3.2.2
リファレンスガイド
このガイドでは、Spring Cloud Stream バインダーの Apache Kafka 実装について説明します。このガイドには、設計、使用方法、構成オプションに関する情報のほか、Stream Cloud Stream の概念が Apache Kafka 固有の構造にどのようにマップされるかに関する情報も含まれています。さらに、このガイドでは、Spring Cloud Stream の Kafka Streams バインディング機能についても説明します。
1. Apache Kafka バインダー
1.1. 使用方法
Apache Kafka バインダーを使用するには、次の Maven の例に示すように、spring-cloud-stream-binder-kafka を Spring Cloud Stream アプリケーションへの依存関係として追加する必要があります。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>または、次の Maven の例に示すように、Spring Cloud Stream Kafka スターターを使用することもできます。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>1.2. 概要
次の図は、Apache Kafka バインダーの動作を簡略化した図を示しています。
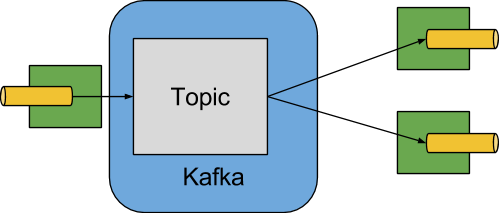
Apache Kafka バインダー実装は、各宛先を Apache Kafka トピックにマップします。コンシューマーグループは同じ Apache Kafka コンセプトに直接マップされます。パーティション分割も Apache Kafka パーティションに直接マップされます。
バインダーは現在、Apache Kafka kafka-clients バージョン 2.3.1 を使用しています。このクライアントは古いブローカーと通信できます (Kafka のドキュメントを参照) が、特定の機能が使用できない場合があります。例: 0.11.x.x より前のバージョンでは、ネイティブヘッダーはサポートされていません。また、0.11.x.x は autoAddPartitions プロパティをサポートしていません。
1.3. 構成オプション
このセクションには、Apache Kafka バインダーで使用される構成オプションが含まれています。
バインダーに関連する一般的な構成オプションとプロパティについては、コアドキュメントのバインディングプロパティを参照 (英語) してください。
1.3.1. Kafka バインダーのプロパティ
- spring.cloud.stream.kafka.binder.brokers
Kafka バインダーが接続するブローカーのリスト。
デフォルト:
localhost.- spring.cloud.stream.kafka.binder.defaultBrokerPort
brokersは、ポート情報の有無にかかわらず指定されたホストを許可します(たとえば、host1,host2:port2)。これにより、ブローカーリストにポートが構成されていない場合のデフォルトポートが設定されます。デフォルト:
9092.- spring.cloud.stream.kafka.binder.configuration
バインダーによって作成されたすべてのクライアントに渡されるクライアントプロパティ(プロデューサーとコンシューマーの両方)のキー / 値マップ。これらのプロパティはプロデューサーとコンシューマーの両方で使用されるため、使用はセキュリティ設定などの共通のプロパティに制限する必要があります。この構成を通じて提供される不明な Kafka プロデューサーまたはコンシューマープロパティは除外され、伝播は許可されません。ここでのプロパティは、Boot で設定されたすべてのプロパティに優先します。
デフォルト: 空の地図。
- spring.cloud.stream.kafka.binder.consumerProperties
任意の Kafka クライアントコンシューマープロパティのキー / 値マップ。既知の Kafka コンシューマープロパティをサポートすることに加えて、未知のコンシューマープロパティもここで許可されます。ここでのプロパティは、boot および上記の
configurationプロパティで設定されたプロパティに優先します。デフォルト: 空の地図。
- spring.cloud.stream.kafka.binder.headers
バインダーによって転送されるカスタムヘッダーのリスト。
kafka-clientsバージョンが 0.11.0.0 未満の古いアプリケーション (⇐ 1.3.x) と通信する場合にのみ必要です。新しいバージョンでは、ヘッダーがネイティブにサポートされます。デフォルト: 空。
- spring.cloud.stream.kafka.binder.healthTimeout
パーティション情報の取得を待機する時間(秒単位)。このタイマーが期限切れになると、ヘルスはダウンとして報告します。
デフォルト: 10.
- spring.cloud.stream.kafka.binder.requiredAcks
ブローカーに必要な ack の数。プロデューサー
acksプロパティについては、Kafka のドキュメントを参照してください。デフォルト:
1.- spring.cloud.stream.kafka.binder.minPartitionCount
autoCreateTopicsまたはautoAddPartitionsが設定されている場合にのみ有効です。バインダーがデータを生成または消費するトピックに構成するパーティションのグローバル最小数。これは、プロデューサーのpartitionCount設定、またはプロデューサーのinstanceCount * concurrency設定の値(どちらか大きい場合)に置き換えることができます。デフォルト:
1.- spring.cloud.stream.kafka.binder.producerProperties
任意の Kafka クライアントプロデューサープロパティのキー / 値マップ。既知の Kafka プロデューサープロパティをサポートすることに加えて、未知のプロデューサープロパティもここで許可されます。ここでのプロパティは、boot および上記の
configurationプロパティで設定されたプロパティに優先します。デフォルト: 空の地図。
- spring.cloud.stream.kafka.binder.replicationFactor
autoCreateTopicsがアクティブな場合、自動作成されたトピックの複製係数。各バインディングでオーバーライドできます。2.4 より前のバージョンの Kafka ブローカーを使用している場合、この値は少なくとも 1に設定する必要があります。バージョン 3.0.8 以降、バインダーは-1をデフォルト値として使用します。これは、ブローカーの "default.replication.factor" プロパティを使用してレプリカの数を決定することを示しています。Kafka ブローカーの管理者に問い合わせて、最小のレプリケーション係数を必要とするポリシーが設定されているかどうかを確認します。その場合、通常、default.replication.factorはその値と一致するため、より大きなレプリケーション係数が必要な場合を除き、最小値の-1を使用する必要があります。デフォルト:
-1.- spring.cloud.stream.kafka.binder.autoCreateTopics
trueに設定すると、バインダーは新しいトピックを自動的に作成します。falseに設定されている場合、バインダーはすでに構成されているトピックに依存します。後者の場合、トピックが存在しないと、バインダーは開始できません。この設定は、ブローカーの auto.create.topics.enable設定とは独立しており、影響を与えません。サーバーがトピックを自動作成するように設定されている場合、デフォルトのブローカー設定でメタデータ取得リクエストの一部として作成される場合があります。デフォルト:
true.- spring.cloud.stream.kafka.binder.autoAddPartitions
trueに設定すると、バインダーは必要に応じて新しいパーティションを作成します。falseに設定されている場合、バインダーは、すでに構成されているトピックのパーティションサイズに依存します。ターゲットトピックのパーティション数が期待値よりも小さい場合、バインダーは開始できません。デフォルト:
false.- spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix
バインダーでのトランザクションを有効にします。Kafka ドキュメントの
