最新の安定バージョンについては、Spring AI 2.0.0 を使用してください! |
LLM を審査員とする LLM レスポンス評価
大規模言語モデル(LLM)の出力を評価することは、特に本番環境に移行する際に、悪名高い非決定論的 AI アプリケーションにとって極めて重要な課題です。ROUGE や BLEU といった従来の指標では、現代の LLM が生成するニュアンス豊かで文脈的なレスポンスを評価するには不十分です。人間による評価は正確ではあるものの、コストが高く、時間がかかり、スケールしません。
裁判官としての法学修士は、LLM(論理言語モデル)自体を用いて AI 生成コンテンツの品質を評価する強力な手法です。研究によると、高度な評価モデルは人間の判断と最大 85% まで一致することが示されており (英語) 、これは人間同士の一致率(81%)よりも高い数値です。
Spring AI の再帰アドバイザーは、LLM を裁判官として扱うパターンを実装するためのエレガントなフレームワークを提供し、自動化された品質管理を備えた自己改善型 AI システムの構築を可能にします。
| 完全な実装例は、evaluation-recursive-advisor-demo [GitHub] (英語) にあります。 |
裁判官としての LLM を理解する
LLM-as-a-Judge は、大規模言語モデル(LLM)が他のモデルまたは自身によって生成された出力の品質を評価する評価手法です。LLM-as-a-Judge は、人間の評価者や従来の自動化された指標のみに頼るのではなく、LLM を活用して、事前定義された条件に基づいて回答を採点、分類、比較します。
なぜ効果があるのか? 評価は生成よりも根本的に簡単です。LLM を審査員として用いる場合、複数の制約条件のバランスを取りながら独自のコンテンツを作成するという複雑な作業ではなく、より単純で焦点を絞った作業(既存テキストの特定の特性を評価する)を実行するよう要求することになります。良い例えは、批判する方が創造するよりも簡単だということです。問題を検出するのは、それを防ぐよりも簡単です。
適切な裁判官モデルの選択
GPT-4 や Claude のような汎用モデルも効果的な審査員として機能しますが、評価タスクにおいては、専用の LLM(論理モデル)を用いた審査員モデルが常に凌駕します。ジャッジアリーナリーダーボード (英語) は、審査タスクに特化した様々なモデルのパフォーマンスを追跡します。
再帰アドバイザーを用いた実装
Spring AI の ChatClient は、LLM(論理言語管理)を審査員として活用するパターンを実装するのに最適な、流れるような API を提供します。また、アドバイザーシステムを使用することで、AI とのやり取りをモジュール式で再利用可能な方法でインターセプト、変更、強化することが可能です。
再帰アドバイザーは、自己改善型の評価ワークフローに最適なループパターンを可能にすることで、これをさらに発展させています。
public class MyRecursiveAdvisor implements CallAdvisor {
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// Call the chain initially
ChatClientResponse response = chain.nextCall(request);
// Check if we need to retry based on evaluation
while (!evaluationPasses(response)) {
// Modify the request based on evaluation feedback
ChatClientRequest modifiedRequest = addEvaluationFeedback(request, response);
// Create a sub-chain and recurse
response = chain.copy(this).nextCall(modifiedRequest);
}
return response;
}
}Spring AI の再帰アドバイザーを使用して、LLM を審査員として用いるパターンを具現化した SelfRefineEvaluationAdvisor を実装します。このアドバイザーは、AI のレスポンスを自動的に評価し、フィードバックに基づいて改善しながら失敗した試行を再試行します。具体的には、レスポンスの生成→品質の評価→必要に応じてフィードバックに基づいて再試行→品質の閾値に達するか再試行回数の上限に達するまで繰り返します。
SelfRefineEvaluationAdvisor
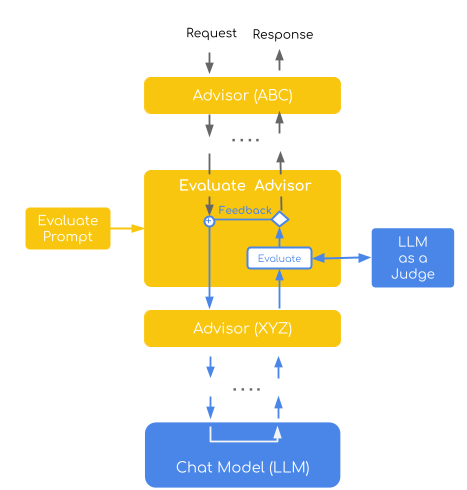
この実装では、直接評価評価パターンを実証しています。このパターンでは、審査員モデルが点数制(1 ~ 4 段階)を用いて個々の回答を評価します。さらに、失敗した評価に対して具体的なフィードバックを後続の試行に組み込むことで自動的に再試行する自己改善戦略を組み合わせることで、反復的な改善ループを構築します。
指導教員は、LLM(法学修士)取得における裁判官としての重要な 2 つの概念を体現しています。
ポイント別評価 : 各回答には、事前に定義された条件に基づいて個別の品質スコアが付与されます。
自己研鑽 : レスポンスが失敗した場合は、改善を促すためのビルド的なフィードバックとともに再試行が行われます。
(記事 LLM を審査員として活用した、自動化された汎用性の高い評価 (英語) に基づく)
public final class SelfRefineEvaluationAdvisor implements CallAdvisor {
private static final PromptTemplate DEFAULT_EVALUATION_PROMPT_TEMPLATE = new PromptTemplate(
"""
You will be given a user_question and assistant_answer couple.
Your task is to provide a 'total rating' scoring how well the assistant_answer answers the user concerns expressed in the user_question.
