Apache Kafka バインダー
使用方法
Apache Kafka バインダーを使用するには、次の Maven の例に示すように、spring-cloud-stream-binder-kafka を Spring Cloud Stream アプリケーションへの依存関係として追加する必要があります。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>または、次の Maven の例に示すように、Spring Cloud Stream Kafka スターターを使用することもできます。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>概要
次の図は、Apache Kafka バインダーの動作を簡略化した図を示しています。
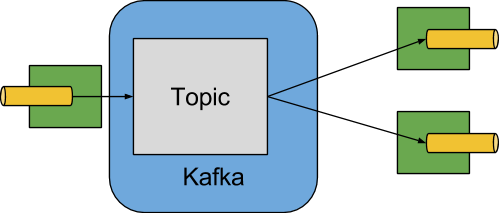
Apache Kafka バインダー実装は、各宛先を Apache Kafka トピックにマップします。コンシューマーグループは同じ Apache Kafka コンセプトに直接マップされます。パーティション分割も Apache Kafka パーティションに直接マップされます。
バインダーは現在、Apache Kafka kafka-clients バージョン 2.3.1 を使用しています。このクライアントは古いブローカーと通信できます (Kafka のドキュメントを参照) が、特定の機能が使用できない場合があります。例: 0.11.x.x より前のバージョンでは、ネイティブヘッダーはサポートされていません。また、0.11.x.x は autoAddPartitions プロパティをサポートしていません。
構成オプション
このセクションには、Apache Kafka バインダーで使用される構成オプションが含まれています。
バインダーに関連する一般的な構成オプションとプロパティについては、コアドキュメントのバインディングプロパティを参照 (英語) してください。
Kafka バインダーのプロパティ
- spring.cloud.stream.kafka.binder.brokers
Kafka バインダーが接続するブローカーのリスト。
デフォルト:
localhost.- spring.cloud.stream.kafka.binder.defaultBrokerPort
brokersは、ポート情報の有無にかかわらず指定されたホストを許可します(たとえば、host1,host2:port2)。これにより、ブローカーリストにポートが構成されていない場合のデフォルトポートが設定されます。デフォルト:
9092.- spring.cloud.stream.kafka.binder.configuration
バインダーによって作成されたすべてのクライアントに渡されるクライアントプロパティ(プロデューサーとコンシューマーの両方)のキー / 値マップ。これらのプロパティはプロデューサーとコンシューマーの両方で使用されるため、使用はセキュリティ設定などの共通のプロパティに制限する必要があります。この構成を通じて提供される不明な Kafka プロデューサーまたはコンシューマープロパティは除外され、伝播は許可されません。ここでのプロパティは、Boot で設定されたすべてのプロパティに優先します。
デフォルト: 空の地図。
- spring.cloud.stream.kafka.binder.consumerProperties
任意の Kafka クライアントコンシューマープロパティのキー / 値マップ。既知の Kafka コンシューマープロパティをサポートすることに加えて、未知のコンシューマープロパティもここで許可されます。ここでのプロパティは、boot および上記の
configurationプロパティで設定されたプロパティに優先します。デフォルト: 空の地図。
- spring.cloud.stream.kafka.binder.headers
バインダーによって転送されるカスタムヘッダーのリスト。
kafka-clientsバージョンが 0.11.0.0 未満の古いアプリケーション (⇐ 1.3.x) と通信する場合にのみ必要です。新しいバージョンでは、ヘッダーがネイティブにサポートされます。デフォルト: 空。
- spring.cloud.stream.kafka.binder.healthTimeout
パーティション情報の取得を待機する時間(秒単位)。このタイマーが期限切れになると、ヘルスはダウンとして報告します。
デフォルト: 10.
- spring.cloud.stream.kafka.binder.requiredAcks
ブローカーに必要な ack の数。プロデューサー
acksプロパティについては、Kafka のドキュメントを参照してください。デフォルト:
1.- spring.cloud.stream.kafka.binder.minPartitionCount
autoCreateTopicsまたはautoAddPartitionsが設定されている場合にのみ有効です。バインダーがデータを生成または消費するトピックに構成するパーティションのグローバル最小数。これは、プロデューサーのpartitionCount設定、またはプロデューサーのinstanceCount * concurrency設定の値(どちらか大きい場合)に置き換えることができます。デフォルト:
1.- spring.cloud.stream.kafka.binder.producerProperties
任意の Kafka クライアントプロデューサープロパティのキー / 値マップ。既知の Kafka プロデューサープロパティをサポートすることに加えて、未知のプロデューサープロパティもここで許可されます。ここでのプロパティは、boot および上記の
configurationプロパティで設定されたプロパティに優先します。デフォルト: 空の地図。
- spring.cloud.stream.kafka.binder.replicationFactor
autoCreateTopicsがアクティブな場合、自動作成されたトピックの複製係数。各バインディングでオーバーライドできます。2.4 より前のバージョンの Kafka ブローカーを使用している場合、この値は少なくとも 1に設定する必要があります。バージョン 3.0.8 以降、バインダーは-1をデフォルト値として使用します。これは、ブローカーの "default.replication.factor" プロパティを使用してレプリカの数を決定することを示しています。Kafka ブローカーの管理者に問い合わせて、最小のレプリケーション係数を必要とするポリシーが設定されているかどうかを確認します。その場合、通常、default.replication.factorはその値と一致するため、より大きなレプリケーション係数が必要な場合を除き、最小値の-1を使用する必要があります。デフォルト:
-1.- spring.cloud.stream.kafka.binder.autoCreateTopics
trueに設定すると、バインダーは新しいトピックを自動的に作成します。falseに設定されている場合、バインダーはすでに構成されているトピックに依存します。後者の場合、トピックが存在しないと、バインダーは開始できません。この設定は、ブローカーの auto.create.topics.enable設定とは独立しており、影響を与えません。サーバーがトピックを自動作成するように設定されている場合、デフォルトのブローカー設定でメタデータ取得リクエストの一部として作成される場合があります。デフォルト:
true.- spring.cloud.stream.kafka.binder.autoAddPartitions
trueに設定すると、バインダーは必要に応じて新しいパーティションを作成します。falseに設定されている場合、バインダーは、すでに構成されているトピックのパーティションサイズに依存します。ターゲットトピックのパーティション数が期待値よりも小さい場合、バインダーは開始できません。デフォルト:
false.- spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix
バインダーでのトランザクションを有効にします。Kafka ドキュメントの
transaction.idおよびspring-kafkaドキュメントのトランザクションを参照してください。トランザクションが有効になっている場合、個々のproducerプロパティは無視され、すべてのプロデューサーがspring.cloud.stream.kafka.binder.transaction.producer.*プロパティを使用します。デフォルトの
null(トランザクションなし)- spring.cloud.stream.kafka.binder.transaction.producer.*
トランザクションバインダー内のプロデューサーのグローバルプロデューサープロパティ。
spring.cloud.stream.kafka.binder.transaction.transactionIdPrefixと Kafka プロデューサーのプロパティ、およびすべてのバインダーでサポートされている一般的なプロデューサーのプロパティを参照してください。デフォルト: 個々のプロデューサーのプロパティを参照してください。
- spring.cloud.stream.kafka.binder.headerMapperBeanName