transaction.idおよびspring-kafkaドキュメントのトランザクションを参照してください。トランザクションが有効になっている場合、個々のproducerプロパティは無視され、すべてのプロデューサーがspring.cloud.stream.kafka.binder.transaction.producer.*プロパティを使用します。デフォルトの
null(トランザクションなし)- spring.cloud.stream.kafka.binder.transaction.producer.*
トランザクションバインダー内のプロデューサーのグローバルプロデューサープロパティ。
spring.cloud.stream.kafka.binder.transaction.transactionIdPrefixと Kafka プロデューサーのプロパティ、およびすべてのバインダーでサポートされている一般的なプロデューサーのプロパティを参照してください。デフォルト: 個々のプロデューサーのプロパティを参照してください。
- spring.cloud.stream.kafka.binder.headerMapperBeanName
spring-messagingヘッダーと Kafka ヘッダーのマッピングに使用されるKafkaHeaderMapperの Bean 名。たとえば、ヘッダーに JSON 逆直列化を使用するBinderHeaderMapperBean の信頼できるパッケージをカスタマイズする場合にこれを使用します。このカスタムBinderHeaderMapperBean がこのプロパティを使用してバインダーで使用可能になっていない場合、バインダーは、バインダーによって作成されたデフォルトのBinderHeaderMapperにフォールバックする前に、型BinderHeaderMapperのkafkaBinderHeaderMapperという名前のヘッダーマッパー Bean を探します。デフォルト: なし。
- spring.cloud.stream.kafka.binder.considerDownWhenAnyPartitionHasNoLeader
データを受信しているコンシューマーに関係なく、トピック上のパーティションがリーダーなしで見つかった場合、バインダーヘルスを
downとして設定するフラグ。デフォルト:
false.- spring.cloud.stream.kafka.binder.certificateStoreDirectory
トラストストアまたはキーストア証明書の場所がクラスパス URL(
classpath:…)として指定されている場合、バインダーはリソースを JAR ファイル内のクラスパスの場所からファイルシステム上の場所にコピーします。これは、ブローカーレベルの証明書(ssl.truststore.locationおよびssl.keystore.location)とスキーマレジストリ用の証明書(schema.registry.ssl.truststore.locationおよびschema.registry.ssl.keystore.location)の両方に当てはまります。トラストストアとキーストアのクラスパスの場所は、spring.cloud.stream.kafka.binder.configuration…で指定する必要があることに注意してください。例:spring.cloud.stream.kafka.binder.configuration.ssl.truststore.location、`spring.cloud.stream.kafka.binder.configuration.schema.registry.ssl.truststore.locationなど。ファイルは、このプロパティの値として指定された場所に移動されます。この場所は、アプリケーションを実行しているプロセスによって書き込み可能なファイルシステム上の既存のディレクトリである必要があります。この値が設定されておらず、証明書ファイルがクラスパスリソースである場合、System.getProperty("java.io.tmpdir")によって返されるようにシステムの一時ディレクトリに移動されます。この値が存在するが、ディレクトリがファイルシステム上に見つからないか、書き込み可能でない場合も、これは当てはまります。デフォルト: なし。
1.3.2. Kafka コンシューマープロパティ
繰り返しを避けるために、Spring Cloud Stream は、spring.cloud.stream.kafka.default.consumer.<property>=<value> の形式ですべてのチャネルの値を設定することをサポートしています。 |
次のプロパティは Kafka コンシューマーでのみ使用可能であり、接頭辞 spring.cloud.stream.kafka.bindings.<channelName>.consumer. を付ける必要があります。
- admin.configuration
バージョン 2.1.1 以降、このプロパティは
topic.propertiesを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- admin.replicas- 割り当て
バージョン 2.1.1 以降、このプロパティは
topic.replicas-assignmentを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- admin.replication-factor
バージョン 2.1.1 以降、このプロパティは
topic.replication-factorを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- autoRebalanceEnabled
trueの場合、トピックパーティションはコンシューマーグループのメンバー間で自動的に再調整されます。falseの場合、各コンシューマーには、spring.cloud.stream.instanceCountおよびspring.cloud.stream.instanceIndexに基づいてパーティションの固定セットが割り当てられます。これには、spring.cloud.stream.instanceCountプロパティとspring.cloud.stream.instanceIndexプロパティの両方を、起動された各インスタンスで適切に設定する必要があります。この場合、spring.cloud.stream.instanceCountプロパティの値は通常 1 より大きくなければなりません。デフォルト:
true.- ackEachRecord
autoCommitOffsetがtrueの場合、この設定は各レコードが処理された後にオフセットをコミットするかどうかを決定します。デフォルトでは、オフセットはconsumer.poll()によって返されたレコードのバッチ内のすべてのレコードが処理された後にコミットされます。ポーリングによって返されるレコードの数は、コンシューマーconfigurationプロパティを通じて設定されるmax.poll.recordsKafka プロパティで制御できます。これをtrueに設定するとパフォーマンスが低下する可能性がありますが、そうすることで障害発生時にレコードが再配信される可能性が低くなります。また、バインダーrequiredAcksプロパティも参照してください。これもオフセットのコミットのパフォーマンスに影響します。このプロパティは 3.1 以降は非推奨となり、代わりにackModeを使用してください。ackModeが設定されておらず、バッチモードが有効になっていない場合は、RECORDackMode が使用されます。デフォルト:
false.- autoCommitOffset
バージョン 3.1 以降、このプロパティは非推奨になりました。代替案の詳細については、
ackModeを参照してください。メッセージが処理されたときにオフセットを自動コミットするかどうか。falseに設定されている場合、型org.springframework.kafka.support.Acknowledgmentヘッダーのキーkafka_acknowledgmentを持つヘッダーが受信メッセージに存在します。アプリケーションは、メッセージの確認にこのヘッダーを使用できます。詳細については、例のセクションを参照してください。このプロパティがfalseに設定されている場合、Kafka バインダーは ack モードをorg.springframework.kafka.listener.AbstractMessageListenerContainer.AckMode.MANUALに設定し、アプリケーションはレコードの確認を担当します。ackEachRecordも参照してください。デフォルト:
true.- ackMode
コンテナーの ack モードを指定します。これは、Spring Kafka で定義されている AckMode 列挙に基づいています。
ackEachRecordプロパティがtrueに設定されていて、コンシューマーがバッチモードでない場合、これはRECORDの ack モードを使用します。それ以外の場合は、このプロパティを使用して提供された ack モードを使用します。- autoCommitOnError
