AI の概念
このセクションでは、Spring AI が使用する中心的な概念について説明します。Spring AI の実装方法の背景となる考え方を理解するために、よく読んでおくことをお勧めします。
モデル
AI モデルは、情報を処理および生成するように設計されたアルゴリズムであり、多くの場合人間の認知機能を模倣します。これらのモデルは、大規模なデータセットからパターンとインサイトを学習することで、予測、テキスト、イメージ、その他の出力を作成し、業界全体のさまざまなアプリケーションを強化できます。
AI モデルにはさまざまな種類があり、それぞれが特定のユースケースに適しています。ChatGPT とその生成 AI 機能はテキストの入出力を通じてユーザーを魅了してきましたが、多くのモデルや企業が多様な入出力を提供しています。ChatGPT が登場する前は、多くの人が Midjourney や Stable Diffusion などのテキストからイメージへの生成モデルに魅了されました。
次の表は、入力と出力の型に基づいていくつかのモデルを分類しています。

Spring AI は現在、入力と出力を言語、イメージ、音声として処理するモデルをサポートしています。前の表の最後の行は、テキストを入力として受け入れ、数値を出力するもので、一般的には埋め込みテキストと呼ばれ、AI モデルで使用される内部データ構造を表します。Spring AI は、より高度なユースケースを可能にするために埋め込みをサポートしています。
GPT のようなモデルを区別するのは、GPT (Chat Generative Pre-trained Transformer) の "P" で示されるように、その事前トレーニングされた性質です。この事前トレーニング機能は、AI を、広範な機械学習やモデルトレーニングの経験を必要としない一般的な開発者ツールに変換します。
プロンプト
プロンプトは、AI モデルが特定の出力を生成するようにガイドする言語ベースの入力の基礎として機能します。ChatGPT に慣れている人にとって、プロンプトは、ダイアログボックスに入力されて API に送信される単なるテキストのように見えるかもしれません。ただし、それ以上のものが含まれます。多くの AI モデルでは、プロンプトのテキストは単なる文字列ではありません。
ChatGPT の API にはプロンプト内に複数のテキスト入力があり、各テキスト入力にはロールが割り当てられています。例: システムロールがあり、モデルにどのように動作するかを指示し、インタラクションのコンテキストを設定します。ユーザーロールもあります。これは通常、ユーザーからの入力です。
効果的なプロンプトを作成することは、芸術であり科学でもあります。ChatGPT は、人間同士の会話のために設計されました。これは、SQL などを使用して「質問する」こととはまったく異なります。AI モデルとのコミュニケーションは、他の人と会話するのと似ています。
このインタラクションスタイルの重要性が非常に高いため、「プロンプトエンジニアリング」という用語が独自の分野として登場しました。プロンプトの有効性を向上させるテクニックのコレクションが急速に増えています。プロンプトの作成に時間を投資すると、結果の出力が大幅に向上します。
プロンプトを共有することは共同の習慣となっており、このテーマに関して活発な学術研究が行われています。効果的なプロンプトを作成することがいかに直観に反しているか (SQL との対比など) の例として、最近の研究論文 (英語) では、使用できる最も効果的なプロンプトの 1 つは次のようなものから始まることがわかりました。「深呼吸して、一歩ずつ取り組んでください。」というフレーズです。そうすれば、言語がなぜそれほど重要なのかがわかるはずです。開発中の新しいバージョンはもちろん、ChatGPT 3.5 など、このテクノロジの以前のバージョンを最も効果的に使用する方法はまだ完全には理解していません。
プロンプトテンプレート
効果的なプロンプトを作成するには、リクエストのコンテキストを確立し、リクエストの一部をユーザーの入力に固有の値に置き換えることが含まれます。
このプロセスでは、従来のテキストベースのテンプレートエンジンを使用して、迅速な作成と管理を行います。Spring AI は、この目的のために OSS ライブラリ StringTemplate (英語) を使用します。
たとえば、次のような単純なプロンプトテンプレートを考えてみましょう。
Tell me a {adjective} joke about {content}.Spring AI では、プロンプトテンプレートは Spring MVC アーキテクチャの「ビュー」に似ています。モデルオブジェクト (通常は java.util.Map) は、テンプレート内のプレースホルダーを設定するために提供されます。「レンダリングされた」文字列は、AI モデルに提供されるプロンプトのコンテンツになります。
