Spring Integration は、よく知られているエンタープライズ統合パターン (英語) をサポートするために、Spring プログラミングモデルの拡張機能を提供します。Spring ベースのアプリケーション内で軽量のメッセージングを可能にし、宣言的なアダプターを介して外部システムとの統合をサポートします。これらのアダプターは、Spring のリモート処理、メッセージング、スケジューリングのサポートよりも高度な抽象化を提供します。
Spring Integration の主なゴールは、エンタープライズ統合ソリューションを構築するためのシンプルなモデルを提供する一方で、保守可能でテスト可能なコードを作成するために不可欠な関心事の分離を維持することです。
Spring Integration の概要
この章では、Spring Integration のコアコンセプトとコンポーネントの概要を説明します。Spring Integration を最大限に活用するのに役立つプログラミングのヒントが含まれています。
バックグラウンド
Spring Framework の重要なテーマの 1 つは、Inversion of Control(IoC)です。最も広い意味では、これは、フレームワークがそのコンテキスト内で管理されるコンポーネントに代わって責任を処理することを意味します。コンポーネント自体は、それらの責任から解放されるため、単純化されます。例: 依存性注入により、コンポーネントの依存関係を見つけたり作成したりする責任が軽減されます。同様に、アスペクト指向プログラミングは、ビジネスコンポーネントを再利用可能なアスペクトにモジュール化することにより、一般的な横断的な関心事からビジネスコンポーネントを解放します。いずれの場合も、最終結果は、テスト、理解、保守、拡張が容易なシステムです。
さらに、Spring フレームワークとポートフォリオは、エンタープライズアプリケーションを構築するための包括的なプログラミングモデルを提供します。開発者は、このモデルの一貫性、特に、インターフェースへのプログラミングや継承よりも合成を優先するなど、確立されたベストプラクティスに基づいているという事実から恩恵を受けます。Spring の単純化された抽象化と強力なサポートライブラリにより、開発者の生産性が向上すると同時に、テスト性と移植性のレベルが向上します。
Spring Integration は、これらの同じゴールと原則によって動機付けられています。Spring プログラミングモデルをメッセージングドメインに拡張し、Spring の既存のエンタープライズ統合サポートに基づいて、さらに高度な抽象化を提供します。特定のビジネスロジックを実行するタイミングやレスポンスを送信するタイミングなど、実行時の関心事に制御の反転が適用されるメッセージ駆動型アーキテクチャをサポートします。メッセージのルーティングと変換をサポートしているため、テスト容易性に影響を与えることなく、さまざまなトランスポートとさまざまなデータ形式を統合できます。つまり、メッセージングと統合の問題はフレームワークによって処理されます。ビジネスコンポーネントはインフラストラクチャからさらに分離され、開発者は複雑な統合の責任から解放されます。
Spring Integration は、Spring プログラミングモデルの拡張として、アノテーション、名前空間サポート付き XML、汎用 "Bean" 要素付き XML、基盤となる API の直接使用など、さまざまな構成オプションを提供します。この API は、明確に定義された戦略インターフェースと非侵襲的な委譲アダプターに基づいています。Spring Integration のデザインは、Spring 内の一般的なパターンと、エンタープライズ統合パターン (英語) で説明されている Gregor Hohpe と Bobby Woolf によるよく知られたパターン(Addison Wesley、2004 年)との強い親和性の認識に触発されました。その本を読んだ開発者は、Spring Integration の概念と用語にすぐに慣れるべきです。
ゴールと原則
Spring Integration は、次のゴールに基づいています。
複雑なエンタープライズ統合ソリューションを実装するためのシンプルなモデルを提供します。
Spring ベースのアプリケーション内で非同期のメッセージ駆動型動作を促進します。
既存の Spring ユーザーの直感的で漸進的な採用を促進します。
Spring Integration は、次の原則に基づいています。
モジュール性とテスト容易性のために、コンポーネントを疎結合する必要があります。
フレームワークは、ビジネスロジックと統合ロジック間の関心事の分離を強制する必要があります。
拡張ポイントは、再利用と移植性を促進するために、本質的に抽象的でなければなりません(ただし、明確に定義された境界内にある必要があります)。
メインコンポーネント