ポーリング可能なコンシューマーでは、
trueに設定されている場合、エラー時に常に自動コミットします。設定されていない場合(デフォルト)または false の場合、ポーリング可能なコンシューマーで自動コミットされません。このプロパティは、ポーリング可能なコンシューマーにのみ適用されることに注意してください。デフォルト: 未設定。
- resetOffsets
コンシューマーのオフセットを startOffset によって提供された値にリセットするかどうか。
KafkaBindingRebalanceListenerが指定されている場合は false にする必要があります。KafkaBindingRebalanceListener を使用するを参照してください。このプロパティの詳細については、オフセットのリセットを参照してください。デフォルト:
false.- startOffset
新しいグループの開始オフセット。許可される値:
earliestおよびlatest。コンシューマーグループがコンシューマー ' バインディング ' に対して明示的に設定されている場合 (spring.cloud.stream.bindings.<channelName>.group経由)、"startOffset" はearliestに設定されます。それ以外の場合は、anonymousコンシューマーグループに対してlatestに設定されます。このプロパティの詳細については、オフセットのリセットを参照してください。デフォルト: null(
earliestと同等)。- enableDlq
true に設定すると、コンシューマーの DLQ 動作が有効になります。デフォルトでは、エラーが発生するメッセージは
error.<destination>.<group>という名前のトピックに転送されます。DLQ トピック名は、dlqNameプロパティを設定するか、型DlqDestinationResolverの@Beanを定義することによって構成できます。これは、エラーの数が比較的少なく、元のトピック全体を再生するのが面倒な場合に、より一般的な Kafka 再生シナリオの代替オプションを提供します。詳細については、デッドレタートピック処理処理を参照してください。バージョン 2.0 以降、DLQ トピックに送信されるメッセージは、次のヘッダーで拡張されます:x-original-topic、x-exception-message、x-exception-stacktraceasbyte[]。デフォルトでは、失敗したレコードは、DLQ トピック内の元のレコードと同じパーティション番号に送信されます。その動作を変更する方法については、デッドレタートピックパーティションの選択を参照してください。destinationIsPatternがtrueの場合は許可されません。デフォルト:
false.- dlqPartitions
enableDlqが true で、このプロパティが設定されていない場合、プライマリトピックと同じ数のパーティションを持つデッドレタートピックが作成されます。通常、デッドレターレコードは、デッドレタートピック内の元のレコードと同じパーティションに送信されます。この動作は変更できます。デッドレタートピックパーティションの選択を参照してください。このプロパティが1に設定されていて、DqlPartitionFunctionBean がない場合、すべての送達不能レコードはパーティション0に書き込まれます。このプロパティが1より大きい場合、MUST はDlqPartitionFunctionBean を提供します。実際のパーティション数は、バインダーのminPartitionCountプロパティの影響を受けることに注意してください。デフォルト:
none- 構成
一般的な Kafka コンシューマープロパティを含むキーと値のペアを使用してマップします。Kafka コンシューマープロパティに加えて、他の構成プロパティをここに渡すことができます。たとえば、
spring.cloud.stream.kafka.bindings.input.consumer.configuration.foo=barなどのアプリケーションに必要ないくつかのプロパティ。ここではbootstrap.serversプロパティを設定できません。複数のクラスターに接続する必要がある場合は、マルチバインダーサポートを使用してください。デフォルト: 空の地図。
- dlqName
エラーメッセージを受信する DLQ トピックの名前。
デフォルト: null(指定されていない場合、エラーが発生するメッセージは
error.<destination>.<group>という名前のトピックに転送されます)。- dlqProducerProperties
これを使用して、DLQ 固有のプロデューサープロパティを設定できます。Kafka プロデューサープロパティを通じて使用できるすべてのプロパティは、このプロパティを通じて設定できます。コンシューマーでネイティブデコードが有効になっている場合 (つまり、useNativeDecoding: true)、アプリケーションは DLQ に対応するキー / 値シリアライザーを提供する必要があります。これは、
dlqProducerProperties.configuration.key.serializerおよびdlqProducerProperties.configuration.value.serializerの形式で提供する必要があります。デフォルト: デフォルトの Kafka プロデューサープロパティ。
- standardHeaders
受信チャネルアダプターによって入力される標準ヘッダーを示します。許可される値:
none、id、timestamp、またはboth。ネイティブの逆直列化を使用していて、メッセージを受信する最初のコンポーネントにid(JDBC メッセージストアを使用するように構成されたアグリゲーターなど)が必要な場合に便利です。デフォルト:
none- converterBeanName
RecordMessageConverterを実装する Bean の名前。デフォルトのMessagingMessageConverterを置き換えるために、受信チャネルアダプターで使用されます。デフォルト:
null- idleEventInterval
メッセージが最近受信されていないことを示すイベント間の間隔(ミリ秒単位)。これらのイベントを受信するには、
ApplicationListener<ListenerContainerIdleEvent>を使用してください。使用例については、サンプル: コンシューマーの一時停止と再開を参照してください。デフォルト:
30000- destinationIsPattern
true の場合、宛先は、ブローカーによってトピック名を照合するために使用される正規表現
Patternとして扱われます。true の場合、トピックはプロビジョニングされず、enableDlqは許可されません。これは、バインダーがプロビジョニングフェーズ中にトピック名を認識しないためです。パターンに一致する新しいトピックを検出するのにかかる時間は、コンシューマープロパティmetadata.max.age.msによって制御されることに注意してください。これは、(執筆時点では)デフォルトで 300,000ms(5 分)です。これは、上記のconfigurationプロパティを使用して構成できます。デフォルト:
false- topic.properties
新しいトピックをプロビジョニングするときに使用される Kafka トピックプロパティの
Map(たとえば、spring.cloud.stream.kafka.bindings.input.consumer.topic.properties.message.format.version=0.9.0.0)デフォルト: なし。
- topic.replicas- 割り当て
レプリカ割り当ての Map <Integer、List <Integer >>。キーはパーティション、値は割り当てです。新しいトピックをプロビジョニングするときに使用されます。
kafka-clientsjar のNewTopicJavadoc を参照してください。デフォルト: なし。
- topic.replication-factor
トピックをプロビジョニングするときに使用するレプリケーション係数。バインダー全体の設定を上書きします。
replicas-assignmentsが存在する場合は無視されます。デフォルト: none(バインダー全体のデフォルトである -1 が使用されます)。
- pollTimeout
ポーリング可能なコンシューマーでのポーリングに使用されるタイムアウト。
デフォルト: 5 秒。
- transactionManager
このバインディングのバインダーのトランザクションマネージャーをオーバーライドするために使用される
KafkaAwareTransactionManagerの Bean 名。通常、ChainedKafkaTransactionManaagerを使用して、別のトランザクションを Kafka トランザクションと同期する場合に必要です。レコードの消費と生成を 1 回だけ実行するには、コンシューマーとプロデューサーのバインディングをすべて同じトランザクションマネージャーで構成する必要があります。デフォルト: なし。
