最新の安定バージョンについては、Spring Batch ドキュメント 6.0.4 を使用してください! |
高度なメタデータの使用
これまで、JobLauncher および JobRepository インターフェースの両方について説明してきました。これらは一緒に、ジョブの単純な起動と、バッチドメインオブジェクトの基本的な CRUD 操作を表します。

JobLauncher は、JobRepository を使用して新しい JobExecution オブジェクトを作成し、実行します。Job および Step の実装は、後で Job の実行中に同じ実行の基本的な更新に同じ JobRepository を使用します。単純なシナリオでは、基本的な操作で十分です。ただし、数百のバッチジョブと複雑なスケジューリング要件がある大規模なバッチ環境では、メタデータへのより高度なアクセスが必要です。
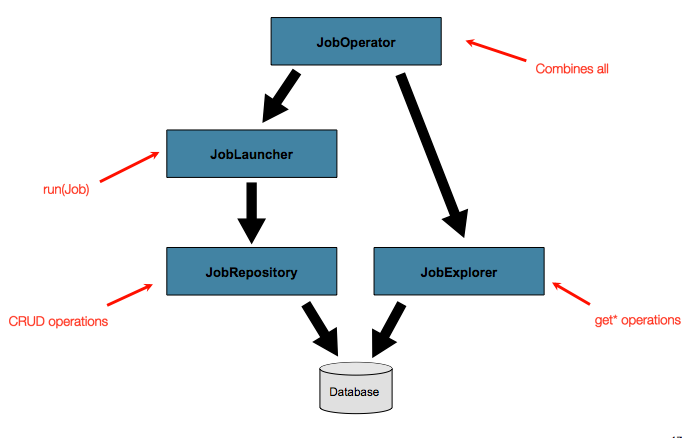
以降のセクションで説明する JobExplorer および JobOperator インターフェースは、メタデータのクエリと制御のための追加機能を追加します。
リポジトリのクエリ
高度な機能を使用する前の最も基本的なニーズは、既存の実行についてリポジトリをクエリする機能です。この機能は、JobExplorer インターフェースによって提供されます。
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
} そのメソッドシグネチャーから明らかなように、JobExplorer は JobRepository の読み取り専用バージョンであり、JobRepository と同様に、ファクトリ Bean を使用して簡単に構成できます。
Java
XML
次の例は、Java で JobExplorer を構成する方法を示しています。
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
return factoryBean.getObject();
}
... 次の例は、XML で JobExplorer を構成する方法を示しています。
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" /> この章の前半、異なるバージョンまたはスキーマを許可するために、JobRepository のテーブルプレフィックスを変更できることに注意しました。JobExplorer は同じテーブルで動作するため、プレフィックスを設定する機能も必要です。
Java
XML
次の例は、Java で JobExplorer のテーブルプレフィックスを設定する方法を示しています。
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
factoryBean.setTablePrefix("SYSTEM.");
return factoryBean.getObject();
}
... 次の例は、XML で JobExplorer のテーブルプレフィックスを設定する方法を示しています。
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:tablePrefix="SYSTEM."/>JobRegistry
JobRegistry (およびその親インターフェースである JobLocator) は必須ではありませんが、コンテキストで使用可能なジョブを追跡したい場合に役立ちます。また、ジョブが別の場所 (子コンテキストなど) で作成された場合に、アプリケーションコンテキストで一元的にジョブを収集する場合にも役立ちます。カスタム JobRegistry 実装を使用して、登録されているジョブの名前やその他のプロパティを操作することもできます。フレームワークによって提供される実装は 1 つだけで、これはジョブ名からジョブインスタンスへの単純なマップに基づいています。
Java
XML
@EnableBatchProcessing を使用すると、JobRegistry が提供されます。次の例は、独自の JobRegistry を構成する方法を示しています。
...