垂直的な観点から見ると、階層化されたアーキテクチャは関心事の分離を促進し、レイヤー間のインターフェースベースの契約は疎結合を促進します。通常、Spring ベースのアプリケーションはこのように設計されており、Spring フレームワークとポートフォリオは、エンタープライズアプリケーションのフルスタックでこのベストプラクティスに従うための強力な基盤を提供します。メッセージ駆動型アーキテクチャは水平的な視点を追加しますが、これらの同じゴールは依然として関連しています。「階層化されたアーキテクチャ」が非常に一般的で抽象的なパラダイムであるように、メッセージングシステムは通常、同様の抽象的な「パイプとフィルター」モデルに従います。「フィルター」はメッセージを生成または消費できるコンポーネントを表し、「パイプ」はフィルター間でメッセージを転送するため、コンポーネント自体は疎結合のままです。これら 2 つのハイレベルなパラダイムは相互に排他的ではないことに注意することが重要です。「パイプ」をサポートする基礎となるメッセージングインフラストラクチャは、契約がインターフェースとして定義されているレイヤーにカプセル化する必要があります。同様に、「フィルター」自体も、アプリケーションのサービス層よりも論理的に上位の層内で管理し、Web 層とほぼ同じメソッドでインターフェースを介してこれらのサービスとやり取りする必要があります。
メッセージ
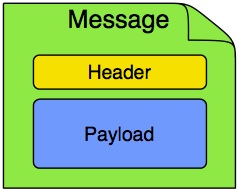
Spring Integration では、メッセージは、フレームワークがそのオブジェクトの処理中に使用するメタデータと組み合わされた Java オブジェクトの汎用ラッパーです。ペイロードとヘッダーで構成されます。ペイロードはどの型でもかまいません。ヘッダーには、ID、タイムスタンプ、相関 ID、返信アドレスなどの一般的に必要な情報が保持されます。ヘッダーは、接続されたトランスポートとの間で値を渡すためにも使用されます。例: 受信したファイルからメッセージを作成する場合、ファイル名はヘッダーに保存され、ダウンストリームコンポーネントからアクセスできます。同様に、メッセージのコンテンツが最終的に送信メールアダプターによって送信される場合、さまざまなプロパティ(to、from、cc、subject など)がアップストリームコンポーネントによってメッセージヘッダー値として構成されます。開発者は、任意のキーと値のペアをヘッダーに保存することもできます。
メッセージチャンネル
メッセージチャネルは、パイプおよびフィルターアーキテクチャの「パイプ」を表します。プロデューサーはチャンネルにメッセージを送信し、コンシューマーはチャンネルからメッセージを受信します。メッセージチャネルはメッセージングコンポーネントを分離し、メッセージのインターセプトと監視のための便利なポイントを提供します。

メッセージチャネルは、ポイントツーポイントまたはパブリッシュ / サブスクライブのいずれかのセマンティクスに従う場合があります。ポイントツーポイントチャネルでは、チャネルに送信された各メッセージを受信できるコンシューマーは 1 人だけです。一方、パブリッシュ / サブスクライブチャネルは、チャネル上のすべてのサブスクライバに各メッセージをブロードキャストしようとします。Spring Integration は、これらのモデルの両方をサポートしています。
「ポイントツーポイント」と「パブリッシュ / サブスクライブ」は、最終的に各メッセージを受信するコンシューマー数の 2 つのオプションを定義しますが、もう 1 つの重要な考慮事項があります。Spring Integration では、ポーリング可能なチャネルはキュー内のメッセージをバッファリングできます。バッファリングの利点は、受信メッセージの調整を可能にし、それによってコンシューマーのオーバーロードを防ぐことです。しかし、名前が示すように、ポーラーが構成されている場合、コンシューマーはそのようなチャネルからのみメッセージを受信できるため、これにより複雑さが増します。一方、サブスクライブ可能なチャネルに接続されたコンシューマーは、単にメッセージ駆動型です。メッセージチャネルの実装には、Spring Integration で利用可能なさまざまなチャネル実装の詳細な議論があります。
メッセージエンドポイント
Spring Integration の主なゴールの 1 つは、制御の反転を通じてエンタープライズ統合ソリューションの開発を簡素化することです。つまり、コンシューマーとプロデューサーを直接実装する必要はなく、メッセージを構築して、メッセージチャネルで送信または受信操作を呼び出す必要もありません。代わりに、プレーンオブジェクトに基づく実装により、特定のドメインモデルに集中できるはずです。次に、宣言的な構成を提供することにより、Spring Integration が提供するメッセージングインフラストラクチャにドメイン固有のコードを「接続」できます。これらの接続を担当するコンポーネントは、メッセージエンドポイントです。これは、必ずしも既存のアプリケーションコードを直接接続する必要があるという意味ではありません。実際のエンタープライズ統合ソリューションでは、ルーティングや変換などの統合の関心事に焦点を合わせたコードが必要です。重要なことは、統合ロジックとビジネスロジックの関心事を分離することです。言い換えると、Web アプリケーションの Model-View-Controller(MVC)パラダイムと同様に、ゴールは、受信リクエストをサービスレイヤー呼び出しに変換し、その後サービスレイヤーの戻り値を送信応答に変換する、薄いが専用のレイヤーを提供することです。次のセクションでは、これらの責任を処理するメッセージエンドポイント型の概要を説明します。今後の章では、Spring Integration の宣言的な設定オプションがこれらの各機能を非侵襲的に使用する方法を説明します。
メッセージエンドポイント