- txCommitRecovered
トランザクションバインダーを使用する場合、復元されたレコードのオフセット(たとえば、再試行が終了し、レコードがデッドレタートピックに送信された場合)は、デフォルトで新しいトランザクションを介してコミットされます。このプロパティを
falseに設定すると、リカバリされたレコードのオフセットのコミットが抑制されます。デフォルト: true。
- commonErrorHandlerBeanName
CommonErrorHandlerBean 名前。コンシューマーバインディングごとに使用します。存在する場合、このユーザーが提供したCommonErrorHandlerは、バインダーによって定義された他のエラーハンドラーよりも優先されます。これは、アプリケーションがListenerContainerCustomizerを使用したくない場合に、エラーハンドラーを表現するための便利な方法であり、宛先とグループの組み合わせをチェックしてエラーハンドラーを設定します。デフォルト: なし。
1.3.3. オフセットのリセット
アプリケーションが起動すると、割り当てられた各パーティションの初期位置は、2 つのプロパティ startOffset と resetOffsets に依存します。resetOffsets が false の場合、通常の Kafka コンシューマー auto.offset.reset [Apache] (英語) セマンティクスが適用されます。つまり、バインディングのコンシューマーグループのパーティションにコミットされたオフセットがない場合、位置は earliest または latest です。デフォルトでは、明示的な group を使用したバインディングは earliest を使用し、匿名のバインディング(group を使用しない)は latest を使用します。これらのデフォルトは、startOffset バインディングプロパティを設定することで上書きできます。特定の group で初めてバインディングが開始されたとき、コミットされたオフセットはありません。コミットされたオフセットが存在しないもう 1 つの条件は、オフセットの有効期限が切れているかどうかです。最新のブローカー(2.1 以降)およびデフォルトのブローカープロパティでは、最後のメンバーがグループを離れてから 7 日後にオフセットの有効期限が切れます。詳細については、offsets.retention.minutes [Apache] (英語) ブローカーのプロパティを参照してください。
resetOffsets が true の場合、バインダーは、このバインディングがトピックから消費されたことがないかのように、ブローカーにコミットされたオフセットがない場合に適用されるセマンティクスと同様のセマンティクスを適用します。つまり、現在コミットされているオフセットは無視されます。
以下は、これが使用される可能性のある 2 つのユースケースです。
キーと値のペアを含む圧縮されたトピックからの消費。
resetOffsetsをtrueに、startOffsetをearliestに設定します。バインディングは、新しく割り当てられたすべてのパーティションでseekToBeginningを実行します。イベントを含むトピックから消費します。このトピックでは、このバインディングの実行中に発生するイベントのみに関心があります。
resetOffsetsをtrueに、startOffsetをlatestに設定します。バインディングは、新しく割り当てられたすべてのパーティションでseekToEndを実行します。
| 最初の割り当て後にリバランスが発生した場合、シークは、最初の割り当て中に割り当てられなかった、新しく割り当てられたパーティションに対してのみ実行されます。 |
トピックオフセットの詳細な制御については、KafkaBindingRebalanceListener を使用するを参照してください。リスナーが提供されている場合、resetOffsets を true に設定しないでください。設定しないと、エラーが発生します。
1.3.4. バッチの消費
バージョン 3.0 以降、spring.cloud.stream.binding.<name>.consumer.batch-mode が true に設定されている場合、Kafka Consumer のポーリングによって受信されたすべてのレコードは、List<?> としてリスナーメソッドに提示されます。それ以外の場合、メソッドは一度に 1 つのレコードで呼び出されます。バッチのサイズは、Kafka コンシューマープロパティ max.poll.records、fetch.min.bytes、fetch.max.wait.ms によって制御されます。詳細については、Kafka のドキュメントを参照してください。
バッチモードは @StreamListener ではサポートされていないことに注意してください。これは、新しい関数型プログラミングモデルでのみ機能します。
バッチモードを使用する場合、バインダー内での再試行はサポートされないため、maxAttempts は 1 にオーバーライドされます。バインダーで再試行する同様の機能を実現するように SeekToCurrentBatchErrorHandler を構成できます(ListenerContainerCustomizer を使用)。手動の AckMode を使用し、Ackowledgment.nack(index, sleep) を呼び出して、部分バッチのオフセットをコミットし、残りのレコードを再配信することもできます。これらの手法の詳細については、Spring for Apache Kafka ドキュメントを参照してください。 |
1.3.5. Kafka プロデューサーのプロパティ
繰り返しを避けるために、Spring Cloud Stream は、spring.cloud.stream.kafka.default.producer.<property>=<value> の形式ですべてのチャネルの値を設定することをサポートしています。 |
次のプロパティは Kafka プロデューサーのみが使用でき、接頭辞 spring.cloud.stream.kafka.bindings.<channelName>.producer. を付ける必要があります。
- admin.configuration
バージョン 2.1.1 以降、このプロパティは
topic.propertiesを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- admin.replicas- 割り当て
バージョン 2.1.1 以降、このプロパティは
topic.replicas-assignmentを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- admin.replication-factor
バージョン 2.1.1 以降、このプロパティは
topic.replication-factorを優先して非推奨になり、将来のバージョンでサポートが削除される予定です。- bufferSize
Kafka プロデューサーが送信する前にバッチ処理を試みるデータ量の上限(バイト単位)。
デフォルト:
16384.- 同期
プロデューサーが同期しているかどうか。
デフォルト:
false.- sendTimeoutExpression
同期公開が有効になっている場合に ack を待機する時間を評価するために使用される送信メッセージに対して評価される SpEL 式(たとえば、
headers['mySendTimeout'])。タイムアウトの値はミリ秒単位です。3.0 より前のバージョンでは、ネイティブエンコーディングが使用されていない限り、ペイロードを使用できませんでした。この式が評価されるまでに、ペイロードはすでにbyte[]の形式であったためです。これで、ペイロードが変換される前に式が評価されます。デフォルト:
none.- batchTimeout
メッセージを送信する前に、プロデューサーが同じバッチにさらに多くのメッセージが蓄積されるのを待機する時間。(通常、プロデューサーはまったく待機せず、前の送信の進行中に蓄積されたすべてのメッセージを送信するだけです)ゼロ以外の値は、待ち時間を犠牲にしてスループットを向上させる可能性があります。
デフォルト:
0.- messageKeyExpression
生成された Kafka メッセージのキーを設定するために使用される発信メッセージ(たとえば、