// This is already provided via the @EnableBatchProcessing but can be customized via
// overriding the bean in the DefaultBatchConfiguration
@Override
@Bean
public JobRegistry jobRegistry() throws Exception {
return new MapJobRegistry();
}
... 次の例は、XML で定義されたジョブに JobRegistry を含める方法を示しています。
<bean id="jobRegistry" class="org.springframework.batch.core.configuration.support.MapJobRegistry" />JobRegistry は、Bean ポストプロセッサーを使用するか、スマート初期化シングルトンを使用するか、レジストラーライフサイクルコンポーネントを使用するかのいずれかの方法で設定できます。次のセクションでは、これらのメカニズムについて説明します。
JobRegistryBeanPostProcessor
これは、作成時にすべてのジョブを登録できる Bean ポストプロセッサーです。
Java
XML
次の例は、Java で定義されたジョブに JobRegistryBeanPostProcessor を含める方法を示しています。
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor(JobRegistry jobRegistry) {
JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor();
postProcessor.setJobRegistry(jobRegistry);
return postProcessor;
} 次の例は、XML で定義されたジョブに JobRegistryBeanPostProcessor を含める方法を示しています。
<bean id="jobRegistryBeanPostProcessor" class="org.spr...JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean> 厳密には必要ではありませんが、この例のポストプロセッサーには id が与えられているため、子コンテキストに含めることができ (たとえば、親 Bean 定義として)、そこで作成されたすべてのジョブも自動的に登録されます。
使用すべきではない バージョン 5.2 以降、 |
JobRegistrySmartInitializingSingleton
これは、ジョブレジストリ内のすべてのシングルトンジョブを登録する SmartInitializingSingleton です。
Java
XML
次の例は、Java で JobRegistrySmartInitializingSingleton を定義する方法を示しています。
@Bean
public JobRegistrySmartInitializingSingleton jobRegistrySmartInitializingSingleton(JobRegistry jobRegistry) {
return new JobRegistrySmartInitializingSingleton(jobRegistry);
} 次の例は、JobRegistrySmartInitializingSingleton を XML で定義する方法を示しています。
<bean class="org.springframework.batch.core.configuration.support.JobRegistrySmartInitializingSingleton">
<property name="jobRegistry" ref="jobRegistry" />
</bean>AutomaticJobRegistrar
これは、子コンテキストを作成し、作成時にそれらのコンテキストからジョブを登録するライフサイクルコンポーネントです。これを行う利点の 1 つは、子コンテキストのジョブ名がレジストリ内でグローバルに一意である必要がある一方で、それらの依存関係に「自然な」名前を付けることができることです。たとえば、それぞれが 1 つのジョブのみを持ち、すべて同じ Bean 名を持つ ItemReader の異なる定義 ( reader など) を持つ一連の XML 構成ファイルを作成できます。これらすべてのファイルが同じコンテキストにインポートされた場合、リーダーの定義が衝突して相互に上書きされますが、自動レジストラーを使用すると、これが回避されます。これにより、アプリケーションの個別のモジュールから提供されたジョブを簡単に統合できます。
Java
XML
次の例は、Java で定義されたジョブに AutomaticJobRegistrar を含める方法を示しています。
@Bean
public AutomaticJobRegistrar registrar() {
AutomaticJobRegistrar registrar = new AutomaticJobRegistrar();
registrar.setJobLoader(jobLoader());
registrar.setApplicationContextFactories(applicationContextFactories());
registrar.afterPropertiesSet();
return registrar;
} 次の例は、XML で定義されたジョブに AutomaticJobRegistrar を含める方法を示しています。
<bean class="org.spr...AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.spr...ClasspathXmlApplicationContextsFactoryBean">
<property name="resources" value="classpath*:/config/job*.xml" />
</bean>
</property>
<property name="jobLoader">
<bean class="org.spr...DefaultJobLoader">
<property name="jobRegistry" ref="jobRegistry" />
</bean>
</property>
</bean> レジストラには 2 つの必須プロパティがあります。ApplicationContextFactory の配列 (前の例では便利なファクトリ Bean から作成されています) と JobLoader です。JobLoader は、子コンテキストのライフサイクルの管理と JobRegistry でのジョブの登録を担当します。
ApplicationContextFactory は、子コンテキストの作成を担当します。最も一般的な使用箇所は (前の例のように) ClassPathXmlApplicationContextFactory を使用することです。このファクトリの機能の 1 つは、デフォルトで、構成の一部を親コンテキストから子コンテキストにコピーすることです。たとえば、子で PropertyPlaceholderConfigurer または AOP 構成を再定義する必要はありませんが、親と同じでなければなりません。
AutomaticJobRegistrar を JobRegistryBeanPostProcessor と組み合わせて使用できます ( DefaultJobLoader も使用する場合)。たとえば、メインの親コンテキストと子ロケーションでジョブが定義されている場合、これが望ましい場合があります。
JobOperator
前述のように、JobRepository はメタデータに対する CRUD 操作を提供し、JobExplorer はメタデータに対する読み取り専用操作を提供します。ただし、これらの操作は、バッチオペレーターによって一般的に行われるように、ジョブの停止、再開、要約などの一般的な監視タスクを実行するために一緒に使用する場合に最も役立ちます。Spring Batch は、JobOperator インターフェースで次の型の操作を提供します。
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
} 上記の操作は、JobLauncher、JobRepository、JobExplorer、JobRegistry など、さまざまなインターフェースのメソッドを表しています。このため、提供されている JobOperator の実装 (SimpleJobOperator) には多くの依存関係があります。
Java
XML
次の例は、Java での SimpleJobOperator の一般的な Bean 定義を示しています。
/**
* All injected dependencies for this bean are provided by the @EnableBatchProcessing
* infrastructure out of the box.