spring-messagingヘッダーと Kafka ヘッダーのマッピングに使用されるKafkaHeaderMapperの Bean 名。たとえば、ヘッダーに JSON 逆直列化を使用するBinderHeaderMapperBean の信頼できるパッケージをカスタマイズする場合にこれを使用します。このカスタムBinderHeaderMapperBean がこのプロパティを使用してバインダーで使用可能になっていない場合、バインダーは、バインダーによって作成されたデフォルトのBinderHeaderMapperにフォールバックする前に、型BinderHeaderMapperのkafkaBinderHeaderMapperという名前のヘッダーマッパー Bean を探します。デフォルト: なし。
- spring.cloud.stream.kafka.binder.considerDownWhenAnyPartitionHasNoLeader
データを受信しているコンシューマーに関係なく、トピック上のパーティションがリーダーなしで見つかった場合、バインダーヘルスを
downとして設定するフラグ。デフォルト:
false.- spring.cloud.stream.kafka.binder.certificateStoreDirectory
トラストストアまたはキーストア証明書の場所がクラスパス URL(
classpath:…)として指定されている場合、バインダーはリソースを JAR ファイル内のクラスパスの場所からファイルシステム上の場所にコピーします。ファイルは、このプロパティの値として指定された場所に移動されます。この場所は、アプリケーションを実行しているプロセスによって書き込み可能なファイルシステム上の既存のディレクトリである必要があります。この値が設定されておらず、証明書ファイルがクラスパスリソースである場合、System.getProperty("java.io.tmpdir")によって返されるようにシステムの一時ディレクトリに移動されます。この値が存在するが、ディレクトリがファイルシステム上に見つからないか、書き込み可能でない場合も同様です。デフォルト: なし。
Kafka コンシューマープロパティ
繰り返しを避けるために、Spring Cloud Stream は、spring.cloud.stream.kafka.default.consumer.<property>=<value> の形式ですべてのチャネルの値を設定することをサポートしています。 |
次のプロパティは Kafka コンシューマーでのみ使用可能であり、接頭辞 spring.cloud.stream.kafka.bindings.<channelName>.consumer. を付ける必要があります。
- admin.configuration
バージョン 2.1.1 以降、このプロパティは
topic.propertiesを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- admin.replicas- 割り当て
バージョン 2.1.1 以降、このプロパティは
topic.replicas-assignmentを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- admin.replication-factor
バージョン 2.1.1 以降、このプロパティは
topic.replication-factorを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- autoRebalanceEnabled
trueの場合、トピックパーティションはコンシューマーグループのメンバー間で自動的に再調整されます。falseの場合、各コンシューマーには、spring.cloud.stream.instanceCountおよびspring.cloud.stream.instanceIndexに基づいてパーティションの固定セットが割り当てられます。これには、spring.cloud.stream.instanceCountプロパティとspring.cloud.stream.instanceIndexプロパティの両方を、起動された各インスタンスで適切に設定する必要があります。この場合、spring.cloud.stream.instanceCountプロパティの値は通常 1 より大きくなければなりません。デフォルト:
true.- ackEachRecord
autoCommitOffsetがtrueの場合、この設定は各レコードが処理された後にオフセットをコミットするかどうかを決定します。デフォルトでは、オフセットはconsumer.poll()によって返されたレコードのバッチ内のすべてのレコードが処理された後にコミットされます。ポーリングによって返されるレコードの数は、コンシューマーconfigurationプロパティを通じて設定されるmax.poll.recordsKafka プロパティで制御できます。これをtrueに設定するとパフォーマンスが低下する可能性がありますが、そうすることで障害発生時にレコードが再配信される可能性が低くなります。また、バインダーrequiredAcksプロパティも参照してください。これもオフセットのコミットのパフォーマンスに影響します。このプロパティは 3.1 以降は非推奨となり、代わりにackModeを使用してください。ackModeが設定されておらず、バッチモードが有効になっていない場合は、RECORDackMode が使用されます。デフォルト:
false.- autoCommitOffset
バージョン 3.1 以降、このプロパティは非推奨になりました。代替案の詳細については、
ackModeを参照してください。メッセージが処理されたときにオフセットを自動コミットするかどうか。falseに設定されている場合、型org.springframework.kafka.support.Acknowledgmentヘッダーのキーkafka_acknowledgmentを持つヘッダーが受信メッセージに存在します。アプリケーションは、メッセージの確認にこのヘッダーを使用できます。詳細については、例のセクションを参照してください。このプロパティがfalseに設定されている場合、Kafka バインダーは ack モードをorg.springframework.kafka.listener.AbstractMessageListenerContainer.AckMode.MANUALに設定し、アプリケーションはレコードの確認を担当します。ackEachRecordも参照してください。デフォルト:
true.- ackMode
コンテナーの ack モードを指定します。これは、Spring Kafka で定義されている AckMode 列挙に基づいています。
ackEachRecordプロパティがtrueに設定されていて、コンシューマーがバッチモードでない場合、これはRECORDの ack モードを使用します。それ以外の場合は、このプロパティを使用して提供された ack モードを使用します。- autoCommitOnError
ポーリング可能なコンシューマーでは、
trueに設定されている場合、エラー時に常に自動コミットします。設定されていない場合(デフォルト)または false の場合、ポーリング可能なコンシューマーで自動コミットされません。このプロパティは、ポーリング可能なコンシューマーにのみ適用されることに注意してください。デフォルト: 未設定。
- resetOffsets
コンシューマーのオフセットを startOffset によって提供された値にリセットするかどうか。
KafkaBindingRebalanceListenerが指定されている場合は false にする必要があります。KafkaBindingRebalanceListener を使用するを参照してください。このプロパティの詳細については、オフセットのリセットを参照してください。デフォルト:
false.- startOffset
新しいグループの開始オフセット。許可される値:
earliestおよびlatest。コンシューマーグループがコンシューマー ' バインディング ' に対して明示的に設定されている場合 (spring.cloud.stream.bindings.<channelName>.group経由)、"startOffset" はearliestに設定されます。それ以外の場合は、anonymousコンシューマーグループに対してlatestに設定されます。このプロパティの詳細については、オフセットのリセットを参照してください。デフォルト: null(
earliestと同等)。- enableDlq
true に設定すると、コンシューマーの DLQ 動作が有効になります。デフォルトでは、エラーが発生するメッセージは
error.<destination>.<group>という名前のトピックに転送されます。DLQ トピック名は、dlqNameプロパティを設定するか、型DlqDestinationResolverの@Beanを定義することによって構成できます。これは、エラーの数が比較的少なく、元のトピック全体を再生するのが面倒な場合に、より一般的な Kafka 再生シナリオの代替オプションを提供します。詳細については、デッドレタートピック処理処理を参照してください。バージョン 2.0 以降、DLQ トピックに送信されるメッセージは、次のヘッダーで拡張されます:x-original-topic、x-exception-message、x-exception-stacktraceasbyte[]。デフォルトでは、失敗したレコードは、DLQ トピック内の元のレコードと同じパーティション番号に送信されます。その動作を変更する方法については、デッドレタートピックパーティションの選択を参照してください。destinationIsPatternがtrueの場合は許可されません。デフォルト:
false.- dlqPartitions