メッセージエンドポイントは、パイプアンドフィルターアーキテクチャの「フィルター」を表します。前述したように、エンドポイントの主なロールは、アプリケーションコードをメッセージングフレームワークに接続し、非侵襲的なメソッドで接続することです。つまり、アプリケーションコードは、メッセージオブジェクトまたはメッセージチャネルを認識しないのが理想的です。これは、MVC パラダイムにおけるコントローラーのロールに似ています。コントローラーが HTTP リクエストを処理するのと同じように、メッセージエンドポイントがメッセージを処理します。コントローラーが URL パターンにマップされるのと同様に、メッセージエンドポイントはメッセージチャネルにマップされます。どちらの場合もゴールは同じです。アプリケーションコードをインフラストラクチャから分離します。これらの概念とそれに続くすべてのパターンは、エンタープライズ統合パターン (英語) ブックで詳細に説明されています。ここでは、Spring Integration でサポートされている主要なエンドポイント型と、それらの型に関連付けられているロールの概要のみを説明します。以下の章では、サンプルコードと設定例を詳しく説明します。
メッセージ Transformer
メッセージトランスフォーマーは、メッセージのコンテンツまたは構造を変換し、変更されたメッセージを返す責任があります。おそらく最も一般的な型のトランスフォーマーは、メッセージのペイロードをある形式から別の形式に変換するトランスフォーマー(XML から java.lang.String など)です。同様に、トランスフォーマーはメッセージのヘッダー値を追加、削除、変更できます。
メッセージフィルター
メッセージフィルターは、メッセージを出力チャネルに渡すかどうかを決定します。これには、特定のペイロードコンテンツ型、プロパティ値、ヘッダーの存在、その他の条件をチェックするブールテストメソッドが必要です。メッセージが受け入れられると、出力チャネルに送信されます。そうでない場合は、ドロップされます(または、より厳しい実装では、Exception がスローされる可能性があります)。メッセージフィルターは、多くの場合、複数のコンシューマーが同じメッセージを受信し、フィルターの条件を使用して処理するメッセージのセットを絞り込むことができるパブリッシュ / サブスクライブチャネルと組み合わせて使用されます。
| パイプとフィルターのアーキテクチャパターン内の「フィルター」の一般的な使用を、2 つのチャネル間を流れるメッセージを選択的に絞り込むこの特定のエンドポイント型と混同しないように注意してください。「フィルター」のパイプとフィルターの概念は、Spring Integration のメッセージエンドポイント(メッセージを送信または受信するためにメッセージチャネルに接続できるコンポーネント)とより密接に一致します。 |
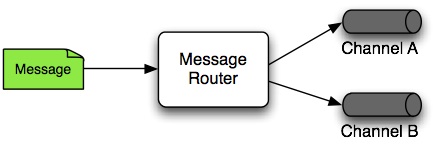
メッセージルーター
メッセージルーターは、次にメッセージを受信するチャネル(ある場合)を決定する責任があります。通常、決定はメッセージのコンテンツまたはメッセージヘッダーで利用可能なメタデータに基づいています。多くの場合、メッセージルーターは、応答メッセージを送信できるサービスアクティベーターまたはその他のエンドポイントで静的に構成された出力チャネルの動的な代替手段として使用されます。同様に、メッセージルーターは、前述のように、複数のサブスクライバーが使用するリアクティブメッセージフィルターのプロアクティブな代替手段を提供します。
スプリッター
スプリッターは、入力チャネルからのメッセージを受け入れ、そのメッセージを複数のメッセージに分割し、それぞれを出力チャネルに送信することを担当する別の型のメッセージエンドポイントです。これは通常、「複合」ペイロードオブジェクトを、細分化されたペイロードを含むメッセージのグループに分割するために使用されます。
アグリゲーター
基本的にスプリッターの鏡像であるアグリゲーターは、複数のメッセージを受信し、単一のメッセージに結合するメッセージエンドポイントの一種です。実際、アグリゲーターは多くの場合、スプリッターを含むパイプラインの下流のコンシューマーです。技術的には、アグリゲーターはスプリッターよりも複雑です。これは、状態(集約するメッセージ)を維持し、メッセージの完全なグループがいつ利用可能になるかを判断し、必要に応じてタイムアウトする必要があるためです。さらに、タイムアウトが発生した場合、アグリゲーターは部分的な結果を送信するか、破棄するか、別のチャネルに送信するかを知る必要があります。Spring Integration は、CorrelationStrategy、ReleaseStrategy、タイムアウトの構成可能な設定、タイムアウト時に部分的な結果を送信するかどうか、および破棄チャネルを提供します。
サービスアクティベーター
Service Activator は、サービスインスタンスをメッセージングシステムに接続するための汎用エンドポイントです。入力メッセージチャネルを設定する必要があります。呼び出されるサービスメソッドが値を返すことができる場合は、出力メッセージチャネルも提供されます。
| 各メッセージは独自の "Return Address" ヘッダーを提供する場合があるため、出力チャネルはオプションです。これと同じルールがすべてのコンシューマーエンドポイントに適用されます。 |
