDIA_API_KEY}
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.model=meta/llama-3.1-70b-instruct
spring.ai.openai.chat.max-tokens=2048public class WeatherService implements Function<WeatherService.Request, WeatherService.Response> {
public record Request(String location, String unit) {}
public record Response(double temp, String unit) {}
@Override
public Response apply(Request request) {
double temperature = request.location().contains("Amsterdam") ? 20 : 25;
return new Response(temperature, request.unit);
}
}ToolCallback weatherCallback = FunctionToolCallback.builder("getCurrentWeather", new WeatherService())
.description("Get the weather in location")
.inputType(WeatherService.Request.class)
.build();
var response = chatClient.prompt()
.user("What is the weather in Amsterdam and Paris?")
.tools(weatherCallback)
.call()
.content(); この例では、モデルが気象情報を必要とする場合、自動的に WeatherService を呼び出し、リアルタイムの気象データを取得します。期待されるレスポンスは次のようになります。「アムステルダムの現在の気温は摂氏 20 度、パリの現在の気温は摂氏 25 度です。」
ツール呼び出しについてさらに詳しく読む。
サンプルコントローラー
新しい Spring Boot プロジェクトを作成し、spring-ai-starter-model-openai を pom (または gradle) の依存関係に追加します。
src/main/resources ディレクトリに application.properties ファイルを追加して、OpenAi チャットモデルを有効にして構成します。
spring.ai.openai.api-key=${NVIDIA_API_KEY}
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.model=meta/llama-3.1-70b-instruct
# The NVIDIA LLM API doesn't support embeddings, so we need to disable it.
spring.ai.model.embedding=none
# The NVIDIA LLM API requires this parameter to be set explicitly or server internal error will be thrown.
spring.ai.openai.chat.max-tokens=2048api-key を NVIDIA の資格情報に置き換えます。 |
NVIDIA LLM API では、max-token パラメーターを明示的に設定する必要があります。そうしないと、サーバーエラーがスローされます。 |
以下は、テキスト生成にチャットモデルを使用する単純な @Controller クラスの例です。
@RestController
public class ChatController {
private final OpenAiChatModel chatModel;
@Autowired
public ChatController(OpenAiChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}
