このバージョンはまだ開発中であり、まだ安定しているとは考えられていません。最新のスナップショットバージョンについては、Spring AI 1.1.5 を使用してください。 |
Ollama チャット
Ollama (英語) を使用すると、さまざまな大規模言語モデル (LLM) をローカルで実行し、そこからテキストを生成できます。Spring AI は、OllamaChatModel API を使用して Ollama チャット補完機能をサポートします。
| Ollama は、OpenAI API 互換エンドポイントも提供します。OpenAI API 互換性セクションでは、Spring AI OpenAI を使用して Ollama サーバーに接続する方法について説明します。 |
前提条件
まず、Ollama インスタンスにアクセスする必要があります。次のようないくつかのオプションがあります。
ローカルマシン上の Ollama をダウンロードしてインストールします (英語) 。
Kubernetes サービスバインディングを介して Ollama インスタンスにバインドします。
アプリケーションで使用するモデルを Ollama モデルライブラリ (英語) から取得できます。
ollama pull <model-name>何千もの中からフリーで GGUF Hugging Face モデル (英語) を引くこともできます:
ollama pull hf.co/<username>/<model-repository>あるいは、必要なモデル自動プルモデルを自動的にダウンロードするオプションを有効にすることもできます。
自動構成
Spring AI 自動構成、スターターモジュールのアーティファクト名に大きな変更がありました。詳細については、アップグレードノートを参照してください。 |
Spring AI は、Ollama チャット統合用の Spring Boot 自動構成を提供します。これを有効にするには、プロジェクトの Maven pom.xml または Gradle build.gradle ビルドファイルに次の依存関係を追加します。
Maven
Gradle
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-ollama'
}| Spring AI BOM をビルドファイルに追加するには、"依存関係管理" セクションを参照してください。 |
基本プロパティ
プレフィックス spring.ai.ollama は、Ollama への接続を構成するためのプロパティプレフィックスです。
プロパティ | 説明 | デフォルト |
spring.ai.ollama.base-url | Ollama API サーバーが実行されているベース URL。 |
|
Ollama 統合および自動プルモデルを初期化するためのプロパティを次に示します。
プロパティ | 説明 | デフォルト |
spring.ai.ollama.init.pull-model-strategy | 起動時にモデルをプルするかどうか、およびその方法。 |
|
spring.ai.ollama.init.timeout | モデルがプルされるまで待機する時間。 |
|
spring.ai.ollama.init.max-retries | モデルプル操作の最大再試行回数。 |
|
spring.ai.ollama.init.chat.include | この型のモデルを初期化タスクに含めます。 |
|
spring.ai.ollama.init.chat.additional-models | デフォルトのプロパティで構成されたモデル以外に初期化する追加のモデル。 |
|
チャットのプロパティ
チャットの自動構成の有効化と無効化は、プレフィックス 有効にするには、spring.ai.model.chat=ollama (デフォルトで有効になっています) 無効にするには、spring.ai.model.chat=none (または ollama に一致しない値) この変更は、複数のモデルの構成を可能にするために行われます。 |
プレフィックス spring.ai.ollama.chat.options は、Ollama チャットモデルを構成するプロパティプレフィックスです。これには、model、keep-alive、format などの Ollama リクエスト (詳細) パラメーターと、Ollama モデル options プロパティが含まれます。
Ollama チャットモデルの高度なリクエストパラメーターは次のとおりです。
プロパティ | 説明 | デフォルト |
spring.ai.ollama.chat.enabled (削除され、無効になりました) | Ollama チャットモデルを有効にします。 | true |
spring.ai.model.chat | Ollama チャットモデルを有効にします。 | オラマ |
spring.ai.ollama.chat.options.model | 使用するサポートされているモデル [GitHub] (英語) の名前。 | ミストラル |
spring.ai.ollama.chat.options.format | レスポンスを返す形式。 | - |
spring.ai.ollama.chat.options.keep_alive | リクエスト後にモデルがメモリにロードされたままになる時間を制御します | 5 分 |
残りの options プロパティは、Ollama の有効なパラメーターと値 [GitHub] (英語) および Ollama 型 [GitHub] (英語) に基づいています。デフォルト値は、Ollama 型のデフォルト [GitHub] (英語) に基づいています。
プロパティ | 説明 | デフォルト |
spring.ai.ollama.chat.options.numa | NUMA を使用するかどうか。 | false |
spring.ai.ollama.chat.options.num-ctx | 次のトークンの生成に使用されるコンテキストウィンドウのサイズを設定します。 | 2048 |
spring.ai.ollama.chat.options.num-batch | プロンプト処理の最大バッチサイズ。 | 512 |