headers['myKey'])に対して評価された SpEL 式。3.0 より前のバージョンでは、ネイティブエンコーディングが使用されていない限り、ペイロードを使用できませんでした。この式が評価されるまでに、ペイロードはすでにbyte[]の形式であったためです。これで、ペイロードが変換される前に式が評価されます。通常のプロセッサー(Function<String, String>またはFunction<Message<?>, Message<?>)の場合、生成されたキーがトピックからの受信キーと同じである必要がある場合、このプロパティは次のように設定できます。spring.cloud.stream.kafka.bindings.<output-binding-name>.producer.messageKeyExpression: headers['kafka_receivedMessageKey']リアクティブ機能について覚えておくべき重要な警告があります。その場合、受信メッセージから発信メッセージにヘッダーを手動でコピーするのはアプリケーションの責任です。ヘッダーを設定できます。例:myKeyを使用し、上記のようにheaders['myKey']を使用するか、便宜上、KafkaHeaders.MESSAGE_KEYヘッダーを設定するだけで、このプロパティを設定する必要はまったくありません。デフォルト:
none.- headerPatterns
ProducerRecordの KafkaHeadersにマップされる Spring メッセージングヘッダーに一致する単純なパターンのコンマ区切りリスト。パターンは、ワイルドカード文字(アスタリスク)で開始または終了できます。パターンは、接頭辞!を付けることで無効にできます。一致は最初の一致(正または負)の後に停止します。たとえば、!ask,as*はashを渡しますが、askは渡しません。idとtimestampはマップされません。デフォルト:
*(すべてのヘッダー -idとtimestampを除く)- 構成
一般的な Kafka プロデューサープロパティを含むキー / 値ペアを使用してマップします。ここでは
bootstrap.serversプロパティを設定できません。複数のクラスターに接続する必要がある場合は、マルチバインダーサポートを使用してください。デフォルト: 空の地図。
- topic.properties
新しいトピックをプロビジョニングするときに使用される Kafka トピックプロパティの
Map(たとえば、spring.cloud.stream.kafka.bindings.output.producer.topic.properties.message.format.version=0.9.0.0)- topic.replicas- 割り当て
レプリカ割り当ての Map <Integer、List <Integer >>。キーはパーティション、値は割り当てです。新しいトピックをプロビジョニングするときに使用されます。
kafka-clientsjar のNewTopicJavadoc を参照してください。デフォルト: なし。
- topic.replication-factor
トピックをプロビジョニングするときに使用するレプリケーション係数。バインダー全体の設定を上書きします。
replicas-assignmentsが存在する場合は無視されます。デフォルト: none(バインダー全体のデフォルトである -1 が使用されます)。
- useTopicHeader
trueに設定すると、デフォルトのバインディング宛先(トピック名)が送信メッセージのKafkaHeaders.TOPICメッセージヘッダーの値で上書きされます。ヘッダーが存在しない場合は、デフォルトのバインディング宛先が使用されます。デフォルト:
false.- recordMetadataChannel
正常な送信結果の送信先となる
MessageChannelの Bean 名。Bean はアプリケーションコンテキストに存在する必要があります。チャネルに送信されるメッセージは、追加のヘッダーKafkaHeaders.RECORD_METADATAを含む送信済みメッセージ(変換後)です。ヘッダーには、Kafka クライアントによって提供されるRecordMetadataオブジェクトが含まれています。これには、トピックでレコードが書き込まれたパーティションとオフセットが含まれます。ResultMetadata meta = sendResultMsg.getHeaders().get(KafkaHeaders.RECORD_METADATA, RecordMetadata.class)失敗した送信は、プロデューサーエラーチャネルに送信されます(構成されている場合)。エラーチャネルを参照してください。
デフォルト: null。
Kafka バインダーは、プロデューサーの partitionCount 設定をヒントとして使用して、指定されたパーティション数でトピックを作成します(minPartitionCount と組み合わせて、2 つのうち最大のものが使用される値です)。大きい方の値が使用されるため、バインダー用の minPartitionCount とアプリケーション用の partitionCount の両方を構成する場合は注意が必要です。パーティション数が少ないトピックがすでに存在し、autoAddPartitions が無効(デフォルト)の場合、バインダーは開始に失敗します。パーティション数が少ないトピックがすでに存在し、autoAddPartitions が有効になっている場合は、新しいパーティションが追加されます。最大数(minPartitionCount または partitionCount)よりも多くのパーティションを持つトピックがすでに存在する場合は、既存のパーティション数が使用されます。 |
- 圧縮
compression.typeプロデューサープロパティを設定します。サポートされている値はnone、gzip、snappy、lz4、zstdです。Spring for Apache Kafka ドキュメントで説明したように、kafka-clientsjar を 2.1.0(またはそれ以降)にオーバーライドし、zstd圧縮を使用する場合は、spring.cloud.stream.kafka.bindings.<binding-name>.producer.configuration.compression.type=zstdを使用します。デフォルト:
none.- transactionManager
このバインディングのバインダーのトランザクションマネージャーをオーバーライドするために使用される
KafkaAwareTransactionManagerの Bean 名。通常、ChainedKafkaTransactionManaagerを使用して、別のトランザクションを Kafka トランザクションと同期する場合に必要です。レコードの消費と生成を 1 回だけ実行するには、コンシューマーとプロデューサーのバインディングをすべて同じトランザクションマネージャーで構成する必要があります。デフォルト: なし。
- closeTimeout
プロデューサーを閉じるときに待機する秒数のタイムアウト。
デフォルト:
30- allowNonTransactional
通常、トランザクションバインダーに関連付けられているすべての出力バインディングは、まだ処理されていない場合は、新しいトランザクションで公開されます。このプロパティを使用すると、その動作をオーバーライドできます。true に設定すると、この出力バインディングに公開されたレコードは、すでに処理中でない限り、トランザクションで実行されません。
デフォルト:
false
1.3.6. 使用例
このセクションでは、特定のシナリオでの前述のプロパティの使用箇所を示します。
サンプル: ackMode を MANUAL に設定し、手動確認に依存する
この例は、コンシューマーアプリケーションでオフセットを手動で確認する方法を示しています。
この例では、spring.cloud.stream.kafka.bindings.input.consumer.ackMode を MANUAL に設定する必要があります。例として、対応する入力チャネル名を使用してください。
@SpringBootApplication
@EnableBinding(Sink.class)
public class ManuallyAcknowdledgingConsumer {
public static void main(String[] args) {
SpringApplication.run(ManuallyAcknowdledgingConsumer.class, args);
}
@StreamListener(Sink.INPUT)
public void process(Message<?> message) {
Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (acknowledgment != null) {
System.out.println("Acknowledgment provided");
acknowledgment.acknowledge();
}
}
}サンプル: セキュリティ構成