enableDlqが true で、このプロパティが設定されていない場合、プライマリトピックと同じ数のパーティションを持つデッドレタートピックが作成されます。通常、デッドレターレコードは、デッドレタートピック内の元のレコードと同じパーティションに送信されます。この動作は変更できます。デッドレタートピックパーティションの選択を参照してください。このプロパティが1に設定されていて、DqlPartitionFunctionBean がない場合、すべての送達不能レコードはパーティション0に書き込まれます。このプロパティが1より大きい場合、MUST はDlqPartitionFunctionBean を提供します。実際のパーティション数は、バインダーのminPartitionCountプロパティの影響を受けることに注意してください。デフォルト:
none- 構成
一般的な Kafka コンシューマープロパティを含むキーと値のペアを使用してマップします。Kafka コンシューマープロパティに加えて、他の構成プロパティをここに渡すことができます。たとえば、
spring.cloud.stream.kafka.bindings.input.consumer.configuration.foo=barなどのアプリケーションに必要ないくつかのプロパティ。ここではbootstrap.serversプロパティを設定できません。複数のクラスターに接続する必要がある場合は、マルチバインダーサポートを使用してください。デフォルト: 空の地図。
- dlqName
エラーメッセージを受信する DLQ トピックの名前。
デフォルト: null(指定されていない場合、エラーが発生するメッセージは
error.<destination>.<group>という名前のトピックに転送されます)。- dlqProducerProperties
これを使用して、DLQ 固有のプロデューサープロパティを設定できます。Kafka プロデューサープロパティを通じて使用できるすべてのプロパティは、このプロパティを通じて設定できます。コンシューマーでネイティブデコードが有効になっている場合 (つまり、useNativeDecoding: true)、アプリケーションは DLQ に対応するキー / 値シリアライザーを提供する必要があります。これは、
dlqProducerProperties.configuration.key.serializerおよびdlqProducerProperties.configuration.value.serializerの形式で提供する必要があります。デフォルト: デフォルトの Kafka プロデューサープロパティ。
- standardHeaders
受信チャネルアダプターによって入力される標準ヘッダーを示します。許可される値:
none、id、timestamp、またはboth。ネイティブの逆直列化を使用していて、メッセージを受信する最初のコンポーネントにid(JDBC メッセージストアを使用するように構成されたアグリゲーターなど)が必要な場合に便利です。デフォルト:
none- converterBeanName
RecordMessageConverterを実装する Bean の名前。デフォルトのMessagingMessageConverterを置き換えるために、受信チャネルアダプターで使用されます。デフォルト:
null- idleEventInterval
メッセージが最近受信されていないことを示すイベント間の間隔(ミリ秒単位)。これらのイベントを受信するには、
ApplicationListener<ListenerContainerIdleEvent>を使用してください。使用例については、サンプル: コンシューマーの一時停止と再開を参照してください。デフォルト:
30000- destinationIsPattern
true の場合、宛先は、ブローカーによってトピック名を照合するために使用される正規表現
Patternとして扱われます。true の場合、トピックはプロビジョニングされず、enableDlqは許可されません。これは、バインダーがプロビジョニングフェーズ中にトピック名を認識しないためです。パターンに一致する新しいトピックを検出するのにかかる時間は、コンシューマープロパティmetadata.max.age.msによって制御されることに注意してください。これは、(執筆時点では)デフォルトで 300,000ms(5 分)です。これは、上記のconfigurationプロパティを使用して構成できます。デフォルト:
false- topic.properties
新しいトピックをプロビジョニングするときに使用される Kafka トピックプロパティの
Map(たとえば、spring.cloud.stream.kafka.bindings.input.consumer.topic.properties.message.format.version=0.9.0.0)デフォルト: なし。
- topic.replicas- 割り当て
レプリカ割り当ての Map <Integer、List <Integer >>。キーはパーティション、値は割り当てです。新しいトピックをプロビジョニングするときに使用されます。
kafka-clientsjar のNewTopicJavadoc を参照してください。デフォルト: なし。
- topic.replication-factor
トピックをプロビジョニングするときに使用するレプリケーション係数。バインダー全体の設定を上書きします。
replicas-assignmentsが存在する場合は無視されます。デフォルト: none(バインダー全体のデフォルトである -1 が使用されます)。
- pollTimeout
ポーリング可能なコンシューマーでのポーリングに使用されるタイムアウト。
デフォルト: 5 秒。
- transactionManager
このバインディングのバインダーのトランザクションマネージャーをオーバーライドするために使用される
KafkaAwareTransactionManagerの Bean 名。通常、ChainedKafkaTransactionManaagerを使用して、別のトランザクションを Kafka トランザクションと同期する場合に必要です。レコードの消費と生成を 1 回だけ実行するには、コンシューマーとプロデューサーのバインディングをすべて同じトランザクションマネージャーで構成する必要があります。デフォルト: なし。
- txCommitRecovered
トランザクションバインダーを使用する場合、復元されたレコードのオフセット(たとえば、再試行が終了し、レコードがデッドレタートピックに送信された場合)は、デフォルトで新しいトランザクションを介してコミットされます。このプロパティを
falseに設定すると、リカバリされたレコードのオフセットのコミットが抑制されます。デフォルト: true。
オフセットのリセット
アプリケーションが起動すると、割り当てられた各パーティションの初期位置は、2 つのプロパティ startOffset と resetOffsets に依存します。resetOffsets が false の場合、通常の Kafka コンシューマー auto.offset.reset [Apache] (英語) セマンティクスが適用されます。つまり、バインディングのコンシューマーグループのパーティションにコミットされたオフセットがない場合、位置は earliest または latest です。デフォルトでは、明示的な group を使用したバインディングは earliest を使用し、匿名のバインディング(group を使用しない)は latest を使用します。これらのデフォルトは、startOffset バインディングプロパティを設定することで上書きできます。特定の group で初めてバインディングが開始されたとき、コミットされたオフセットはありません。コミットされたオフセットが存在しないもう 1 つの条件は、オフセットの有効期限が切れているかどうかです。最新のブローカー(2.1 以降)およびデフォルトのブローカープロパティでは、最後のメンバーがグループを離れてから 7 日後にオフセットの有効期限が切れます。詳細については、offsets.retention.minutes [Apache] (英語) ブローカーのプロパティを参照してください。
resetOffsets が true の場合、バインダーは、このバインディングがトピックから消費されたことがないかのように、ブローカーにコミットされたオフセットがない場合に適用されるセマンティクスと同様のセマンティクスを適用します。つまり、現在コミットされているオフセットは無視されます。
以下は、これが使用される可能性のある 2 つのユースケースです。
キーと値のペアを含む圧縮されたトピックからの消費。
resetOffsetsをtrueに、startOffsetをearliestに設定します。バインディングは、新しく割り当てられたすべてのパーティションでseekToBeginningを実行します。イベントを含むトピックから消費します。このトピックでは、このバインディングの実行中に発生するイベントのみに関心があります。
resetOffsetsをtrueに、startOffsetをlatestに設定します。バインディングは、新しく割り当てられたすべてのパーティションでseekToEndを実行します。
| 最初の割り当て後にリバランスが発生した場合、シークは、最初の割り当て中に割り当てられなかった、新しく割り当てられたパーティションに対してのみ実行されます。 |
トピックオフセットの詳細な制御については、KafkaBindingRebalanceListener を使用するを参照してください。リスナーが提供されている場合、resetOffsets を true に設定しないでください。設定しないと、エラーが発生します。
バッチの消費