spring.ai.ollama.chat.options.num-gpu | GPU に送信するレイヤーの数。macOS では、メタルサポートを有効にする場合はデフォルトで 1、無効にする場合は 0 です。ここで 1 は、NumGPU を動的に設定する必要があることを示します | -1 |
spring.ai.ollama.chat.options.main-gpu | 複数の GPU を使用する場合、このオプションは、すべての GPU に計算を分割するオーバーヘッドが価値のない小さなテンソルに使用する GPU を制御します。問題の GPU は、一時的な結果用のスクラッチバッファーを保存するために、わずかに多くの VRAM を使用します。 | 0 |
spring.ai.ollama.chat.options.low-vram | - | false |
spring.ai.ollama.chat.options.f16-kv | - | true |
spring.ai.ollama.chat.options.logits-all | 最後のトークンだけでなく、すべてのトークンの logits を返します。補完が logprob を返すようにするには、これが true である必要があります。 | - |
spring.ai.ollama.chat.options.vocab-only | 重みではなく語彙のみをロードします。 | - |
spring.ai.ollama.chat.options.use-mmap | デフォルトでは、モデルはメモリにマップされるため、システムは必要に応じてモデルの必要な部分のみを読み込むことができます。ただし、モデルが RAM の合計量よりも大きい場合、またはシステムの使用可能なメモリが少ない場合は、mmap を使用するとページアウトのリスクが高まり、パフォーマンスに悪影響を与える可能性があります。mmap を無効にすると読み込み時間が遅くなりますが、mlock を使用していない場合はページアウトが減る可能性があります。モデルが RAM の合計量よりも大きい場合、mmap をオフにするとモデルがまったく読み込まれなくなることに注意してください。 | null |
spring.ai.ollama.chat.options.use-mlock | モデルをメモリにロックし、メモリマップ時にスワップアウトされないようにします。これによりパフォーマンスは向上しますが、実行により多くの RAM が必要になり、モデルが RAM にロードされるときにロード時間が遅くなる可能性があるため、メモリマッピングの利点の一部が失われます。 | false |
spring.ai.ollama.chat.options.num-thread | 計算中に使用するスレッドの数を設定します。デフォルトでは、Ollama は最適なパフォーマンスを得るためにこれを検出します。この値を、(論理コア数ではなく) システムに搭載されている物理 CPU コア数に設定することをお勧めします。0 = ランタイムに決定させる | 0 |
spring.ai.ollama.chat.options.num-keep | - | 4 |
spring.ai.ollama.chat.options.seed | 生成に使用する乱数シードを設定します。これを特定の数値に設定すると、モデルは同じプロンプトに対して同じテキストを生成します。 | -1 |
spring.ai.ollama.chat.options.num-predict | テキストを生成するときに予測するトークンの最大数。(-1 = 無限生成、-2 = コンテキストを埋める) | -1 |
spring.ai.ollama.chat.options.top-k | ナンセンスが生成される確率を減らします。値が大きいほど (100 など)、より多様な回答が得られますが、値が小さいほど (10 など) より保守的になります。 | 40 |
spring.ai.ollama.chat.options.top-p | top-k と連携します。値が大きいほど (0.95 など)、より多様なテキストが生成され、値が小さいほど (0.5 など)、より焦点が絞られた控えめなテキストが生成されます。 | 0.9 |
spring.ai.ollama.chat.options.min-p | top_p の代替であり、品質と多様性のバランスを確保することを目的としています。パラメーター p は、トークンが考慮される最小確率を、最も可能性の高いトークンの確率と比較して表します。例: p=0.05 で、最も可能性の高いトークンの確率が 0.9 の場合、0.045 未満のロジット値は除外されます。 | 0.0 |
spring.ai.ollama.chat.options.tfs-z | テールフリーサンプリングは、出力からの可能性の低いトークンの影響を軽減するために使用されます。値が大きいほど (2.0 など)、影響はさらに軽減されますが、値 1.0 はこの設定を無効にします。 | 1.0 |
spring.ai.ollama.chat.options.typical-p | - | 1.0 |
spring.ai.ollama.chat.options.repeat-last-n | 繰り返しを防ぐために、モデルがどこまで遡るかを設定します。(デフォルト: 64, 0 = 無効、-1 = num_ctx) | 64 |
spring.ai.ollama.chat.options.temperature | モデルの温度。温度を上げると、モデルはより創造的に答えられるようになります。 | 0.8 |
spring.ai.ollama.chat.options.repeat-penalty | 繰り返しをどの程度強くペナルティするかを設定します。値が大きいほど (1.5 など)、繰り返しに対するペナルティがより強くなり、値が小さいほど (0.9 など) ペナルティがより緩やかになります。 | 1.1 |
spring.ai.ollama.chat.options.presence-penalty | - | 0.0 |
spring.ai.ollama.chat.options.frequency-penalty | - | 0.0 |