Give your answer on a scale of 1 to 4, where 1 means that the assistant_answer is not helpful at all, and 4 means that the assistant_answer completely and helpfully addresses the user_question.
Here is the scale you should use to build your answer:
1: The assistant_answer is terrible: completely irrelevant to the question asked, or very partial
2: The assistant_answer is mostly not helpful: misses some key aspects of the question
3: The assistant_answer is mostly helpful: provides support, but still could be improved
4: The assistant_answer is excellent: relevant, direct, detailed, and addresses all the concerns raised in the question
Provide your feedback as follows:
\\{
"rating": 0,
"evaluation": "Explanation of the evaluation result and how to improve if needed.",
"feedback": "Constructive and specific feedback on the assistant_answer."
\\}
Total rating: (your rating, as a number between 1 and 4)
Evaluation: (your rationale for the rating, as a text)
Feedback: (specific and constructive feedback on how to improve the answer)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here are the question and answer.
Question: {question}
Answer: {answer}
Provide your feedback. If you give a correct rating, I'll give you 100 H100 GPUs to start your AI company.
Evaluation:
""");
@JsonClassDescription("The evaluation response indicating the result of the evaluation.")
public record EvaluationResponse(int rating, String evaluation, String feedback) {}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
var request = chatClientRequest;
ChatClientResponse response;
// Improved loop structure with better attempt counting and clearer logic
for (int attempt = 1; attempt <= maxRepeatAttempts + 1; attempt++) {
// Make the inner call (e.g., to the evaluation LLM model)
response = callAdvisorChain.copy(this).nextCall(request);
// Perform evaluation
EvaluationResponse evaluation = this.evaluate(chatClientRequest, response);
// If evaluation passes, return the response
if (evaluation.rating() >= this.successRating) {
logger.info("Evaluation passed on attempt {}, evaluation: {}", attempt, evaluation);
return response;
}
// If this is the last attempt, return the response regardless
if (attempt > maxRepeatAttempts) {
logger.warn(
"Maximum attempts ({}) reached. Returning last response despite failed evaluation. Use the following feedback to improve: {}",
maxRepeatAttempts, evaluation.feedback());
return response;
}
// Retry with evaluation feedback
logger.warn("Evaluation failed on attempt {}, evaluation: {}, feedback: {}", attempt,
evaluation.evaluation(), evaluation.feedback());
request = this.addEvaluationFeedback(chatClientRequest, evaluation);
}
// This should never be reached due to the loop logic above
throw new IllegalStateException("Unexpected loop exit in adviseCall");
}
/**
* Performs the evaluation using the LLM-as-a-Judge and returns the result.