バージョン 3.0 以降、spring.cloud.stream.binding.<name>.consumer.batch-mode が true に設定されている場合、Kafka Consumer のポーリングによって受信されたすべてのレコードは、List<?> としてリスナーメソッドに提示されます。それ以外の場合、メソッドは一度に 1 つのレコードで呼び出されます。バッチのサイズは、Kafka コンシューマープロパティ max.poll.records、fetch.min.bytes、fetch.max.wait.ms によって制御されます。詳細については、Kafka のドキュメントを参照してください。
バッチモードは @StreamListener ではサポートされていないことに注意してください。これは、新しい関数型プログラミングモデルでのみ機能します。
バッチモードを使用する場合、バインダー内での再試行はサポートされないため、maxAttempts は 1 にオーバーライドされます。バインダーで再試行する同様の機能を実現するように SeekToCurrentBatchErrorHandler を構成できます(ListenerContainerCustomizer を使用)。手動の AckMode を使用し、Ackowledgment.nack(index, sleep) を呼び出して、部分バッチのオフセットをコミットし、残りのレコードを再配信することもできます。これらの手法の詳細については、Spring for Apache Kafka ドキュメントを参照してください。 |
Kafka プロデューサーのプロパティ
繰り返しを避けるために、Spring Cloud Stream は、spring.cloud.stream.kafka.default.producer.<property>=<value> の形式ですべてのチャネルの値を設定することをサポートしています。 |
次のプロパティは Kafka プロデューサーのみが使用でき、接頭辞 spring.cloud.stream.kafka.bindings.<channelName>.producer. を付ける必要があります。
- admin.configuration
バージョン 2.1.1 以降、このプロパティは
topic.propertiesを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- admin.replicas- 割り当て
バージョン 2.1.1 以降、このプロパティは
topic.replicas-assignmentを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- admin.replication-factor
バージョン 2.1.1 以降、このプロパティは
topic.replication-factorを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- bufferSize
Kafka プロデューサーが送信する前にバッチ処理を試みるデータ量の上限(バイト単位)。
デフォルト:
16384.- 同期
プロデューサーが同期しているかどうか。
デフォルト:
false.- sendTimeoutExpression
同期公開が有効になっている場合に ack を待機する時間を評価するために使用される送信メッセージに対して評価される SpEL 式(たとえば、
headers['mySendTimeout'])。タイムアウトの値はミリ秒単位です。3.0 より前のバージョンでは、ネイティブエンコーディングが使用されていない限り、ペイロードを使用できませんでした。この式が評価されるまでに、ペイロードはすでにbyte[]の形式であったためです。これで、ペイロードが変換される前に式が評価されます。デフォルト:
none.- batchTimeout
メッセージを送信する前に、プロデューサーが同じバッチにさらに多くのメッセージが蓄積されるのを待機する時間。(通常、プロデューサーはまったく待機せず、前の送信の進行中に蓄積されたすべてのメッセージを送信するだけです)ゼロ以外の値は、待ち時間を犠牲にしてスループットを向上させる可能性があります。
デフォルト:
0.- messageKeyExpression
生成された Kafka メッセージのキーを設定するために使用される発信メッセージ(たとえば、
headers['myKey'])に対して評価された SpEL 式。3.0 より前のバージョンでは、ネイティブエンコーディングが使用されていない限り、ペイロードを使用できませんでした。この式が評価されるまでに、ペイロードはすでにbyte[]の形式であったためです。これで、ペイロードが変換される前に式が評価されます。通常のプロセッサー(Function<String, String>またはFunction<Message<?>, Message<?>)の場合、生成されたキーがトピックからの受信キーと同じである必要がある場合、このプロパティは次のように設定できます。spring.cloud.stream.kafka.bindings.<output-binding-name>.producer.messageKeyExpression: headers['kafka_receivedMessageKey']リアクティブ機能について覚えておくべき重要な警告があります。その場合、受信メッセージから発信メッセージにヘッダーを手動でコピーするのはアプリケーションの責任です。ヘッダーを設定できます。例:myKeyを使用し、上記のようにheaders['myKey']を使用するか、便宜上、KafkaHeaders.MESSAGE_KEYヘッダーを設定するだけで、このプロパティを設定する必要はまったくありません。デフォルト:
none.- headerPatterns
ProducerRecordの KafkaHeadersにマップされる Spring メッセージングヘッダーに一致する単純なパターンのコンマ区切りリスト。パターンは、ワイルドカード文字(アスタリスク)で開始または終了できます。パターンは、接頭辞!を付けることで無効にできます。一致は最初の一致(正または負)の後に停止します。たとえば、!ask,as*はashを渡しますが、askは渡しません。idとtimestampはマップされません。デフォルト:
*(すべてのヘッダー -idとtimestampを除く)- 構成
一般的な Kafka プロデューサープロパティを含むキー / 値ペアを使用してマップします。ここでは
bootstrap.serversプロパティを設定できません。複数のクラスターに接続する必要がある場合は、マルチバインダーサポートを使用してください。デフォルト: 空の地図。
- topic.properties
新しいトピックをプロビジョニングするときに使用される Kafka トピックプロパティの
Map(たとえば、spring.cloud.stream.kafka.bindings.output.producer.topic.properties.message.format.version=0.9.0.0)- topic.replicas- 割り当て
レプリカ割り当ての Map <Integer、List <Integer >>。キーはパーティション、値は割り当てです。新しいトピックをプロビジョニングするときに使用されます。
kafka-clientsjar のNewTopicJavadoc を参照してください。デフォルト: なし。
- topic.replication-factor
トピックをプロビジョニングするときに使用するレプリケーション係数。バインダー全体の設定を上書きします。
replicas-assignmentsが存在する場合は無視されます。デフォルト: none(バインダー全体のデフォルトである -1 が使用されます)。
- useTopicHeader
trueに設定すると、デフォルトのバインディング宛先(トピック名)が送信メッセージのKafkaHeaders.TOPICメッセージヘッダーの値で上書きされます。ヘッダーが存在しない場合は、デフォルトのバインディング宛先が使用されます。デフォルト:
false.- recordMetadataChannel
正常な送信結果の送信先となる
MessageChannelの Bean 名。Bean はアプリケーションコンテキストに存在する必要があります。チャネルに送信されるメッセージは、追加のヘッダーKafkaHeaders.RECORD_METADATAを含む送信済みメッセージ(変換後)です。ヘッダーには、Kafka クライアントによって提供されるRecordMetadataオブジェクトが含まれています。これには、トピックでレコードが書き込まれたパーティションとオフセットが含まれます。ResultMetadata meta = sendResultMsg.getHeaders().get(KafkaHeaders.RECORD_METADATA, RecordMetadata.class)失敗した送信は、プロデューサーエラーチャネルに送信されます(構成されている場合)。エラーチャネルを参照してください。
デフォルト: null。
Kafka バインダーは、プロデューサーの partitionCount 設定をヒントとして使用して、指定されたパーティション数でトピックを作成します(minPartitionCount と組み合わせて、2 つのうち最大のものが使用される値です)。大きい方の値が使用されるため、バインダー用の minPartitionCount とアプリケーション用の partitionCount の両方を構成する場合は注意が必要です。パーティション数が少ないトピックがすでに存在し、autoAddPartitions が無効(デフォルト)の場合、バインダーは開始に失敗します。パーティション数が少ないトピックがすでに存在し、autoAddPartitions が有効になっている場合は、新しいパーティションが追加されます。最大数(minPartitionCount または partitionCount)よりも多くのパーティションを持つトピックがすでに存在する場合は、既存のパーティション数が使用されます。 |