Apache Kafka 0.9 は、クライアントとブローカー間の安全な接続をサポートします。この機能を活用するには、Confluent ドキュメントの Apache Kafka ドキュメント (英語) のガイドラインと Kafka 0.9 セキュリティガイドラインに従ってください。バインダーによって作成されたすべてのクライアントのセキュリティプロパティを設定するには、spring.cloud.stream.kafka.binder.configuration オプションを使用します。
例: security.protocol を SASL_SSL に設定するには、次のプロパティを設定します。
spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_SSL他のすべてのセキュリティプロパティも同様の方法で設定できます。
Kerberos を使用する場合は、JAAS 構成を作成および参照するためのリファレンスドキュメントの指示に従 [Apache] (英語) ってください。
Spring Cloud Stream は、JAAS 構成ファイルと Spring Boot プロパティを使用して、アプリケーションへの JAAS 構成情報の受け渡しをサポートします。
JAAS 構成ファイルの使用
JAAS および(オプションで)krb5 ファイルの場所は、システムプロパティを使用して Spring Cloud Stream アプリケーション用に設定できます。次の例は、JAAS 構成ファイルを使用して SASL および Kerberos で Spring Cloud Stream アプリケーションを起動する方法を示しています。
java -Djava.security.auth.login.config=/path.to/kafka_client_jaas.conf -jar log.jar \
--spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXTSpring Boot プロパティの使用
JAAS 構成ファイルを持つ代わりに、Spring Cloud Stream は、Spring Boot プロパティを使用して Spring Cloud Stream アプリケーションの JAAS 構成をセットアップするためのメカニズムを提供します。
次のプロパティを使用して、Kafka クライアントのログインコンテキストを構成できます。
- spring.cloud.stream.kafka.binder.jaas.loginModule
ログインモジュール名。通常は設定する必要はありません。
デフォルト:
com.sun.security.auth.module.Krb5LoginModule.- spring.cloud.stream.kafka.binder.jaas.controlFlag
ログインモジュールの制御フラグ。
デフォルト:
required.- spring.cloud.stream.kafka.binder.jaas.options
ログインモジュールオプションを含むキーと値のペアでマップします。
デフォルト: 空の地図。
次の例は、Spring Boot 構成プロパティを使用して SASL および Kerberos で Spring Cloud Stream アプリケーションを起動する方法を示しています。
java --spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.autoCreateTopics=false \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT \
--spring.cloud.stream.kafka.binder.jaas.options.useKeyTab=true \
--spring.cloud.stream.kafka.binder.jaas.options.storeKey=true \
--spring.cloud.stream.kafka.binder.jaas.options.keyTab=/etc/security/keytabs/kafka_client.keytab \
--spring.cloud.stream.kafka.binder.jaas.options.principal=kafka-client-1@EXAMPLE.COM上記の例は、次の JAAS ファイルに相当するものを表しています。
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_client.keytab"
principal="[email protected] (英語) ";
};必要なトピックがブローカーにすでに存在する場合、または管理者によって作成される場合は、自動作成をオフにして、クライアント JAAS プロパティのみを送信する必要があります。
同じアプリケーションで JAAS 構成ファイルと Spring Boot プロパティを混在させないでください。-Djava.security.auth.login.config システムプロパティがすでに存在する場合、Spring Cloud Stream は Spring Boot プロパティを無視します。 |
Kerberos で autoCreateTopics および autoAddPartitions を使用する場合は注意してください。通常、アプリケーションは、Kafka および Zookeeper で管理者権限を持たないプリンシパルを使用することがあります。Spring Cloud Stream に依存してトピックを作成 / 変更すると失敗する可能性があります。安全な環境では、Kafka ツールを使用してトピックを作成し、ACL を管理的に管理することを強くお勧めします。 |
マルチバインダー構成と JAAS
それぞれが個別の JAAS 構成を必要とする複数のクラスターに接続する場合は、プロパティ sasl.jaas.config を使用して JAAS 構成を設定します。このプロパティがアプリケーションに存在する場合、上記の他の戦略よりも優先されます。詳細については、この KIP-85 [Apache] (英語) を参照してください。
例: アプリケーションに別々の JAAS 構成を持つ 2 つのクラスターがある場合、使用できるテンプレートは次のとおりです。
spring.cloud.stream:
binders:
kafka1:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
configuration.sasl.jaas.config: "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"admin\" password=\"admin-secret\";"
kafka2:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9093
configuration.sasl.jaas.config: "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"user1\" password=\"user1-secret\";"
kafka.binder:
configuration:
security.protocol: SASL_PLAINTEXT
sasl.mechanism: PLAIN 上記の構成では、Kafka クラスターとそれぞれの sasl.jaas.config 値の両方が異なることに注意してください。
このようなアプリケーションをセットアップして実行する方法の詳細については、このサンプルアプリケーション [GitHub] (英語) を参照してください。
サンプル: コンシューマーの一時停止と再開
消費を一時停止したいが、パーティションのリバランスを引き起こしたくない場合は、コンシューマーを一時停止して再開できます。これは、State.PAUSED および State.RESUMED を使用して、Spring Cloud Stream ドキュメントの結合の視覚化と制御に示されているようにバインディングライフサイクルを管理することによって容易になります。
再開するには、ApplicationListener (または @EventListener メソッド)を使用して ListenerContainerIdleEvent インスタンスを受信できます。イベントが公開される頻度は、idleEventInterval プロパティによって制御されます。
1.4. トランザクションバインダー
spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix を空でない値に設定して、トランザクションを有効にします。tx-。プロセッサーアプリケーションで使用される場合、コンシューマーはトランザクションを開始します。コンシューマースレッドで送信されたすべてのレコードは、同じトランザクションに参加します。リスナーが正常に終了すると、リスナーコンテナーはオフセットをトランザクションに送信し、コミットします。spring.cloud.stream.kafka.binder.transaction.producer.* プロパティを使用して構成されたすべてのプロデューサーバーインディングには、共通のプロデューサーファクトリが使用されます。個々のバインディング Kafka プロデューサープロパティは無視されます。