spring.ai.ollama.chat.options.mirostat | 複雑さを制御するために Mirostat サンプリングを有効にします。(default: 0, 0 = 無効、1 = ミロスタット、2 = ミロスタット 2.0) | 0 |
spring.ai.ollama.chat.options.mirostat-tau | 出力の一貫性と多様性の間のバランスを制御します。値を低くすると、より焦点が絞られた一貫したテキストになります。 | 5.0 |
spring.ai.ollama.chat.options.mirostat-eta | 生成されたテキストからのフィードバックにアルゴリズムがどれだけ早く応答するかに影響します。学習率が低いと調整が遅くなり、学習率が高いとアルゴリズムの応答性が高くなります。 | 0.1 |
spring.ai.ollama.chat.options.penalize-newline | - | true |
spring.ai.ollama.chat.options.stop | 使用する停止シーケンスを設定します。このパターンが発生すると、LLM はテキストの生成を停止して戻ります。モデルファイルで複数の個別の停止パラメーターを指定することにより、複数の停止パターンを設定できます。 | - |
spring.ai.ollama.chat.options.tool-names | 単一のプロンプトリクエストで関数呼び出しを有効にするツールのリスト(名前で識別されます)。これらの名前のツールは、ToolCallback レジストリに存在している必要があります。 | - |
spring.ai.ollama.chat.options.tool-callbacks | ChatModel に登録するツールコールバック。 | - |
spring.ai.ollama.chat.options.internal-tool-execution-enabled | False の場合、Spring AI はツール呼び出しを内部で処理せず、クライアントにプロキシします。その後、ツール呼び出しを処理し、適切な関数にディスパッチして、結果を返すのはクライアントの責任です。True (デフォルト) の場合、Spring AI は関数呼び出しを内部で処理します。関数呼び出しをサポートするチャットモデルにのみ適用されます。 | true |
spring.ai.ollama.chat.options で始まるすべてのプロパティは、リクエスト固有のランタイムオプションを Prompt 呼び出しに追加することによって実行時にオーバーライドできます。 |
ランタイムオプション
OllamaChatOptions.java [GitHub] (英語) クラスは、使用するモデル、温度、思考モードなどのモデル構成を提供します。
OllamaOptions クラスは非推奨となりました。チャットモデルには OllamaChatOptions、埋め込みモデルには OllamaEmbeddingOptions をご利用ください。新しいクラスは、型安全でモデル固有の設定オプションを提供します。 |
起動時に、OllamaChatModel(api, options) コンストラクターまたは spring.ai.ollama.chat.options.* プロパティを使用してデフォルトのオプションを構成できます。
実行時に、Prompt 呼び出しに新しいリクエスト固有のオプションを追加することで、デフォルトのオプションをオーバーライドできます。例: 特定のリクエストのデフォルトのモデルと温度をオーバーライドするには、次のようにします。
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OllamaChatOptions.builder()
.model(OllamaModel.LLAMA3_1)
.temperature(0.4)
.build()
));| モデル固有の OllamaChatOptions [GitHub] (英語) に加えて、ChatOptions#builder() [GitHub] (英語) で作成されたポータブル ChatOptions [GitHub] (英語) インスタンスを使用することもできます。 |
自動プルモデル
Spring AI Ollama は、Ollama インスタンスでモデルが利用できない場合に自動的にモデルをプルできます。この機能は、開発とテスト、アプリケーションを新しい環境にデプロイする場合に特に便利です。
| また、何千ものフリー GGUF Hugging Face モデル (英語) のいずれかを名前でプルすることもできます。 |
モデルをプルするための戦略は 3 つあります。
always(PullModelStrategy.ALWAYSで定義): モデルがすでに利用可能であっても、常にモデルをプルします。モデルの最新バージョンを使用していることを確認できます。when_missing(PullModelStrategy.WHEN_MISSINGで定義): モデルがまだ利用できない場合にのみモデルをプルします。これにより、モデルの古いバージョンが使用される可能性があります。never(PullModelStrategy.NEVERで定義): モデルを自動的にプルしません。
| モデルのダウンロード中に遅延が発生する可能性があるため、本番環境では自動プルは推奨されません。代わりに、必要なモデルを事前に評価して事前ダウンロードすることを検討してください。 |
構成プロパティとデフォルトオプションで定義されたすべてのモデルは、起動時に自動的にプルできます。構成プロパティを使用して、プル戦略、タイムアウト、再試行の最大回数を構成できます。
spring:
ai:
ollama:
init:
pull-model-strategy: always
timeout: 60s
max-retries: 1| 指定されたすべてのモデルが Ollama で利用可能になるまで、アプリケーションは初期化を完了しません。モデルのサイズとインターネット接続速度によっては、アプリケーションの起動時間が大幅に遅くなる可能性があります。 |
起動時に追加のモデルを初期化できます。これは、実行時に動的に使用されるモデルに便利です。