- 圧縮
compression.typeプロデューサープロパティを設定します。サポートされている値はnone、gzip、snappy、lz4、zstdです。Spring for Apache Kafka ドキュメントで説明したように、kafka-clientsjar を 2.1.0(またはそれ以降)にオーバーライドし、zstd圧縮を使用する場合は、spring.cloud.stream.kafka.bindings.<binding-name>.producer.configuration.compression.type=zstdを使用します。デフォルト:
none.- transactionManager
このバインディングのバインダーのトランザクションマネージャーをオーバーライドするために使用される
KafkaAwareTransactionManagerの Bean 名。通常、ChainedKafkaTransactionManaagerを使用して、別のトランザクションを Kafka トランザクションと同期する場合に必要です。レコードの消費と生成を 1 回だけ実行するには、コンシューマーとプロデューサーのバインディングをすべて同じトランザクションマネージャーで構成する必要があります。デフォルト: なし。
- closeTimeout
プロデューサーを閉じるときに待機する秒数のタイムアウト。
デフォルト:
30- allowNonTransactional
通常、トランザクションバインダーに関連付けられているすべての出力バインディングは、まだ処理されていない場合は、新しいトランザクションで公開されます。このプロパティを使用すると、その動作をオーバーライドできます。true に設定すると、この出力バインディングに公開されたレコードは、すでに処理中でない限り、トランザクションで実行されません。
デフォルト:
false
使用例
このセクションでは、特定のシナリオでの前述のプロパティの使用箇所を示します。
サンプル: ackMode を MANUAL に設定し、手動確認に依存する
この例は、コンシューマーアプリケーションでオフセットを手動で確認する方法を示しています。
この例では、spring.cloud.stream.kafka.bindings.input.consumer.ackMode を MANUAL に設定する必要があります。例として、対応する入力チャネル名を使用してください。
@SpringBootApplication
@EnableBinding(Sink.class)
public class ManuallyAcknowdledgingConsumer {
public static void main(String[] args) {
SpringApplication.run(ManuallyAcknowdledgingConsumer.class, args);
}
@StreamListener(Sink.INPUT)
public void process(Message<?> message) {
Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (acknowledgment != null) {
System.out.println("Acknowledgment provided");
acknowledgment.acknowledge();
}
}
}サンプル: セキュリティ構成
Apache Kafka 0.9 は、クライアントとブローカー間の安全な接続をサポートします。この機能を活用するには、Confluent ドキュメントの Apache Kafka ドキュメント (英語) のガイドラインと Kafka 0.9 セキュリティガイドラインに従ってください。バインダーによって作成されたすべてのクライアントのセキュリティプロパティを設定するには、spring.cloud.stream.kafka.binder.configuration オプションを使用します。
例: security.protocol を SASL_SSL に設定するには、次のプロパティを設定します。
spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_SSL他のすべてのセキュリティプロパティも同様の方法で設定できます。
Kerberos を使用する場合は、JAAS 構成を作成および参照するためのリファレンスドキュメントの指示に従 [Apache] (英語) ってください。
Spring Cloud Stream は、JAAS 構成ファイルと Spring Boot プロパティを使用して、アプリケーションへの JAAS 構成情報の受け渡しをサポートします。
JAAS および(オプションで)krb5 ファイルの場所は、システムプロパティを使用して Spring Cloud Stream アプリケーション用に設定できます。次の例は、JAAS 構成ファイルを使用して SASL および Kerberos で Spring Cloud Stream アプリケーションを起動する方法を示しています。
java -Djava.security.auth.login.config=/path.to/kafka_client_jaas.conf -jar log.jar \
--spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXTJAAS 構成ファイルを持つ代わりに、Spring Cloud Stream は、Spring Boot プロパティを使用して Spring Cloud Stream アプリケーションの JAAS 構成をセットアップするためのメカニズムを提供します。
次のプロパティを使用して、Kafka クライアントのログインコンテキストを構成できます。
- spring.cloud.stream.kafka.binder.jaas.loginModule
ログインモジュール名。通常は設定する必要はありません。
デフォルト:
com.sun.security.auth.module.Krb5LoginModule.- spring.cloud.stream.kafka.binder.jaas.controlFlag
ログインモジュールの制御フラグ。
デフォルト:
required.- spring.cloud.stream.kafka.binder.jaas.options
ログインモジュールオプションを含むキーと値のペアでマップします。
デフォルト: 空の地図。
次の例は、Spring Boot 構成プロパティを使用して SASL および Kerberos で Spring Cloud Stream アプリケーションを起動する方法を示しています。
java --spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.autoCreateTopics=false \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT \
--spring.cloud.stream.kafka.binder.jaas.options.useKeyTab=true \
--spring.cloud.stream.kafka.binder.jaas.options.storeKey=true \
--spring.cloud.stream.kafka.binder.jaas.options.keyTab=/etc/security/keytabs/kafka_client.keytab \
--spring.cloud.stream.kafka.binder.jaas.options.principal=kafka-client-1@EXAMPLE.COM上記の例は、次の JAAS ファイルに相当するものを表しています。
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_client.keytab"
principal="[email protected] (英語) ";
};必要なトピックがブローカーにすでに存在する場合、または管理者によって作成される場合は、自動作成をオフにして、クライアント JAAS プロパティのみを送信する必要があります。
同じアプリケーションで JAAS 構成ファイルと Spring Boot プロパティを混在させないでください。-Djava.security.auth.login.config システムプロパティがすでに存在する場合、Spring Cloud Stream は Spring Boot プロパティを無視します。 |
Kerberos で autoCreateTopics および autoAddPartitions を使用する場合は注意してください。通常、アプリケーションは、Kafka および Zookeeper で管理者権限を持たないプリンシパルを使用することがあります。Spring Cloud Stream に依存してトピックを作成 / 変更すると失敗する可能性があります。安全な環境では、Kafka ツールを使用してトピックを作成し、ACL を管理的に管理することを強くお勧めします。 |
それぞれが個別の JAAS 構成を必要とする複数のクラスターに接続する場合は、プロパティ sasl.jaas.config を使用して JAAS 構成を設定します。このプロパティがアプリケーションに存在する場合、上記の他の戦略よりも優先されます。詳細については、この KIP-85 [Apache] (英語) を参照してください。
例: アプリケーションに別々の JAAS 構成を持つ 2 つのクラスターがある場合、使用できるテンプレートは次のとおりです。
spring.cloud.stream:
binders:
kafka1:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