*/
@Bean
public SimpleJobOperator jobOperator(JobExplorer jobExplorer,
JobRepository jobRepository,
JobRegistry jobRegistry,
JobLauncher jobLauncher) {
SimpleJobOperator jobOperator = new SimpleJobOperator();
jobOperator.setJobExplorer(jobExplorer);
jobOperator.setJobRepository(jobRepository);
jobOperator.setJobRegistry(jobRegistry);
jobOperator.setJobLauncher(jobLauncher);
return jobOperator;
} 次の例は、XML での SimpleJobOperator の一般的な Bean 定義を示しています。
<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean> バージョン 5.0 の時点で、@EnableBatchProcessing アノテーションは、ジョブオペレーター Bean をアプリケーションコンテキストに自動的に登録します。
| ジョブリポジトリでテーブルプレフィックスを設定する場合は、ジョブエクスプローラーでも忘れずに設定してください。 |
JobParametersIncrementer
JobOperator のほとんどのメソッドは自明であり、インターフェースの Javadoc でより詳細な説明を見つけることができます。ただし、startNextInstance メソッドは注目に値します。このメソッドは、常に Job の新しいインスタンスを開始します。これは、JobExecution に深刻な課題があり、Job を最初からやり直す必要がある場合に非常に役立ちます。JobLauncher (新しい JobInstance をトリガーする新しい JobParameters オブジェクトが必要) とは異なり、パラメーターが以前のパラメーターのセットと異なる場合、startNextInstance メソッドは Job に関連付けられた JobParametersIncrementer を使用して、Job を新しいインスタンスに強制します。
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}JobParametersIncrementer の契約は、JobParameters オブジェクトが与えられると、それに含まれる必要な値をインクリメントして「次の」 JobParameters オブジェクトを返すことです。フレームワークは JobParameters へのどの変更が「次の」インスタンスになるかを知る方法がないため、この戦略は役に立ちます。例: JobParameters の唯一の値が日付であり、次のインスタンスを作成する必要がある場合、その値を 1 日または 1 週間ずつ増やす必要がありますか (たとえば、ジョブが毎週の場合)? 次の例に示すように、Job の識別に役立つ数値についても同じことが言えます。
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
} この例では、run.id のキーを持つ値を使用して、JobInstances を区別しています。渡された JobParameters が null の場合、Job は以前に実行されたことがないため、初期状態を返すことができると見なすことができます。ただし、そうでない場合は、古い値が取得され、1 つインクリメントされて返されます。
Java
XML
Java で定義されたジョブの場合、次のように、ビルダーで提供される incrementer メソッドを介してインクリメンタを Job に関連付けることができます。
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.incrementer(sampleIncrementer())
...
.build();
}XML で定義されたジョブの場合、次のように、名前空間の incrementer 属性を通じてインクリメンタを Job に関連付けることができます。
<job id="footballJob" incrementer="sampleIncrementer">
...
</job>ジョブの停止
JobOperator の最も一般的な使用例の 1 つは、ジョブを正常に停止することです。
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next()); 特にビジネスサービスなど、フレームワークが制御できない開発者コードで現在実行が行われている場合は、即時シャットダウンを強制する方法がないため、シャットダウンは即時ではありません。ただし、制御がフレームワークに戻されるとすぐに、現在の StepExecution のステータスを BatchStatus.STOPPED に設定して保存し、終了する前に JobExecution に対して同じことを行います。
ジョブの中止
FAILED であるジョブ実行は再開できます (Job が再開可能な場合)。ステータスが ABANDONED のジョブ実行は、フレームワークによって再開できません。ABANDONED ステータスは、ステップ実行でも使用され、再起動されたジョブ実行でスキップ可能としてマークされます。ジョブの実行中に、前回の失敗したジョブ実行で ABANDONED とマークされたステップが検出された場合、ジョブは次のステップに進みます (ジョブフロー定義とステップ実行の終了ステータスによって決定されます)。
プロセスが停止した場合(kill -9 またはサーバー障害)、ジョブはもちろん実行されていませんが、プロセスが停止する前に誰も通知しなかったため、JobRepository は知る方法がありません。実行が失敗したか、中止されたと見なされる必要があることを手動で通知する必要があります(ステータスを FAILED または ABANDONED に変更します)。これはビジネス上の決定であり、自動化する方法はありません。再起動可能であり、再起動データが有効であることがわかっている場合にのみ、状況を FAILED に変更してください。