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
additional-models:
- llama3.2
- qwen2.5プル戦略を特定の型のモデルにのみ適用する場合は、初期化タスクからチャットモデルを除外できます。
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
include: falseこの構成では、チャットモデルを除くすべてのモデルにプル戦略が適用されます。
関数呼び出し
OllamaChatModel にカスタム Java 関数を登録し、Ollama モデルで、登録された関数の 1 つまたは複数を呼び出すための引数を含む JSON オブジェクトをインテリジェントに出力するように選択できます。これは、LLM 機能を外部ツールや API に接続するための強力な手法です。ツール呼び出しの詳細については、こちらを参照してください。
| 関数呼び出し機能を使用するには Ollama 0.2.8 以降が必要であり、ストリーミングモードで使用するには Ollama 0.4.6 以降が必要です。 |
思考モード (推論)
Ollama は、最終的な答えを出す前に内部推論プロセスを出力できる推論モデルのための思考モードをサポートしています。この機能は、Qwen3、DeepSeek-v3.1、DeepSeek R1、GPT-OSS などのモデルで利用できます。
| 思考モードは、モデルの推論プロセスを理解するのに役立ち、複雑な問題に対するレスポンスの品質を向上させることができます。 |
デフォルトの動作 (Ollama 0.12+) : 思考機能付きモデル(qwen3:*-thinking、deepseek-r1、deepseek-v3.1 など)は、think オプションが明示的に設定されていない場合、デフォルトで思考を自動的に有効にします。標準モデル(qwen2.5:*、llama3.2 など)は、デフォルトで思考を有効にしません。この動作を明示的に制御するには、.enableThinking() または .disableThinking() を使用します。 |
思考モードを有効にする
ほとんどのモデル (Qwen3、DeepSeek-v3.1、DeepSeek R1) は、単純なブール値の有効化 / 無効化をサポートしています。
ChatResponse response = chatModel.call(
new Prompt(
"How many letter 'r' are in the word 'strawberry'?",
OllamaChatOptions.builder()
.model("qwen3")
.enableThinking()
.build()
));
// Access the thinking process
String thinking = response.getResult().getMetadata().get("thinking");
String answer = response.getResult().getOutput().getText();思考を明示的に無効にすることもできます。
ChatResponse response = chatModel.call(
new Prompt(
"What is 2+2?",
OllamaChatOptions.builder()
.model("deepseek-r1")
.disableThinking()
.build()
));思考レベル (GPT-OSS のみ)
GPT-OSS モデルでは、ブール値ではなく明示的な思考レベルが必要です。
// Low thinking level
ChatResponse response = chatModel.call(
new Prompt(
"Generate a short headline",
OllamaChatOptions.builder()
.model("gpt-oss")
.thinkLow()
.build()
));
// Medium thinking level
ChatResponse response = chatModel.call(
new Prompt(
"Analyze this dataset",
OllamaChatOptions.builder()
.model("gpt-oss")
.thinkMedium()
.build()
));
// High thinking level
ChatResponse response = chatModel.call(
new Prompt(
"Solve this complex problem",
OllamaChatOptions.builder()
.model("gpt-oss")
.thinkHigh()
.build()
));思考コンテンツへのアクセス
思考内容はレスポンスメタデータで確認できます。
ChatResponse response = chatModel.call(
new Prompt(
"Calculate 17 × 23",
OllamaChatOptions.builder()
.model("deepseek-r1")
.enableThinking()
.build()
));
// Get the reasoning process
String thinking = response.getResult().getMetadata().get("thinking");
System.out.println("Reasoning: " + thinking);
// Output: "17 × 20 = 340, 17 × 3 = 51, 340 + 51 = 391"
// Get the final answer
String answer = response.getResult().getOutput().getText();
System.out.println("Answer: " + answer);
// Output: "The answer is 391"思考しながらストリーミング
思考モードはストリーミングレスポンスでも機能します。