サービスアクティベーターは、何らかのサービスオブジェクトのオペレーションを呼び出してリクエストメッセージを処理し、リクエストメッセージのペイロードを抽出して変換します(メソッドがメッセージ型のパラメーターを予期しない場合)。サービスオブジェクトのメソッドが値を返すときはいつでも、必要に応じて、その戻り値も同様に応答メッセージに変換されます(まだメッセージ型でない場合)。その応答メッセージは出力チャネルに送信されます。出力チャネルが設定されていない場合、返信は、メッセージの「返信先アドレス」で指定されているチャネルに送信されます(利用可能な場合)。
リクエスト応答サービスアクティベーターエンドポイントは、ターゲットオブジェクトのメソッドを入力および出力メッセージチャネルに接続します。
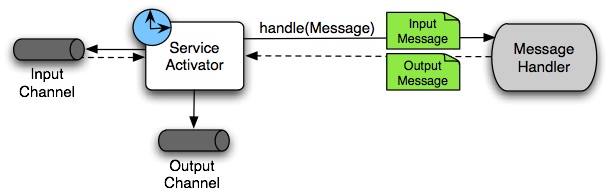
| 前述のように、メッセージチャンネルでは、チャネルはポーリング可能またはサブスクライブ可能です。前の図では、これは「クロック」記号と実線矢印(ポール)および点線矢印(購読)で表されています。 |
チャンネルアダプター
チャネルアダプターは、メッセージチャネルを他のシステムまたはトランスポートに接続するエンドポイントです。チャネルアダプターは、受信または送信のいずれかです。通常、チャネルアダプターは、メッセージと、他のシステム(ファイル、HTTP リクエスト、JMS メッセージなど)から送受信されるオブジェクトまたはリソースとのマッピングを行います。トランスポートに応じて、チャネルアダプターはメッセージヘッダー値を入力または抽出する場合もあります。Spring Integration は多数のチャネルアダプターを提供します。これについては、今後の章で説明します。

MessageChannel に接続します。| メッセージソースは、ポーリング可能(POP3 など)またはメッセージ駆動型(IMAP Idle など)にすることができます。前の図では、これは「クロック」記号と実線矢印(ポール)および点線矢印(メッセージ駆動型)で示されています。 |

MessageChannel をターゲットシステムに接続します。| メッセージチャンネルで前述したように、チャネルはポーリング可能またはサブスクライブ可能です。前の図では、これは「クロック」記号と実線矢印(ポール)および点線矢印(購読)で表されています。 |
エンドポイント Bean 名
消費エンドポイント(inputChannel を持つもの)は、コンシューマーとメッセージハンドラーの 2 つの Bean で構成されます。コンシューマーはメッセージハンドラーへの参照を持ち、メッセージが到着すると呼び出します。
次の XML の例を検討してください。
<int:service-activator id = "someService" ... />上記の例を考えると、Bean 名は次のとおりです。
コンシューマー:
someService(id)ハンドラー:
someService.handler
エンタープライズ統合パターン(EIP)アノテーションを使用する場合、名前はいくつかの要因に依存します。アノテーション付きの POJO の次の例を考えてみましょう。
@Component
public class SomeComponent {
@ServiceActivator(inputChannel = ...)
public String someMethod(...) {
...
}
}上記の例を考えると、Bean 名は次のとおりです。
コンシューマー:
someComponent.someMethod.serviceActivatorハンドラー:
someComponent.someMethod.serviceActivator.handler
バージョン 5.0.4 以降、次の例に示すように、@EndpointId アノテーションを使用してこれらの名前を変更できます。
@Component
public class SomeComponent {
@EndpointId("someService")
@ServiceActivator(inputChannel = ...)
public String someMethod(...) {
...
}
}上記の例を考えると、Bean 名は次のとおりです。
コンシューマー:
someServiceハンドラー:
someService.handler
@EndpointId は、XML 構成で id 属性によって作成された名前を作成します。以下のアノテーション付き Bean の例を考えてください。
@Configuration
public class SomeConfiguration {
@Bean
@ServiceActivator(inputChannel = ...)
public MessageHandler someHandler() {
...
}
}上記の例を考えると、Bean 名は次のとおりです。
コンシューマー:
someConfiguration.someHandler.serviceActivatorハンドラー:
someHandler(@Bean名)
バージョン 5.0.4 以降、次の例に示すように、@EndpointId アノテーションを使用してこれらの名前を変更できます。
@Configuration
public class SomeConfiguration {
@Bean("someService.handler") (1)
@EndpointId("someService") (2)
@ServiceActivator(inputChannel = ...)
public MessageHandler someHandler() {
...