モデルに送信されるプロンプトの特定のデータ形式にはかなりのばらつきがあります。最初は単純な文字列として始まったプロンプトは、複数のメッセージを含むように進化し、各メッセージ内の各文字列がモデルの個別のロールを表します。
埋め込み
埋め込みは、入力間の関連性を捉えるテキスト、イメージ、ビデオの数値表現です。
埋め込みは、テキスト、イメージ、ビデオをベクトルと呼ばれる浮動小数点数の配列に変換することによって機能します。これらのベクトルは、テキスト、イメージ、ビデオの意味を捉えるように設計されています。埋め込み配列の長さは、ベクトルの次元と呼ばれます。
2 つのテキストのベクトル表現間の数値距離を計算することにより、アプリケーションは埋め込みベクトルの生成に使用されるオブジェクト間の類似性を判断できます。

AI を研究する Java 開発者として、複雑な数学理論や、これらのベクトル表現の背後にある特定の実装を理解する必要はありません。特に AI 機能をアプリケーションに統合する場合は、AI システム内でのロールと機能の基本的な理解があれば十分です。
埋め込みは、検索拡張生成 (RAG) パターンなどの実用的なアプリケーションで特に重要です。埋め込みにより、データをセマンティック空間内のポイントとして表現できます。セマンティック空間は、ユークリッド幾何学の 2 次元空間に似ていますが、より高次元です。つまり、ユークリッド幾何学の平面上のポイントが座標に基づいて近かったり遠かったりするのと同じように、セマンティック空間ではポイントの近さが意味の類似性を反映します。同様のトピックに関する文は、グラフ上でポイントが互いに近い位置にあるのと同じように、この多次元空間でより近くに配置されます。この近接性は、テキスト分類、セマンティック検索、さらには製品の推奨などのタスクに役立ちます。AI は、この拡張されたセマンティックランドスケープ内の「場所」に基づいて関連する概念を識別してグループ化できるためです。
この意味空間はベクトルとして考えることができます。
トークン
トークンは、AI モデルがどのように機能するかの構成要素として機能します。入力時に、モデルは単語をトークンに変換します。出力時に、トークンを単語に変換します。
英語では、1 トークンは単語の約 75% に相当します。参考までに、シェイクスピアの全作品は、約 900,000 語で、約 1.2 百万トークンに変換されます。

おそらくさらに重要なのは、トークン = お金だということです。ホスト型 AI モデルのコンテキストでは、料金は使用されるトークンの数によって決まります。入力と出力の両方が全体のトークン数に影響します。
また、モデルにはトークン制限があり、1 回の API 呼び出しで処理されるテキストの量が制限されます。このしきい値は、多くの場合「コンテキストウィンドウ」と呼ばれます。モデルは、この制限を超えるテキストを処理しません。
たとえば、ChatGPT3 には 4K トークン制限がありますが、GPT4 には 8K、16K、32K などのさまざまなオプションが用意されています。Anthropic の Claude AI モデルは 100,000 トークンの制限を備えており、Meta の最近の調査では 1,000,000 のトークン制限モデルが得られました。
GPT4 を使用して収集したシェイクスピアの作品を要約するには、データを細分化し、モデルのコンテキストウィンドウの制限内でデータを表示するソフトウェアエンジニアリング戦略を考案する必要があります。Spring AI プロジェクトは、このタスクに役立ちます。
構造化された出力
AI モデルの出力は、応答を JSON で要求した場合でも、従来は java.lang.String として届きます。これは正しい JSON かもしれませんが、JSON データ構造ではありません。単なる文字列です。また、プロンプトの一部として「JSON を要求」することは、100% 正確ではありません。
この複雑さにより、意図した出力を生成するためのプロンプトを作成し、その結果得られた単純な文字列をアプリケーション統合に使用できるデータ構造に変換するという専門フィールドが生まれました。

構造化された出力変換は細心の注意を払って作成されたプロンプトを採用しており、目的の書式設定を実現するにはモデルとの複数回のやり取りが必要になることがよくあります。
データと API を AI モデルに取り込む
トレーニングされていない情報を AI モデルに提供するにはどうすればよいでしょうか ?