Flux<ChatResponse> stream = chatModel.stream(
new Prompt(
"Explain quantum entanglement",
OllamaChatOptions.builder()
.model("qwen3")
.enableThinking()
.build()
));
stream.subscribe(response -> {
String thinking = response.getResult().getMetadata().get("thinking");
String content = response.getResult().getOutput().getText();
if (thinking != null && !thinking.isEmpty()) {
System.out.println("[Thinking] " + thinking);
}
if (content != null && !content.isEmpty()) {
System.out.println("[Response] " + content);
}
}); 思考が無効になっているか設定されていない場合、thinking メタデータフィールドは null または空になります。 |
マルチモーダル
マルチモーダル性とは、テキスト、イメージ、音声、その他のデータ形式を含むさまざまなソースからの情報を同時に理解して処理するモデルの機能を指します。
マルチモダリティをサポートする Ollama で利用可能なモデルには、ラヴァ (英語) とバクラヴァ (英語) があります ( 完全なリスト (英語) を参照)。詳細については、ラヴァ: 大型言語・視覚アシスタント (英語) を参照してください。
Ollama メッセージ API [GitHub] (英語) は、メッセージに base64 でエンコードされたイメージのリストを組み込むための "images" パラメーターを提供します。
Spring AI のメッセージ [GitHub] (英語) インターフェースは、メディア [GitHub] (英語) 型を導入することで、マルチモーダル AI モデルを促進します。この型には、メッセージ内のメディア添付ファイルに関するデータと詳細が含まれており、Spring の org.springframework.util.MimeType と、生のメディアデータ用の org.springframework.core.io.Resource が利用されます。
以下は、OllamaChatModelMultimodalIT.java [GitHub] (英語) から抜粋した、ユーザーテキストとイメージの融合を示す簡単なコード例です。
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = new UserMessage("Explain what do you see on this picture?",
new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource));
ChatResponse response = chatModel.call(new Prompt(this.userMessage,
OllamaChatOptions.builder().model(OllamaModel.LLAVA)).build()); この例では、multimodal.test.png イメージを入力として受け取るモデルを示します。

「この写真に何が写っているか説明してください」というテキストメッセージとともに、次のようなレスポンスが生成されます。
The image shows a small metal basket filled with ripe bananas and red apples. The basket is placed on a surface, which appears to be a table or countertop, as there's a hint of what seems like a kitchen cabinet or drawer in the background. There's also a gold-colored ring visible behind the basket, which could indicate that this photo was taken in an area with metallic decorations or fixtures. The overall setting suggests a home environment where fruits are being displayed, possibly for convenience or aesthetic purposes.
構造化された出力
Ollama は、モデルが指定された JSON Schema に厳密に準拠したレスポンスを生成することを保証するカスタム構造化された出力 (英語) API を提供します。既存の Spring AI モデルに依存しない構造化出力コンバーターに加えて、これらの API は強化された制御と精度を提供します。
構造化された出力の 2 つのモード
Ollama は、format パラメーターを通じて構造化出力の 2 つの異なるモードをサポートします。
シンプルな "json" 形式 : Ollama に有効な JSON 構造を返すように指示します (予測不可能なスキーマ)
JSON スキーマ形式 : Ollama に特定のスキーマに準拠した JSON を返すように指示します (予測可能な構造)
シンプルな "json" 形式
JSON 出力が必要で、特定の構造は必要ない場合はこれを使用します。
ChatResponse response = chatModel.call(
new Prompt(
"List 3 countries in Europe",
OllamaChatOptions.builder()
.model("llama3.2")
.format("json") // Any valid JSON
.build()
));モデルは、任意の JSON 構造を返すことができます。