}
}| 1 | ハンドラー: someService.handler (Bean 名) |
| 2 | コンシューマー: someService (エンドポイント ID) |
@EndpointId アノテーションは、@Bean 名に .handler を追加する規則を使用している限り、XML 構成で id 属性によって作成された名前を作成します。
3 番目の Bean が作成される特別なケースが 1 つあります。アーキテクチャ上の理由から、MessageHandler @Bean が AbstractReplyProducingMessageHandler を定義していない場合、フレームワークは提供された Bean を ReplyProducingMessageHandlerWrapper でラップします。このラッパーは、リクエストハンドラーのアドバイス処理をサポートし、通常の「応答なし」のデバッグログメッセージを出力します。その Bean 名は、ハンドラー Bean 名に .wrapper を加えたものです(@EndpointId がある場合、それ以外の場合は、通常生成されるハンドラー名です)。
同様に、ポーリング可能なメッセージソースは SourcePollingChannelAdapter (SPCA)と MessageSource の 2 つの Bean を作成します。
次の XML 構成を検討してください。
<int:inbound-channel-adapter id = "someAdapter" ... />上記の XML 構成を前提とすると、Bean 名は次のとおりです。
SPCA:
someAdapter(id)ハンドラー:
someAdapter.source
@EndpointId を定義するには、POJO の次の Java 構成を検討してください。
@EndpointId("someAdapter")
@InboundChannelAdapter(channel = "channel3", poller = @Poller(fixedDelay = "5000"))
public String pojoSource() {
...
}前述の Java 構成の例で、Bean 名は次のとおりです。
SPCA:
someAdapterハンドラー:
someAdapter.source
@EndpointID を定義するには、Bean の次の Java 構成を考慮してください。
@Bean("someAdapter.source")
@EndpointId("someAdapter")
@InboundChannelAdapter(channel = "channel3", poller = @Poller(fixedDelay = "5000"))
public MessageSource<?> source() {
return () -> {
...
};
}上記の例を考えると、Bean 名は次のとおりです。
SPCA:
someAdapterハンドラー:
someAdapter.source(.sourceを@Bean名に追加する規則を使用している限り)
構成と @EnableIntegration
このドキュメント全体で、Spring Integration フローの要素を宣言するための XML 名前空間サポートへの参照を確認できます。このサポートは、特定のコンポーネントを実装するために適切な Bean 定義を生成する一連の名前空間パーサーによって提供されます。例: 多くのエンドポイントは、MessageHandler Bean および ConsumerEndpointFactoryBean で構成され、そこにハンドラーと入力チャネル名が挿入されます。
Spring Integration 名前空間要素が初めて検出されると、フレームワークは、ランタイム環境をサポートするために使用されるいくつかの Bean(タスクスケジューラ、暗黙的なチャネルクリエータなど)を自動的に宣言します。
バージョン 4.0 では @EnableIntegration アノテーションを導入し、Spring Integration インフラストラクチャ Bean の登録を可能にしました(Javadoc を参照)。このアノテーションは、Java 構成のみが使用される場合に必要です。たとえば、Spring Boot または Spring Integration メッセージングアノテーションのサポートと、XML 統合構成のない Spring Integration Java DSL が必要です。 |
@EnableIntegration アノテーションは、Spring Integration コンポーネントのない親コンテキストと、Spring Integration を使用する 2 つ以上の子コンテキストがある場合にも役立ちます。これらの共通コンポーネントは、親コンテキストで一度だけ宣言できます。
@EnableIntegration アノテーションは、多くのインフラストラクチャコンポーネントをアプリケーションコンテキストに登録します。特に、それ:
errorChannelおよびそのLoggingHandler、ポーラー用のtaskScheduler、jsonPathSpEL 機能など、いくつかの組み込み Bean を登録します。いくつかの
BeanFactoryPostProcessorインスタンスを追加して、グローバルおよびデフォルトの統合環境用にBeanFactoryを強化します。いくつかの
BeanPostProcessorインスタンスを追加して、統合のために特定の Bean を拡張または変換してラップします。アノテーションプロセッサーを追加してメッセージングアノテーションを解析し、それらのコンポーネントをアプリケーションコンテキストに登録します。
@IntegrationComponentScan アノテーションは、クラスパススキャンも許可します。このアノテーションは、標準 Spring Framework @ComponentScan アノテーションと同様のロールを果たしますが、標準 Spring Framework コンポーネントスキャンメカニズムが到達できない Spring Integration に固有のコンポーネントとアノテーションに制限されています。例については、@MessagingGateway アノテーションを参照してください。