GPT 3.5/4.0 データセットは 2021 年 9 月までしか延長されないことに注意してください。このモデルは、その日付以降の知識を必要とする質問に対する答えは分からないと言います。興味深いトリビアは、このデータセットが約 650 GB であるということです。
AI モデルをカスタマイズしてデータを組み込むには、次の 3 つの手法があります。
ファインチューニング : この従来の機械学習手法には、モデルの調整と内部の重み付けの変更が含まれます。ただし、これは機械学習の専門家にとっては困難なプロセスであり、GPT のようなモデルの場合はそのサイズにより非常にリソースを大量に消費します。また、一部のモデルではこのオプションが提供されない場合があります。
プロンプトスタッフィング : より実用的な代替案としては、モデルに提供されるプロンプト内にデータを埋め込む方法があります。モデルのトークン制限を考慮すると、モデルのコンテキストウィンドウ内に関連データを表示するためのテクニックが必要です。このアプローチは、俗に「プロンプトスタッフィング」と呼ばれます。Spring AI ライブラリは、検索拡張生成 (RAG) とも呼ばれる「プロンプトスタッフィング」テクニックに基づくソリューションの実装に役立ちます。

検索拡張生成
AI モデルの正確なレスポンスを求めるプロンプトに関連データを組み込むという課題に対処するために、検索拡張生成 (RAG) と呼ばれる手法が登場しました。
このアプローチにはバッチ処理スタイルのプログラミングモデルが含まれており、ジョブはドキュメントから非構造化データを読み取り、変換して、ベクトルデータベースに書き込みます。大まかに言えば、これは ETL (抽出、変換、ロード) パイプラインです。ベクトルデータベースは、RAG 技術の検索部分に使用されます。
非構造化データをベクトルデータベースにロードする一環として、最も重要な変換の 1 つは、元のドキュメントをより小さな部分に分割することです。元のドキュメントを小さな部分に分割する手順には、次の 2 つの重要な手順があります。
コンテンツの意味上の境界を維持しながら、ドキュメントを複数の部分に分割します。例: 段落と表を含むドキュメントの場合、段落または表の途中でドキュメントを分割することは避けるべきです。コードの場合は、メソッドの実装の途中でコードを分割しないでください。
ドキュメントの部分をさらに、AI モデルのトークン制限のわずかな割合のサイズの部分に分割します。
RAG の次のフェーズは、ユーザー入力の処理です。ユーザーの質問に AI モデルが回答する場合、質問とすべての「類似した」ドキュメント部分がプロンプトに配置され、AI モデルに送信されます。これが、ベクトルデータベースを使用する理由です。類似したコンテンツを見つけるのが非常に得意です。

ETL パイプラインは、データソースからデータを抽出し、それを構造化ベクトルストアに保存するフローを調整して、データを AI モデルに渡すときに、データが取得に最適な形式であることを保証する方法についてさらに詳しく説明します。
ChatClient - RAG では、