["France", "Germany", "Italy"]
// or
{"countries": ["France", "Germany", "Italy"]}
// or
{"data": {"european_countries": ["France", "Germany", "Italy"]}}JSON スキーマ形式 (本番向けに推奨)
確実で予測可能な構造が必要な場合に使用してください。
String jsonSchema = """
{
"type": "object",
"properties": {
"countries": {
"type": "array",
"items": { "type": "string" }
}
},
"required": ["countries"]
}
""";
ChatResponse response = chatModel.call(
new Prompt(
"List 3 countries in Europe",
OllamaChatOptions.builder()
.model("llama3.2")
.outputSchema(jsonSchema) // Enforced schema
.build()
));モデルは、この正確な構造を返す必要があります。
{"countries": ["France", "Germany", "Italy"]}構成
Spring AI を使用すると、OllamaChatOptions ビルダーを使用してレスポンス形式をプログラムで構成できます。
JSON スキーマを使用したチャットオプションビルダーの使用
OllamaChatOptions ビルダーを使用して、レスポンス形式をプログラムで設定できます。
String jsonSchema = """
{
"type": "object",
"properties": {
"steps": {
"type": "array",
"items": {
"type": "object",
"properties": {
"explanation": { "type": "string" },
"output": { "type": "string" }
},
"required": ["explanation", "output"],
"additionalProperties": false
}
},
"final_answer": { "type": "string" }
},
"required": ["steps", "final_answer"],
"additionalProperties": false
}
""";
Prompt prompt = new Prompt("how can I solve 8x + 7 = -23",
OllamaChatOptions.builder()
.model(OllamaModel.LLAMA3_2.getName())
.outputSchema(jsonSchema) // Pass JSON Schema as string
.build());
ChatResponse response = this.ollamaChatModel.call(this.prompt);BeanOutputConverter ユーティリティとの統合
既存の BeanOutputConverter ユーティリティを活用して、ドメインオブジェクトから JSON スキーマを自動的に生成し、後で構造化されたレスポンスをドメイン固有のインスタンスに変換できます。
record MathReasoning(
@JsonProperty(required = true, value = "steps") Steps steps,
@JsonProperty(required = true, value = "final_answer") String finalAnswer) {
record Steps(
@JsonProperty(required = true, value = "items") Items[] items) {
record Items(
@JsonProperty(required = true, value = "explanation") String explanation,
@JsonProperty(required = true, value = "output") String output) {
}
}
}
var outputConverter = new BeanOutputConverter<>(MathReasoning.class);
Prompt prompt = new Prompt("how can I solve 8x + 7 = -23",
OllamaChatOptions.builder()
.model(OllamaModel.LLAMA3_2.getName())
.outputSchema(outputConverter.getJsonSchema()) // Get JSON Schema as string
.build());
ChatResponse response = this.ollamaChatModel.call(this.prompt);
String content = this.response.getResult().getOutput().getText();
MathReasoning mathReasoning = this.outputConverter.convert(this.content); フィールドを required として正確にマークするスキーマを生成するには、必ず @JsonProperty(required = true,…) アノテーションを使用してください。これは JSON スキーマではオプションですが、構造化されたレスポンスが正しく機能するためには推奨されます。 |
API メソッド: .format() vs .outputSchema()
Spring AI は、構造化出力の設定方法として 2 つの方法を提供します。
| メソッド | ユースケース | サンプル |
|---|---|---|
| シンプルな JSON モード - 任意の構造 |
|
| JSON スキーマモード - 構造の強制 |