configuration.sasl.jaas.config: "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"admin\" password=\"admin-secret\";"
kafka2:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9093
configuration.sasl.jaas.config: "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"user1\" password=\"user1-secret\";"
kafka.binder:
configuration:
security.protocol: SASL_PLAINTEXT
sasl.mechanism: PLAIN 上記の構成では、Kafka クラスターとそれぞれの sasl.jaas.config 値の両方が異なることに注意してください。
このようなアプリケーションをセットアップして実行する方法の詳細については、このサンプルアプリケーション [GitHub] (英語) を参照してください。
サンプル: コンシューマーの一時停止と再開
コンシューマーを一時停止したいが、パーティションのリバランスを引き起こしたくない場合は、コンシューマーを一時停止して再開できます。これは、Consumer をパラメーターとして @StreamListener に追加することで容易になります。再開するには、ListenerContainerIdleEvent インスタンス用の ApplicationListener が必要です。イベントが公開される頻度は、idleEventInterval プロパティによって制御されます。コンシューマーはスレッドセーフではないため、呼び出し元のスレッドでこれらのメソッドを呼び出す必要があります。
次の簡単なアプリケーションは、一時停止および再開する方法を示しています。
@SpringBootApplication
@EnableBinding(Sink.class)
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@StreamListener(Sink.INPUT)
public void in(String in, @Header(KafkaHeaders.CONSUMER) Consumer<?, ?> consumer) {
System.out.println(in);
consumer.pause(Collections.singleton(new TopicPartition("myTopic", 0)));
}
@Bean
public ApplicationListener<ListenerContainerIdleEvent> idleListener() {
return event -> {
System.out.println(event);
if (event.getConsumer().paused().size() > 0) {
event.getConsumer().resume(event.getConsumer().paused());
}
};
}
}トランザクションバインダー
spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix を空でない値に設定して、トランザクションを有効にします。tx-。プロセッサーアプリケーションで使用される場合、コンシューマーはトランザクションを開始します。コンシューマースレッドで送信されたすべてのレコードは、同じトランザクションに参加します。リスナーが正常に終了すると、リスナーコンテナーはオフセットをトランザクションに送信し、コミットします。spring.cloud.stream.kafka.binder.transaction.producer.* プロパティを使用して構成されたすべてのプロデューサーバーインディングには、共通のプロデューサーファクトリが使用されます。個々のバインディング Kafka プロデューサープロパティは無視されます。
通常のバインダーの再試行(およびデッドレタリング)は、トランザクションではサポートされていません。再試行は元のトランザクションで実行されるため、ロールバックされる可能性があり、公開されたレコードもロールバックされます。再試行が有効になっている場合(共通プロパティ maxAttempts がゼロより大きい場合)、再試行プロパティを使用して、コンテナーレベルで再試行を有効にするように DefaultAfterRollbackProcessor を構成します。同様に、トランザクション内で配信不能レコードを公開する代わりに、この機能は、メイントランザクションがロールバックされた後に実行される DefaultAfterRollbackProcessor を介して、リスナーコンテナーに移動されます。 |
ソースアプリケーションで、またはプロデューサーのみのトランザクション(@Scheduled メソッドなど)の任意のスレッドからトランザクションを使用する場合は、トランザクションプロデューサーファクトリへの参照を取得し、それを使用して KafkaTransactionManager Bean を定義する必要があります。
@Bean
public PlatformTransactionManager transactionManager(BinderFactory binders,
@Value("${unique.tx.id.per.instance}") String txId) {
ProducerFactory<byte[], byte[]> pf = ((KafkaMessageChannelBinder) binders.getBinder(null,
MessageChannel.class)).getTransactionalProducerFactory();
KafkaTransactionManager tm = new KafkaTransactionManager<>(pf);
tm.setTransactionId(txId)
return tm;
}BinderFactory を使用してバインダーへの参照を取得していることに注意してください。バインダーが 1 つしか構成されていない場合は、最初の引数で null を使用します。複数のバインダーが構成されている場合は、バインダー名を使用して参照を取得します。バインダーへの参照を取得したら、ProducerFactory への参照を取得して、トランザクションマネージャーを作成できます。
次に、通常の Spring トランザクションサポートを使用します。TransactionTemplate または @Transactional、例:
public static class Sender {
@Transactional
public void doInTransaction(MessageChannel output, List<String> stuffToSend) {
stuffToSend.forEach(stuff -> output.send(new GenericMessage<>(stuff)));
}
} プロデューサーのみのトランザクションを他のトランザクションマネージャーからのトランザクションと同期する場合は、ChainedTransactionManager を使用します。
アプリケーションの複数のインスタンスをデプロイする場合、各インスタンスには一意の transactionIdPrefix が必要です。 |
エラーチャネル
バージョン 1.3 以降、バインダーは各コンシューマー宛先のエラーチャネルに無条件に例外を送信し、非同期プロデューサー送信エラーをエラーチャネルに送信するように構成することもできます。詳細については、エラー処理に関するこのセクション (英語) を参照してください。
送信失敗の ErrorMessage のペイロードは、次のプロパティを持つ KafkaSendFailureException です。
failedMessage: 送信に失敗した Spring メッセージングMessage<?>。record:failedMessageから作成された生のProducerRecord
プロデューサーの例外(デッドレターキューへの送信など)の自動処理はありません。これらの例外は、独自の Spring Integration フローで使用できます。
Kafka メトリクス
Kafka バインダーモジュールは、次のメトリクスを公開します。
spring.cloud.stream.binder.kafka.offset: このメトリクスは、特定のコンシューマーグループによって特定のバインダーのトピックからまだ消費されていないメッセージの数を示します。提供されるメトリクスは、Micrometer ライブラリに基づいています。Micrometer がクラスパス上にあり、アプリケーションによって他のそのような Bean が提供されていない場合、バインダーは KafkaBinderMetrics Bean を作成します。メトリクスには、コンシューマーグループ情報、トピック、トピックの最新のオフセットからのコミットされたオフセットの実際のラグが含まれます。このメトリクスは、PaaS プラットフォームに自動スケーリングフィードバックを提供する場合に特に役立ちます。
アプリケーションで次のコンポーネントを提供することにより、KafkaBinderMetrics をコンシューマーなどの必要なインフラストラクチャの作成から除外し、メトリクスをレポートすることができます。
@Component
class NoOpBindingMeters {
NoOpBindingMeters(MeterRegistry registry) {
registry.config().meterFilter(