@EnablePublisher アノテーションは、PublisherAnnotationBeanPostProcessor Bean を登録し、channel 属性なしで提供される @Publisher アノテーション用に default-publisher-channel を構成します。複数の @EnablePublisher アノテーションが見つかった場合、すべてデフォルトチャネルに対して同じ値を持つ必要があります。詳細については、@Publisher アノテーションを使用したアノテーション駆動型の構成を参照してください。
@GlobalChannelInterceptor アノテーションは、ChannelInterceptor Bean をグローバルチャネルインターセプト用にマークするために導入されました。このアノテーションは、<int:channel-interceptor> XML 要素に類似しています(グローバルチャネルインターセプターの構成を参照)。@GlobalChannelInterceptor アノテーションは、クラスレベル(@Component ステレオタイプアノテーション付き)または @Configuration クラス内の @Bean メソッドに配置できます。いずれの場合でも、Bean は ChannelInterceptor を実装する必要があります。
バージョン 5.1 以降、グローバルチャネルインターセプターは、beanFactory.initializeBean() を使用して、または Java DSL の使用時に IntegrationFlowContext を介して初期化される Bean など、動的に登録されたチャネルに適用されます。以前は、アプリケーションコンテキストのリフレッシュ後に Bean が作成されたときにインターセプターは適用されませんでした。
@IntegrationConverter アノテーションは、integrationConversionService の候補コンバーターとして Converter、GenericConverter、ConverterFactory Bean をマークします。このアノテーションは、<int:converter> XML 要素に類似しています(ペイロード型変換を参照)。@IntegrationConverter アノテーションは、クラスレベル(@Component ステレオタイプアノテーションを使用)または @Configuration クラス内の @Bean メソッドに配置できます。
メッセージングアノテーションの詳細については、アノテーションサポートを参照してください。
プログラミングの考慮事項
可能な限りプレーン java オブジェクト(POJO)を使用し、絶対に必要な場合にのみコードでフレームワークを公開する必要があります。詳細については、POJO メソッドの呼び出しを参照してください。
フレームワークをクラスに公開する場合、特にアプリケーションの起動中に考慮する必要がある考慮事項がいくつかあります。
コンポーネントが
ApplicationContextAwareの場合、一般にsetApplicationContext()メソッドでApplicationContextを使用しないでください。代わりに、参照を保存し、そのような使用をコンテキストライフサイクルの後半まで延期します。コンポーネントが
InitializingBeanであるか、@PostConstructメソッドを使用している場合、これらの初期化メソッドからメッセージを送信しないでください。これらのメソッドが呼び出されたとき、アプリケーションコンテキストはまだ初期化されておらず、そのようなメッセージの送信は失敗する可能性があります。起動中にメッセージを送信する必要がある場合は、ApplicationListenerを実装し、ContextRefreshedEventを待ちます。または、SmartLifecycleを実装し、Bean を後期フェーズに入れて、start()メソッドからメッセージを送信します。
パッケージ化された(たとえば、シェードされた)jar を使用する場合の考慮事項
Spring Integration は、Spring Framework の SpringFactories メカニズムを使用していくつかの IntegrationConfigurationInitializer クラスをロードすることにより、特定の機能をブートストラップします。これには、-core jar だけでなく、-http や -jmx を含む他の特定のものも含まれます。このプロセスの情報は、各 jar の META-INF/spring.factories ファイルに保存されます。
一部の開発者は、Apache Maven Shade プラグイン (英語) などのよく知られたツールを使用して、アプリケーションとすべての依存関係を単一の jar に再パッケージ化することを優先します。
デフォルトでは、シェードプラグインは、シェーディングされた jar を生成するときに spring.factories ファイルをマージしません。
spring.factories に加えて、他の META-INF ファイル(spring.handlers および spring.schemas)が XML 構成に使用されます。これらのファイルもマージする必要があります。
Spring Boot の実行可能な jar メカニズムは、jar をネストするため、クラスパスに各 spring.factories ファイルを保持するという点で、異なるアプローチを取ります。Spring Boot アプリケーションでは、デフォルトの実行可能な jar 形式を使用する場合、これ以上必要なものはありません。 |
Spring Boot を使用しない場合でも、Boot が提供するツールを使用して、上記のファイルにトランスフォーマーを追加することにより、シェードプラグインを拡張できます。次の例は、プラグインを構成する方法を示しています。
...