|
| JSON スキーマモード - 代替 API |
|
ほとんどのユースケースでは、JSON スキーマの検証には .outputSchema(jsonSchemaString) を、シンプルな JSON 出力には .format("json") を使用してください。.format(Map) 方式もサポートされていますが、JSON の解析を手動で行う必要があります。 |
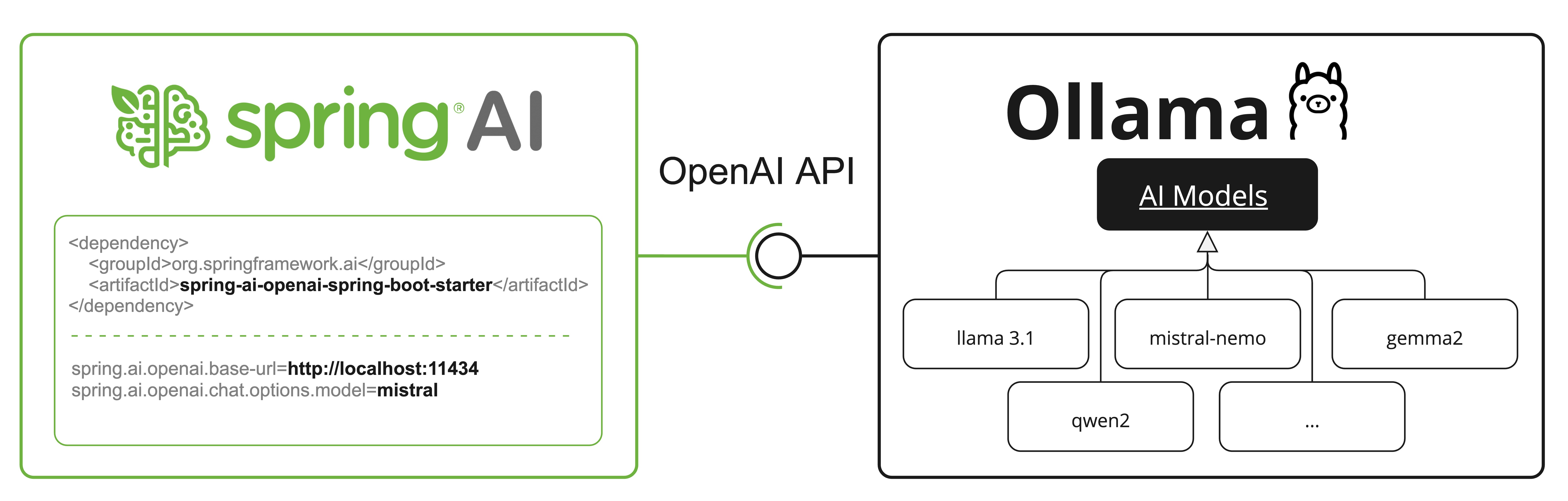
OpenAI API 互換性
Ollama は OpenAI API と互換性があり、Spring AI OpenAI クライアントを使用して Ollama と通信し、ツールを使用できます。そのためには、OpenAI ベース URL を Ollama インスタンス: spring.ai.openai.chat.base-url=http://localhost:11434 に設定し、提供されている Ollama モデルの 1 つ: spring.ai.openai.chat.options.model=mistral を選択する必要があります。
OpenAI クライアントを Ollama と併用する場合、extraBody オプションを使用して Ollama 固有のパラメーター(top_k、repeat_penalty、num_predict など)を渡すことができます。これにより、OpenAI クライアントを使用しながら Ollama の全機能を活用できます。 |
OpenAI 互換性による推論コンテンツ
Ollama の OpenAI 互換エンドポイントは、思考機能を持つモデル(qwen3:*-thinking、deepseek-r1、deepseek-v3.1 など)向けに reasoning_content フィールドをサポートしています。Spring AI OpenAI クライアントを Ollama と併用すると、モデルの推論プロセスが自動的にキャプチャーされ、レスポンスメタデータを通じて利用できるようになります。
これは、Ollama のネイティブ思考モード API(上記の思考モード (推論) に記載)を使用する代わりに使用できる方法です。どちらのアプローチも Ollama の思考モデルで動作しますが、OpenAI 互換エンドポイントでは、フィールド名として thinking ではなく reasoning_content が使用されます。 |
OpenAI クライアントを介して Ollama から推論コンテンツにアクセスする例を次に示します。
// Configure Spring AI OpenAI client to point to Ollama
@Configuration
class OllamaConfig {
@Bean
OpenAiChatModel ollamaChatModel() {
var openAiApi = new OpenAiApi("http://localhost:11434", "ollama");
return new OpenAiChatModel(openAiApi,
OpenAiChatOptions.builder()
.model("deepseek-r1") // or qwen3, deepseek-v3.1, etc.
.build());
}
}
// Use the model with thinking-capable models
ChatResponse response = chatModel.call(
new Prompt("How many letter 'r' are in the word 'strawberry'?"));
// Access the reasoning process from metadata
String reasoning = response.getResult().getMetadata().get("reasoningContent");
if (reasoning != null && !reasoning.isEmpty()) {
System.out.println("Model's reasoning process:");
System.out.println(reasoning);
}
// Get the final answer
String answer = response.getResult().getOutput().getText();
System.out.println("Answer: " + answer);| Ollama(0.12+)の思考機能付きモデルは、OpenAI 互換エンドポイントからアクセスすると自動的に思考モードが有効になります。推論内容は追加の設定を必要とせず、自動的にキャプチャーされます。 |
Spring AI OpenAI ではなく Ollama を使用する例については、OllamaWithOpenAiChatModelIT.java [GitHub] (英語) テストを確認してください。
HuggingFace モデル
Ollama は、すぐにすべての GGUF Hugging Face (英語) チャットモデルにアクセスできます。これらのモデルのいずれかを名前でプルできます: ollama pull hf.co/<username>/<model-repository> または自動プル戦略を構成できます: 自動プルモデル :
spring.ai.ollama.chat.options.model=hf.co/bartowski/gemma-2-2b-it-GGUF
spring.ai.ollama.init.pull-model-strategy=alwaysspring.ai.ollama.chat.options.model: 使用する Hugging Face GGUF モデル (英語) を指定します。spring.ai.ollama.init.pull-model-strategy=always: (オプション) 起動時に自動的にモデルを取得できるようにします。本番環境では、遅延を避けるためにモデルを事前にダウンロードする必要があります。:ollama pull hf.co/bartowski/gemma-2-2b-it-GGUF.