MeterFilter.denyNameStartsWith(KafkaBinderMetrics.OFFSET_LAG_METRIC_NAME));
}
}メーターを選択的に抑制する方法の詳細については、こちらを参照してください (英語) 。
Tombstone レコード (null レコード値)
圧縮されたトピックを使用する場合、null 値を持つレコード (tombstone レコードとも呼ばれます) はキーの削除を表します。@StreamListener メソッドでこのようなメッセージを受信するには、パラメーターを null 値引数の受信に不要としてマークする必要があります。
@StreamListener(Sink.INPUT)
public void in(@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) byte[] key,
@Payload(required = false) Customer customer) {
// customer is null if a tombstone record
...
}KafkaBindingRebalanceListener を使用する
アプリケーションは、パーティションが最初に割り当てられたときに任意のオフセットにトピック / パーティションを探すか、コンシューマーで他の操作を実行したい場合があります。バージョン 2.1 以降、アプリケーションコンテキストで単一の KafkaBindingRebalanceListener Bean を提供すると、すべての Kafka コンシューマーバインディングに接続されます。
public interface KafkaBindingRebalanceListener {
/**
* Invoked by the container before any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedBeforeCommit(String bindingName, Consumer<?, ?> consumer,
Collection<TopicPartition> partitions) {
}
/**
* Invoked by the container after any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedAfterCommit(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
}
/**
* Invoked when partitions are initially assigned or after a rebalance.
* Applications might only want to perform seek operations on an initial assignment.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
* @param initial true if this is the initial assignment.
*/
default void onPartitionsAssigned(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions,
boolean initial) {
}
} リバランスリスナーを提供する場合、resetOffsets コンシューマープロパティを true に設定することはできません。
コンシューマーとプロデューサーの構成のカスタマイズ
Kafka で ConsumerFactory および ProducerFactory を作成するために使用されるコンシューマーおよびプロデューサー構成の高度なカスタマイズが必要な場合は、以下のカスタマイザーを実装できます。
ConsumerConfigCustomizer
ProducerConfigCustomizer
これらのインターフェースは両方とも、コンシューマーおよびプロデューサーのプロパティに使用される構成マップを構成する方法を提供します。例: アプリケーションレベルで定義されている Bean にアクセスしたい場合は、configure メソッドの実装にそれを挿入できます。バインダーは、これらのカスタマイザーが Bean として使用可能であることを検出すると、コンシューマーファクトリとプロデューサーファクトリを作成する直前に configure メソッドを呼び出します。
これらのインターフェースは両方とも、バインディング名と宛先名の両方へのアクセスを提供するため、プロデューサーとコンシューマーのプロパティをカスタマイズしながらアクセスできます。
AdminClient 構成のカスタマイズ
上記のコンシューマーおよびプロデューサー構成のカスタマイズと同様に、アプリケーションは AdminClientConfigCustomizer を提供することにより、管理クライアントの構成をカスタマイズすることもできます。AdminClientConfigCustomizer の configure メソッドは、管理クライアントプロパティへのアクセスを提供し、それを使用してさらにカスタマイズを定義できます。バインダーの Kafka トピックプロビジョナーは、このカスタマイザーを通じて指定されたプロパティに最高の優先順位を与えます。このカスタマイザ Bean を提供する例を次に示します。
@Bean
public AdminClientConfigCustomizer adminClientConfigCustomizer() {
return props -> {
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SASL_SSL");
};
}デッドレタートピック処理
デッドレタートピックパーティションの選択
デフォルトでは、レコードは元のレコードと同じパーティションを使用して Dead-Letter トピックに公開されます。つまり、Dead-Letter トピックには、少なくとも元のレコードと同じ数のパーティションが必要です。
この動作を変更するには、DlqPartitionFunction 実装を @Bean としてアプリケーションコンテキストに追加します。そのような Bean は 1 つだけ存在できます。この機能は、コンシューマーグループ、障害が発生した ConsumerRecord、例外とともに提供されます。例: 常にパーティション 0 にルーティングする場合は、次を使用できます。
@Bean
public DlqPartitionFunction partitionFunction() {
return (group, record, ex) -> 0;
} コンシューマーバインディングの dlqPartitions プロパティを 1 に設定する(そして、バインダーの minPartitionCount が 1 に等しい)場合、DlqPartitionFunction を供給する必要はありません。フレームワークは常にパーティション 0 を使用します。コンシューマーバインディングの dlqPartitions プロパティを 1 よりも大きい値に設定した場合(または、バインダーの minPartitionCount が 1 よりも大きい場合)、パーティション数が元のトピックのものと同じであっても、DlqPartitionFunction Bean を必ず提供しなければなりません。 |
DLQ トピックのカスタム名を定義することもできます。これを行うには、アプリケーションコンテキストへの @Bean として DlqDestinationResolver の実装を作成します。バインダーがそのような Bean を検出すると、それが優先されます。それ以外の場合は、dlqName プロパティが使用されます。これらのどちらも見つからない場合は、デフォルトで error.<destination>.<group> になります。@Bean としての DlqDestinationResolver の例を次に示します。
@Bean
public DlqDestinationResolver dlqDestinationResolver() {
return (rec, ex) -> {
if (rec.topic().equals("word1")) {
return "topic1-dlq";
}
else {
return "topic2-dlq";
}
};
}DlqDestinationResolver の実装を提供する際に留意すべき重要なことの 1 つは、バインダーのプロビジョナーがアプリケーションのトピックを自動作成しないことです。これは、実装が送信する可能性のあるすべての DLQ トピックの名前をバインダーが推測する方法がないためです。この戦略を使用して DLQ 名を提供する場合、それらのトピックが事前に作成されていることを確認するのはアプリケーションの責任です。
デッドレタートピックでのレコードの処理
フレームワークは、ユーザーがデッドレターメッセージをどのように処理するかを予測できないため、メッセージを処理するための標準的なメカニズムを提供していません。デッドレタリングの理由が一時的なものである場合は、メッセージを元のトピックにルーティングして戻すことをお勧めします。ただし、課題が永続的な課題である場合は、無限ループが発生する可能性があります。このトピック内のサンプル Spring Boot アプリケーションは、これらのメッセージを元のトピックにルーティングする方法の例ですが、3 回試行すると、メッセージは「駐車場」トピックに移動します。このアプリケーションは、デッドレターのトピックから読み取る別の spring-cloud-stream アプリケーションです。5 秒間メッセージが受信されないと終了します。