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<configuration>
<keepDependenciesWithProvidedScope>true</keepDependenciesWithProvidedScope>
<createDependencyReducedPom>true</createDependencyReducedPom>
</configuration>
<dependencies>
<dependency> (1)
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
</dependency>
</dependencies>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers> (2)
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
</transformer>
<transformer
implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer">
<resource>META-INF/spring.factories</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" />
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
...具体的
| 1 | spring-boot-maven-plugin を依存関係として追加します。 |
| 2 | トランスフォーマーを構成します。 |
${spring.boot.version} のプロパティを追加するか、明示的なバージョンを使用できます。
プログラミングのヒントとコツ
このセクションでは、Spring Integration を最大限に活用する方法のいくつかをドキュメント化します。
XML スキーマ
XML 構成を使用する場合、誤ったスキーマ検証エラーを回避するには、Eclipse Spring Tool Suite(STS)、Eclipse と Spring IDE プラグイン、または IntelliJ IDEA などの「Spring 対応」IDE を使用する必要があります。これらの IDE は、クラスパスから正しい XML スキーマを解決する方法を知っています(jar の META-INF/spring.schemas ファイルを使用して)。プラグインで STS または Eclipse を使用する場合、プロジェクトで Spring Project Nature を有効にする必要があります。
特定のレガシーモジュール(バージョン 1.0 に存在したもの)のためにインターネットでホストされているスキーマは、互換性の理由から 1.0 バージョンです。IDE がこれらのスキーマを使用している場合、誤ったエラーが表示される可能性があります。
これらの各オンラインスキーマには、次のような警告があります。
このスキーマは、Spring Integration Core の 1.0 バージョン用です。1.0.3 以下を使用しているアプリケーションが破損するため、現在のスキーマに更新できません。以降のバージョンでは、バージョン管理外のスキーマがクラスパスから解決され、jar から取得されます。github を参照してください: |
影響を受けるモジュールは
core(spring-integration.xsd)filehttpjmsmailrmisecuritystreamwsxml
Java および DSL 設定のクラス名の検索
XML 構成と Spring Integration 名前空間のサポートにより、XML パーサーはターゲット Bean がどのように宣言され、相互接続されるかを隠します。Java 構成の場合、ターゲットのエンドユーザーアプリケーションのフレームワーク API を理解することが重要です。
EIP 実装用の第一級オブジェクトは Message、Channel、Endpoint です(この章で前述したメインコンポーネントを参照)。それらの実装(契約)は次のとおりです。
org.springframework.messaging.Message: メッセージを参照してください。org.springframework.messaging.MessageChannel: メッセージチャンネルを参照してください。org.springframework.integration.endpoint.AbstractEndpoint: ポーラーを参照してください。
最初の 2 つは、実装、構成、使用方法を理解するのに十分なほど単純です。最後のものはさらに注目に値する
AbstractEndpoint は、さまざまなコンポーネント実装のために Spring Framework 全体で広く使用されています。主な実装は次のとおりです。
EventDrivenConsumerは、メッセージをリッスンするためにSubscribableChannelにサブスクライブするときに使用されます。PollingConsumer。PollableChannelからのメッセージをポーリングするときに使用されます。
メッセージングアノテーションまたは Java DSL を使用する場合、これらのコンポーネントについて心配する必要があります。これは、フレームワークが適切なアノテーションと BeanPostProcessor 実装で自動的に生成するためです。コンポーネントを手動で構築する場合は、ConsumerEndpointFactoryBean を使用して、提供された inputChannel プロパティに基づいて、作成するターゲット AbstractEndpoint コンシューマー実装の決定を支援する必要があります。
一方、ConsumerEndpointFactoryBean はフレームワーク - org.springframework.messaging.MessageHandler 内の別の第一級オブジェクトに委譲します。このインターフェースの実装の目的は、チャネルからエンドポイントによって消費されるメッセージを処理することです。Spring Integration のすべての EIP コンポーネントは MessageHandler 実装です(たとえば、AggregatingMessageHandler、MessageTransformingHandler、AbstractMessageSplitter など)。ターゲットプロトコル送信アダプター(FileWritingMessageHandler、HttpRequestExecutingMessageHandler、AbstractMqttMessageHandler など)も MessageHandler 実装です。Java 構成で Spring Integration アプリケーションを開発する場合、Spring Integration モジュールを調べて、@ServiceActivator 構成に使用する適切な MessageHandler 実装を見つける必要があります。例: XMPP メッセージ(XMPP サポートを参照)を送信するには、次のように構成する必要があります。
@Bean
@ServiceActivator(inputChannel = "input")
public MessageHandler sendChatMessageHandler(XMPPConnection xmppConnection) {
ChatMessageSendingMessageHandler handler = new ChatMessageSendingMessageHandler(xmppConnection);
DefaultXmppHeaderMapper xmppHeaderMapper = new DefaultXmppHeaderMapper();
xmppHeaderMapper.setRequestHeaderNames("*");
handler.setHeaderMapper(xmppHeaderMapper);
return handler;
}MessageHandler 実装は、メッセージフローの送信および処理部分を表します。