サンプルコントローラー
新しい Spring Boot プロジェクトを作成し、spring-ai-starter-model-ollama を pom (または gradle) の依存関係に追加します。
src/main/resources ディレクトリに application.yaml ファイルを追加して、Ollama チャットモデルを有効にして構成します。
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: mistral
temperature: 0.7base-url を Ollama サーバーの URL に置き換えます。 |
これにより、クラスに挿入できる OllamaChatModel 実装が作成されます。以下は、テキスト生成にチャットモデルを使用する単純な @RestController クラスの例です。
@RestController
public class ChatController {
private final OllamaChatModel chatModel;
@Autowired
public ChatController(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map<String,String> generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}手動構成
Spring Boot 自動構成を使用したくない場合は、アプリケーションで OllamaChatModel を手動で構成できます。OllamaChatModel [GitHub] (英語) は ChatModel および StreamingChatModel を実装し、低レベル OllamaApi クライアントを使用して Ollama サービスに接続します。
これを使用するには、プロジェクトの Maven pom.xml または Gradle build.gradle ビルドファイルに spring-ai-ollama 依存関係を追加します。
Maven
Gradle
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>dependencies {
implementation 'org.springframework.ai:spring-ai-ollama'
}| Spring AI BOM をビルドファイルに追加するには、"依存関係管理" セクションを参照してください。 |
spring-ai-ollama 依存関係により、OllamaEmbeddingModel へのアクセスも提供されます。OllamaEmbeddingModel の詳細については、Ollama 埋め込みモデルセクションを参照してください。 |
次に、OllamaChatModel インスタンスを作成し、それを使用してテキスト生成のリクエストを送信します。
var ollamaApi = OllamaApi.builder().build();
var chatModel = OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(
OllamaChatOptions.builder()
.model(OllamaModel.MISTRAL)
.temperature(0.9)
.build())
.build();
ChatResponse response = this.chatModel.call(
new Prompt("Generate the names of 5 famous pirates."));
// Or with streaming responses
Flux<ChatResponse> response = this.chatModel.stream(
new Prompt("Generate the names of 5 famous pirates."));OllamaChatOptions は、すべてのチャットリクエストの構成情報を提供します。
低レベル OllamaApi クライアント
OllamaApi [GitHub] (英語) は、Ollama チャット補完 API Ollama チャット補完 API [GitHub] (英語) 用の軽量 Java クライアントを提供します。
次のクラス図は、OllamaApi チャットインターフェースとビルドブロックを示しています。

OllamaApi は低レベルの API であり、直接使用することは推奨されません。代わりに OllamaChatModel を使用してください。 |
以下は、API をプログラムで使用する方法を示す簡単なスニペットです。
OllamaApi ollamaApi = new OllamaApi("YOUR_HOST:YOUR_PORT");
// Sync request
var request = ChatRequest.builder("orca-mini")
.stream(false) // not streaming
.messages(List.of(
Message.builder(Role.SYSTEM)
.content("You are a geography teacher. You are talking to a student.")
.build(),
Message.builder(Role.USER)
.content("What is the capital of Bulgaria and what is the size? "
+ "What is the national anthem?")
.build()))
.options(OllamaChatOptions.builder().temperature(0.9).build())
.build();
ChatResponse response = this.ollamaApi.chat(this.request);
// Streaming request
var request2 = ChatRequest.builder("orca-mini")
.ttream(true) // streaming
.messages(List.of(Message.builder(Role.USER)
.content("What is the capital of Bulgaria and what is the size? " + "What is the national anthem?")
.build()))
.options(OllamaChatOptions.builder().temperature(0.9).build().toMap())
.build();
Flux<ChatResponse> streamingResponse = this.ollamaApi.streamingChat(this.request2);