QuestionAnswerAdvisorを使用してアプリケーションで RAG 機能を有効にする方法について説明します。
ツール呼び出し
大規模言語モデル (LLM) はトレーニング後にフリーズされ、知識が古くなり、外部データにアクセスしたり変更したりできなくなります。
ツール呼び出しメカニズムはこれらの欠点を解決します。これにより、独自のサービスをツールとして登録し、大規模な言語モデルを外部システムの API に接続できるようになります。これらのシステムは、LLM にリアルタイムデータを提供したり、LLM に代わってデータ処理アクションを実行したりできます。
Spring AI は、ツール呼び出しをサポートするために記述する必要があるコードを大幅に簡素化します。ツール呼び出しの会話を自動で処理します。ツールを @Tool アノテーション付きメソッドとして提供し、プロンプトオプションで提供してモデルで使用できるようにすることができます。さらに、1 つのプロンプトで複数のツールを定義して参照することもできます。
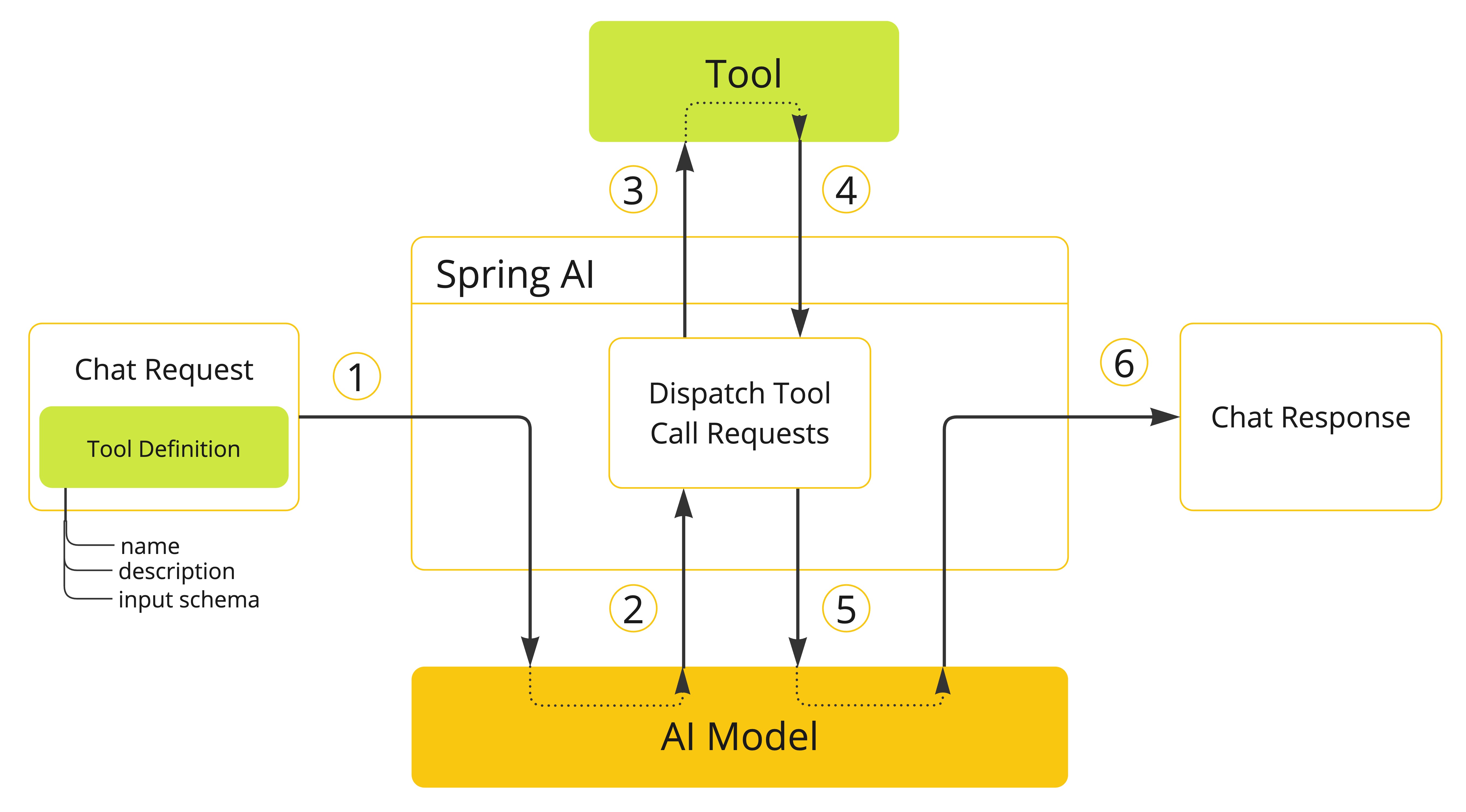
モデルでツールを使用できるようにするには、その定義をチャットリクエストに含めます。各ツール定義は、名前、説明、入力パラメーターのスキーマで構成されます。
モデルがツールを呼び出すことを決定すると、定義されたスキーマに従ってモデル化されたツール名と入力パラメーターを含むレスポンスが送信されます。
アプリケーションは、ツール名を使用して、提供された入力パラメーターでツールを識別し、実行する責任があります。
ツール呼び出しの結果はアプリケーションによって処理されます。
アプリケーションはツール呼び出しの結果をモデルに送り返します。
モデルは、ツール呼び出しの結果を追加のコンテキストとして使用して、最終レスポンスを生成します。
さまざまな AI モデルでこの機能を使用する方法の詳細については、ツール呼び出しのドキュメントを参照してください。
AI のレスポンスを評価する
ユーザーのリクエストに応じて AI システムの出力を効果的に評価することは、最終アプリケーションの精度と有用性を確保するために非常に重要です。いくつかの新しい技術により、この目的で事前トレーニングされたモデル自体を使用できるようになります。
この評価プロセスには、生成されたレスポンスがユーザーの意図およびクエリのコンテキストと一致しているかどうかの分析が含まれます。関連性、一貫性、事実の正しさなどの指標は、AI によって生成されたレスポンスの品質を評価するために使用されます。
1 つのアプローチには、ユーザーのリクエストとモデルに対する AI モデルのレスポンスの両方を提示し、そのレスポンスが提供されたデータと一致するかどうかをクエリすることが含まれます。
さらに、ベクトルデータベースに補足データとして保存されている情報を活用すると、評価プロセスを強化でき、レスポンスの関連性の判断に役立ちます。
Spring AI プロジェクトは、現在、モデルレスポンスを評価するための基本的な戦略へのアクセスを提供する Evaluator API を提供します。詳細については、評価テストドキュメントを参照してください。