例では、元の宛先が so8400out であり、コンシューマーグループが so8400 であると想定しています。
考慮すべき戦略がいくつかあります。
メインアプリケーションが実行されていないときにのみ再ルーティングを実行することを検討してください。そうしないと、一時的なエラーの再試行がすぐに使い果たされてしまいます。
または、2 段階のアプローチを使用します。このアプリケーションを使用して 3 番目のトピックにルーティングし、別のアプリケーションを使用してそこからメイントピックにルーティングします。
次のコードリストは、サンプルアプリケーションを示しています。
spring.cloud.stream.bindings.input.group=so8400replay
spring.cloud.stream.bindings.input.destination=error.so8400out.so8400
spring.cloud.stream.bindings.output.destination=so8400out
spring.cloud.stream.bindings.parkingLot.destination=so8400in.parkingLot
spring.cloud.stream.kafka.binder.configuration.auto.offset.reset=earliest
spring.cloud.stream.kafka.binder.headers=x-retries@SpringBootApplication
@EnableBinding(TwoOutputProcessor.class)
public class ReRouteDlqKApplication implements CommandLineRunner {
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) {
SpringApplication.run(ReRouteDlqKApplication.class, args).close();
}
private final AtomicInteger processed = new AtomicInteger();
@Autowired
private MessageChannel parkingLot;
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public Message<?> reRoute(Message<?> failed) {
processed.incrementAndGet();
Integer retries = failed.getHeaders().get(X_RETRIES_HEADER, Integer.class);
if (retries == null) {
System.out.println("First retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else if (retries.intValue() < 3) {
System.out.println("Another retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(retries.intValue() + 1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else {
System.out.println("Retries exhausted for " + failed);
parkingLot.send(MessageBuilder.fromMessage(failed)
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build());
}
return null;
}
@Override
public void run(String... args) throws Exception {
while (true) {
int count = this.processed.get();
Thread.sleep(5000);
if (count == this.processed.get()) {
System.out.println("Idle, exiting");
return;
}
}
}
public interface TwoOutputProcessor extends Processor {
@Output("parkingLot")
MessageChannel parkingLot();
}
}Kafka バインダーによるパーティショニング
Apache Kafka はトピックのパーティション分割をネイティブにサポートします。
たとえば、メッセージ処理を厳密に並べ替える場合など、特定のパーティションにデータを送信すると有利な場合があります(特定の顧客宛てのすべてのメッセージは同じパーティションに送信する必要があります)。
次の例は、プロデューサー側とコンシューマー側を構成する方法を示しています。
@SpringBootApplication
@EnableBinding(Source.class)
public class KafkaPartitionProducerApplication {
private static final Random RANDOM = new Random(System.currentTimeMillis());
private static final String[] data = new String[] {
"foo1", "bar1", "qux1",
"foo2", "bar2", "qux2",
"foo3", "bar3", "qux3",
"foo4", "bar4", "qux4",
};
public static void main(String[] args) {
new SpringApplicationBuilder(KafkaPartitionProducerApplication.class)
.web(false)
.run(args);
}
@InboundChannelAdapter(channel = Source.OUTPUT, poller = @Poller(fixedRate = "5000"))
public Message<?> generate() {
String value = data[RANDOM.nextInt(data.length)];
System.out.println("Sending: " + value);
return MessageBuilder.withPayload(value)
.setHeader("partitionKey", value)
.build();
}
}spring:
cloud:
stream:
bindings:
output:
destination: partitioned.topic
producer:
partition-key-expression: headers['partitionKey']
partition-count: 12 トピックは、すべてのコンシューマーグループに必要な同時実行性を実現するのに十分なパーティションを持つようにプロビジョニングする必要があります。上記の構成は、最大 12 のコンシューマーインスタンスをサポートします(concurrency が 2, 4 の場合は 6、同時実行性が 3 の場合など)。一般に、将来のコンシューマーまたは同時実行性の増加を考慮して、パーティションを「オーバープロビジョニング」するのが最善です。 |
上記の構成では、デフォルトのパーティショニング(key.hashCode() % partitionCount)を使用しています。これは、キー値に応じて、適切にバランスの取れたアルゴリズムを提供する場合と提供しない場合があります。partitionSelectorExpression または partitionSelectorClass プロパティを使用して、このデフォルトをオーバーライドできます。 |
パーティションは Kafka によってネイティブに処理されるため、コンシューマー側で特別な構成は必要ありません。Kafka は、インスタンス全体にパーティションを割り当てます。
次の Spring Boot アプリケーションは、Kafka ストリームをリッスンし、各メッセージの送信先のパーティション ID を(コンソールに)出力します。
@SpringBootApplication
@EnableBinding(Sink.class)
public class KafkaPartitionConsumerApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(KafkaPartitionConsumerApplication.class)
.web(false)
.run(args);
}
@StreamListener(Sink.INPUT)
public void listen(@Payload String in, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
System.out.println(in + " received from partition " + partition);
}
}spring:
cloud:
stream:
bindings:
input:
destination: partitioned.topic
group: myGroup 必要に応じてインスタンスを追加できます。Kafka は、パーティション割り当てのバランスを取り直します。インスタンス数(または instance count * concurrency)がパーティションの数を超えると、一部のコンシューマーはアイドル状態になります。