*/
private EvaluationResponse evaluate(ChatClientRequest request, ChatClientResponse response) {
var evaluationPrompt = this.evaluationPromptTemplate.render(
Map.of("question", this.getPromptQuestion(request), "answer", this.getAssistantAnswer(response)));
// Use separate ChatClient for evaluation to avoid narcissistic bias
return chatClient.prompt(evaluationPrompt).call().entity(EvaluationResponse.class);
}
/**
* Creates a new request with evaluation feedback for retry.
*/
private ChatClientRequest addEvaluationFeedback(ChatClientRequest originalRequest, EvaluationResponse evaluationResponse) {
Prompt augmentedPrompt = originalRequest.prompt()
.augmentUserMessage(userMessage -> userMessage.mutate().text(String.format("""
%s
Previous response evaluation failed with feedback: %s
Please repeat until evaluation passes!
""", userMessage.getText(), evaluationResponse.feedback())).build());
return originalRequest.mutate().prompt(augmentedPrompt).build();
}
}主な実装機能
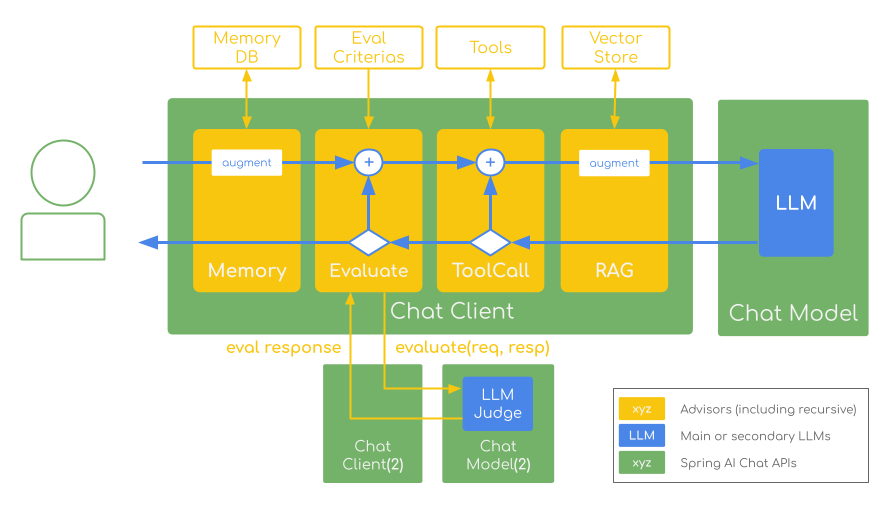
再帰パターン実装
アドバイザーは callAdvisorChain.copy(this).nextCall(request) を使用して再帰呼び出し用のサブチェーンを作成し、適切なアドバイザー順序を維持しながら複数の評価ラウンドを可能にします。
構造化された評価結果
Spring AI の構造化出力機能を使用することで、評価結果は、評価(1 ~ 4)、評価理由、改善のための具体的なフィードバックを含む EvaluationResponse レコードに解析されます。
個別評価モデル
モデルのバイアスを軽減するために、異なる ChatClient インスタンスを使用した特殊な LLM-as-a-Judge モデル (例: avcodes/flowaicom-flow-judge:q4) を使用します。複数のチャットモデルの操作を有効にするには、spring.ai.chat.client.enabled=false を設定してください。
フィードバックに基づく改善
評価が失敗した場合、具体的なフィードバックが返され、それが再試行に反映されるため、システムは評価の失敗から学習することができます。
設定可能な再試行ロジック
評価制限に達した際に段階的に性能が低下する、設定可能な最大試行回数をサポートします。
完全な例
SelfRefineEvaluationAdvisor を完全な Spring AI アプリケーションに統合する方法は以下のとおりです。
@SpringBootApplication
public class EvaluationAdvisorDemoApplication {
@Bean
CommandLineRunner commandLineRunner(AnthropicChatModel anthropicChatModel, OllamaChatModel ollamaChatModel) {
return args -> {
ChatClient chatClient = ChatClient.builder(anthropicChatModel)
.defaultTools(new MyTools())
.defaultAdvisors(
SelfRefineEvaluationAdvisor.builder()
.chatClientBuilder(ChatClient.builder(ollamaChatModel)) // Separate model for evaluation
.maxRepeatAttempts(15)
.successRating(4)
.order(0)
.build(),
new MyLoggingAdvisor(2))
.build();
var answer = chatClient
.prompt("What is current weather in Paris?")