受信メッセージフロー側には独自のコンポーネントがあり、ポーリングとリスニングの動作に分けられます。リスニング(メッセージ駆動型)コンポーネントは単純であり、通常、メッセージを生成する準備ができるのは 1 つのターゲットクラス実装のみです。リスニングコンポーネントは、一方向 MessageProducerSupport 実装(AbstractMqttMessageDrivenChannelAdapter や ImapIdleChannelAdapter など)またはリクエスト / 応答 MessagingGatewaySupport 実装(AmqpInboundGateway や AbstractWebServiceInboundGateway など)にすることができます。
ポーリング受信エンドポイントは、リスナー API を提供しないプロトコル、またはファイルベースのプロトコル(FTP など)、データベース(RDBMS または NoSQL)などを含むそのような動作を意図していないプロトコル用です。
これらの受信エンドポイントは、ポーリングタスクを定期的に開始するポーラー構成と、ターゲットプロトコルからデータを読み取り、ダウンストリーム統合フローのメッセージを生成するメッセージソースクラスの 2 つのコンポーネントで構成されます。ポーラー構成の最初のクラスは SourcePollingChannelAdapter です。これはもう 1 つの AbstractEndpoint 実装ですが、特に統合フローを開始するためのポーリング用です。通常、メッセージングアノテーションまたは Java DSL を使用する場合、このクラスについて心配する必要はありません。フレームワークは、@InboundChannelAdapter 構成または Java DSL ビルダー仕様に基づいて、Bean を生成します。
メッセージソースコンポーネントは、ターゲットアプリケーションの開発にとってより重要であり、それらはすべて MessageSource インターフェース(たとえば、MongoDbMessageSource および AbstractTwitterMessageSource)を実装します。それを念頭に置いて、JDBC を使用して RDBMS テーブルからデータを読み取るための構成は、次のようになります。
@Bean
@InboundChannelAdapter(value = "fooChannel", poller = @Poller(fixedDelay="5000"))
public MessageSource<?> storedProc(DataSource dataSource) {
return new JdbcPollingChannelAdapter(dataSource, "SELECT * FROM foo where status = 0");
} 特定の Spring Integration モジュール(ほとんどの場合、それぞれのパッケージ)でターゲットプロトコルに必要なすべての受信クラスと送信クラスを見つけることができます。例: spring-integration-websocket アダプターは次のとおりです。
o.s.i.websocket.inbound.WebSocketInboundChannelAdapter:MessageProducerSupportを実装して、ソケット上のフレームをリッスンし、チャネルへのメッセージを生成します。o.s.i.websocket.outbound.WebSocketOutboundMessageHandler: 受信メッセージを適切なフレームに変換し、websocket 経由で送信する一方向AbstractMessageHandler実装。
バージョン 4.3 以降の Spring Integration XML 構成に精通している場合、次の例に示すように、アダプターまたはゲートウェイの Bean の宣言に使用されるターゲットクラスに関する情報を XSD 要素定義に提供します。
<xsd:element name="outbound-async-gateway">
<xsd:annotation>
<xsd:documentation>
Configures a Consumer Endpoint for the 'o.s.i.amqp.outbound.AsyncAmqpOutboundGateway'
that will publish an AMQP Message to the provided Exchange and expect a reply Message.
The sending thread returns immediately; the reply is sent asynchronously; uses 'AsyncRabbitTemplate.sendAndReceive()'.
</xsd:documentation>
</xsd:annotation>POJO メソッドの呼び出し
プログラミングの考慮事項で説明したように、次の例に示すように、POJO プログラミングスタイルを使用することをお勧めします。
@ServiceActivator
public String myService(String payload) { ... } この場合、フレームワークは String ペイロードを抽出し、メソッドを呼び出し、結果をメッセージにラップしてフロー内の次のコンポーネントに送信します(元のヘッダーは新しいメッセージにコピーされます)。実際、XML 構成を使用する場合は、次のペアの例に示すように、@ServiceActivator アノテーションさえ必要ありません。
<int:service-activator ... ref="myPojo" method="myService" />public String myService(String payload) { ... } クラスの public メソッドにあいまいさがない限り、method 属性を省略できます。
次の例に示すように、POJO メソッドでヘッダー情報を取得することもできます。
@ServiceActivator
public String myService(@Payload String payload, @Header("foo") String fooHeader) { ... }次の例に示すように、メッセージのプロパティを逆参照することもできます。
@ServiceActivator
public String myService(@Payload("payload.foo") String foo, @Header("bar.baz") String barbaz) { ... } さまざまな POJO メソッド呼び出しが利用できるため、5.0 より前のバージョンでは SpEL (Spring Expression Language) を使用して POJO メソッドを呼び出していました。通常、メソッドで実行される実際の作業と比較すると、SpEL (解釈されても) は通常、これらの操作に対して「十分に高速」です。ただし、バージョン 5.0 以降、可能な場合は常に org.springframework.messaging.handler.invocation.InvocableHandlerMethod がデフォルトで使用されます。この手法は通常、解釈された SpEL よりも高速に実行でき、他の Spring メッセージングプロジェクトと一貫性があります。InvocableHandlerMethod は、Spring MVC でコントローラーメソッドを呼び出すために使用される手法に似ています。SpEL の使用時に常に呼び出される特定のメソッドがあります。例には、前に説明したように、参照解除されたプロパティを持つアノテーション付きパラメーターが含まれます。これは、SpEL にはプロパティパスをナビゲートする機能があるためです。
InvocableHandlerMethod インスタンスでは動作しないと考えられている他のいくつかのコーナーケースがあるかもしれません。このため、これらの場合は自動的に SpEL を使用します。
必要に応じて、次の例に示すように、UseSpelInvoker アノテーションを使用して常に SpEL を使用するように POJO メソッドを設定することもできます。
@UseSpelInvoker(compilerMode = "IMMEDIATE")
public void bar(String bar) { ... }compilerMode プロパティを省略すると、spring.expression.compiler.mode システムプロパティがコンパイラーモードを決定します。コンパイルされた SpEL の詳細については、SpEL のコンパイルを参照してください。