通常のバインダーの再試行(およびデッドレタリング)は、トランザクションではサポートされていません。再試行は元のトランザクションで実行されるため、ロールバックされる可能性があり、公開されたレコードもロールバックされます。再試行が有効になっている場合(共通プロパティ maxAttempts がゼロより大きい場合)、再試行プロパティを使用して、コンテナーレベルで再試行を有効にするように DefaultAfterRollbackProcessor を構成します。同様に、トランザクション内で配信不能レコードを公開する代わりに、この機能は、メイントランザクションがロールバックされた後に実行される DefaultAfterRollbackProcessor を介して、リスナーコンテナーに移動されます。 |
ソースアプリケーションで、またはプロデューサーのみのトランザクション(@Scheduled メソッドなど)の任意のスレッドからトランザクションを使用する場合は、トランザクションプロデューサーファクトリへの参照を取得し、それを使用して KafkaTransactionManager Bean を定義する必要があります。
@Bean
public PlatformTransactionManager transactionManager(BinderFactory binders,
@Value("${unique.tx.id.per.instance}") String txId) {
ProducerFactory<byte[], byte[]> pf = ((KafkaMessageChannelBinder) binders.getBinder(null,
MessageChannel.class)).getTransactionalProducerFactory();
KafkaTransactionManager tm = new KafkaTransactionManager<>(pf);
tm.setTransactionId(txId)
return tm;
}BinderFactory を使用してバインダーへの参照を取得していることに注意してください。バインダーが 1 つしか構成されていない場合は、最初の引数で null を使用します。複数のバインダーが構成されている場合は、バインダー名を使用して参照を取得します。バインダーへの参照を取得したら、ProducerFactory への参照を取得して、トランザクションマネージャーを作成できます。
次に、通常の Spring トランザクションサポートを使用します。TransactionTemplate または @Transactional、例:
public static class Sender {
@Transactional
public void doInTransaction(MessageChannel output, List<String> stuffToSend) {
stuffToSend.forEach(stuff -> output.send(new GenericMessage<>(stuff)));
}
} プロデューサーのみのトランザクションを他のトランザクションマネージャーからのトランザクションと同期する場合は、ChainedTransactionManager を使用します。
アプリケーションの複数のインスタンスをデプロイする場合、各インスタンスには一意の transactionIdPrefix が必要です。 |
1.5. エラーチャネル
バージョン 1.3 以降、バインダーは各コンシューマー宛先のエラーチャネルに無条件に例外を送信し、非同期プロデューサー送信エラーをエラーチャネルに送信するように構成することもできます。詳細については、エラー処理に関するこのセクション (英語) を参照してください。
送信失敗の ErrorMessage のペイロードは、次のプロパティを持つ KafkaSendFailureException です。
failedMessage: 送信に失敗した Spring メッセージングMessage<?>。record:failedMessageから作成された生のProducerRecord
プロデューサーの例外(デッドレターキューへの送信など)の自動処理はありません。これらの例外は、独自の Spring Integration フローで使用できます。
1.6. Kafka メトリクス
Kafka バインダーモジュールは、次のメトリクスを公開します。
spring.cloud.stream.binder.kafka.offset: このメトリクスは、特定のコンシューマーグループによって特定のバインダーのトピックからまだ消費されていないメッセージの数を示します。提供されるメトリクスは、Micrometer ライブラリに基づいています。Micrometer がクラスパス上にあり、アプリケーションによって他のそのような Bean が提供されていない場合、バインダーは KafkaBinderMetrics Bean を作成します。メトリクスには、コンシューマーグループ情報、トピック、トピックの最新のオフセットからのコミットされたオフセットの実際のラグが含まれます。このメトリクスは、PaaS プラットフォームに自動スケーリングフィードバックを提供する場合に特に役立ちます。
アプリケーションで次のコンポーネントを提供することにより、KafkaBinderMetrics をコンシューマーなどの必要なインフラストラクチャの作成から除外し、メトリクスをレポートすることができます。
@Component
class NoOpBindingMeters {
NoOpBindingMeters(MeterRegistry registry) {
registry.config().meterFilter(
MeterFilter.denyNameStartsWith(KafkaBinderMetrics.OFFSET_LAG_METRIC_NAME));
}
}メーターを選択的に抑制する方法の詳細については、こちらを参照してください (英語) 。
1.7. Tombstone レコード (null レコード値)
圧縮されたトピックを使用する場合、null 値を持つレコード (tombstone レコードとも呼ばれます) はキーの削除を表します。@StreamListener メソッドでこのようなメッセージを受信するには、パラメーターを null 値引数の受信に不要としてマークする必要があります。
@StreamListener(Sink.INPUT)
public void in(@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) byte[] key,
@Payload(required = false) Customer customer) {
// customer is null if a tombstone record
...
}1.8. KafkaBindingRebalanceListener を使用する
アプリケーションは、パーティションが最初に割り当てられたときに任意のオフセットにトピック / パーティションを探すか、コンシューマーで他の操作を実行したい場合があります。バージョン 2.1 以降、アプリケーションコンテキストで単一の KafkaBindingRebalanceListener Bean を提供すると、すべての Kafka コンシューマーバインディングに接続されます。
public interface KafkaBindingRebalanceListener {
/**
* Invoked by the container before any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedBeforeCommit(String bindingName, Consumer<?, ?> consumer,
Collection<TopicPartition> partitions) {
}
/**
* Invoked by the container after any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedAfterCommit(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
}
/**
* Invoked when partitions are initially assigned or after a rebalance.
* Applications might only want to perform seek operations on an initial assignment.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
* @param initial true if this is the initial assignment.