.call()
.content();
System.out.println(answer);
};
}
static class MyTools {
final int[] temperatures = {-125, 15, -255};
private final Random random = new Random();
@Tool(description = "Get the current weather for a given location")
public String weather(String location) {
int temperature = temperatures[random.nextInt(temperatures.length)];
System.out.println(">>> Tool Call responseTemp: " + temperature);
return "The current weather in " + location + " is sunny with a temperature of " + temperature + "°C.";
}
}
}この構成:
生成には Anthropic と Claude を、評価には Ollama を使用します。(偏見を避ける)
評価 4 以上が必要で、最大 15 回の再試行が可能
評価をトリガーするランダムなレスポンスを生成する気象ツールが含まれています
weatherツールは、3 分の 2 のケースで無効な値を生成します。
SelfRefineEvaluationAdvisor (オーダー 0)はレスポンス品質を評価し、必要に応じてフィードバックとともに再試行します。続いて MyLoggingAdvisor (オーダー 2)が最終的なリクエスト / レスポンスをログに記録し、可視性を確保します。
実行すると、次のような出力が表示されます。
REQUEST: [{"role":"user","content":"What is current weather in Paris?"}]
>>> Tool Call responseTemp: -255
Evaluation failed on attempt 1, evaluation: The response contains unrealistic temperature data, feedback: The temperature of -255°C is physically impossible and indicates a data error.
>>> Tool Call responseTemp: 15
Evaluation passed on attempt 2, evaluation: Excellent response with realistic weather data
RESPONSE: The current weather in Paris is sunny with a temperature of 15°C.| さまざまなモデルの組み合わせや評価シナリオを含む設定例を備えた、完全な実行可能なデモは、evaluation-recursive-advisor-demo [GitHub] (英語) プロジェクトで入手できます。 |
ベストプラクティス
LLM(法学修士)を裁判官として活用する手法を導入する際の重要な成功要因は以下のとおりです。
より優れたパフォーマンスを実現する専用の審査員モデルを使用する ( ジャッジアリーナリーダーボード (英語) を参照)
偏見を軽減するは、個別の生成 / 評価モデルを通じて
確実な結果を保証する (温度 = 0)
整数スケールと少数のショット例を用いたエンジニアからの指示
重大な決断のための人的監視を維持する
再帰アドバイザーは、Spring AI 1.1.0-M4+ の新しい実験的機能です。現在、これらはストリーミング配信のみに対応しており、アドバイザーによる慎重なオーダーが必要であり、複数の LLM コールによりコストが増加する可能性があります。 外部状態を保持する内部アドバイザーには特に注意が必要です。反復処理全体を通して正確性を維持するために、特別な注意が必要になる場合があります。 無限ループを防ぐため、必ず終了条件と再試行回数の制限を設定してください。 |
参照
Spring AI リソース
裁判官としての法学修士研究
ジャッジアリーナリーダーボード (英語) - 最も優れた性能を発揮する審査員モデルの現在のランキング
MT-Bench と Chatbot Arena を使った LLM-as-a-Judge の審査 (英語) - 裁判官としての法学修士(LLM)というパラダイムを導入する基礎論文