*/
default void onPartitionsAssigned(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions,
boolean initial) {
}
} リバランスリスナーを提供する場合、resetOffsets コンシューマープロパティを true に設定することはできません。
1.9. 再試行とデッドレター処理
デフォルトでは、コンシューマーバインディングで再試行(maxAttemts など)と enableDlq を構成すると、これらの機能はバインダー内で実行され、リスナーコンテナーや Kafka コンシューマーは関与しません。
次のように、この機能をリスナーコンテナーに移動することが望ましい場合があります。
再試行と遅延の合計は、コンシューマーの
max.poll.interval.msプロパティを超え、パーティションのリバランスを引き起こす可能性があります。デッドレターを別の Kafka クラスターに公開したいとします。
エラーハンドラーに再試行リスナーを追加したいとします。
…
この機能をバインダーからコンテナーに移動するように構成するには、型 ListenerContainerWithDlqAndRetryCustomizer の @Bean を定義します。このインターフェースには次のメソッドがあります。
/**
* Configure the container.
* @param container the container.
* @param destinationName the destination name.
* @param group the group.
* @param dlqDestinationResolver a destination resolver for the dead letter topic (if
* enableDlq).
* @param backOff the backOff using retry properties (if configured).
* @see #retryAndDlqInBinding(String, String)
*/
void configure(AbstractMessageListenerContainer<?, ?> container, String destinationName, String group,
@Nullable BiFunction<ConsumerRecord<?, ?>, Exception, TopicPartition> dlqDestinationResolver,
@Nullable BackOff backOff);
/**
* Return false to move retries and DLQ from the binding to a customized error handler
* using the retry metadata and/or a {@code DeadLetterPublishingRecoverer} when
* configured via
* {@link #configure(AbstractMessageListenerContainer, String, String, BiFunction, BackOff)}.
* @param destinationName the destination name.
* @param group the group.
* @return true to disable retrie in the binding
*/
default boolean retryAndDlqInBinding(String destinationName, String group) {
return true;
} 宛先リゾルバーと BackOff は、バインディングプロパティ(構成されている場合)から作成されます。次に、これらを使用して、カスタムエラーハンドラーとデッドレターパブリッシャーを作成できます。例:
@Bean
ListenerContainerWithDlqAndRetryCustomizer cust(KafkaTemplate<?, ?> template) {
return new ListenerContainerWithDlqAndRetryCustomizer() {
@Override
public void configure(AbstractMessageListenerContainer<?, ?> container, String destinationName,
String group,
@Nullable BiFunction<ConsumerRecord<?, ?>, Exception, TopicPartition> dlqDestinationResolver,
@Nullable BackOff backOff) {
if (destinationName.equals("topicWithLongTotalRetryConfig")) {
ConsumerRecordRecoverer dlpr = new DeadLetterPublishingRecoverer(template),
dlqDestinationResolver);
container.setCommonErrorHandler(new DefaultErrorHandler(dlpr, backOff));
}
}
@Override
public boolean retryAndDlqInBinding(String destinationName, String group) {
return !destinationName.contains("topicWithLongTotalRetryConfig");
}
};
} これで、1 回の再試行遅延のみがコンシューマーの max.poll.interval.ms プロパティより大きくなる必要があります。
1.10. コンシューマーとプロデューサーの構成のカスタマイズ
Kafka で ConsumerFactory および ProducerFactory を作成するために使用されるコンシューマーおよびプロデューサー構成の高度なカスタマイズが必要な場合は、以下のカスタマイザーを実装できます。
ConsumerConfigCustomizer
ProducerConfigCustomizer
これらのインターフェースは両方とも、コンシューマーおよびプロデューサーのプロパティに使用される構成マップを構成する方法を提供します。例: アプリケーションレベルで定義されている Bean にアクセスしたい場合は、configure メソッドの実装にそれを挿入できます。バインダーは、これらのカスタマイザーが Bean として使用可能であることを検出すると、コンシューマーファクトリとプロデューサーファクトリを作成する直前に configure メソッドを呼び出します。
これらのインターフェースは両方とも、バインディング名と宛先名の両方へのアクセスを提供するため、プロデューサーとコンシューマーのプロパティをカスタマイズしながらアクセスできます。
1.11. AdminClient 構成のカスタマイズ
上記のコンシューマーおよびプロデューサー構成のカスタマイズと同様に、アプリケーションは AdminClientConfigCustomizer を提供することにより、管理クライアントの構成をカスタマイズすることもできます。AdminClientConfigCustomizer の configure メソッドは、管理クライアントプロパティへのアクセスを提供し、それを使用してさらにカスタマイズを定義できます。バインダーの Kafka トピックプロビジョナーは、このカスタマイザーを通じて指定されたプロパティに最高の優先順位を与えます。このカスタマイザ Bean を提供する例を次に示します。
@Bean
public AdminClientConfigCustomizer adminClientConfigCustomizer() {
return props -> {
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SASL_SSL");
};
}1.12. カスタム Kafka バインダーヘルスインジケーター
Spring Boot アクチュエーターがクラスパス上にある場合、Kafka バインダーはデフォルトのヘルスインジケーターをアクティブにします。このヘルスインジケーターは、バインダーのヘルスと Kafka ブローカーとの通信の課題をチェックします。アプリケーションがこのデフォルトのヘルスチェック実装を無効にし、カスタム実装を含めたい場合は、KafkaBinderHealth インターフェースの実装を提供できます。KafkaBinderHealth は、HealthIndicator から拡張されたマーカーインターフェースです。カスタム実装では、health() メソッドの実装を提供する必要があります。カスタム実装は、Bean としてアプリケーション構成に存在する必要があります。バインダーがカスタム実装を検出すると、デフォルトの実装の代わりにそれを使用します。これは、アプリケーションでのそのようなカスタム実装 Bean の例です。
@Bean
public KafkaBinderHealth kafkaBinderHealthIndicator() {
return new KafkaBinderHealth() {
@Override
public Health health() {
// custom implementation details.
}
};
}1.13. デッドレタートピック処理
1.13.1. デッドレタートピックパーティションの選択
デフォルトでは、レコードは元のレコードと同じパーティションを使用して Dead-Letter トピックに公開されます。つまり、Dead-Letter トピックには、少なくとも元のレコードと同じ数のパーティションが必要です。
この動作を変更するには、DlqPartitionFunction 実装を @Bean としてアプリケーションコンテキストに追加します。そのような Bean は 1 つだけ存在できます。この機能は、コンシューマーグループ、障害が発生した ConsumerRecord、例外とともに提供されます。例: 常にパーティション 0 にルーティングする場合は、次を使用できます。
@Bean
public DlqPartitionFunction partitionFunction() {
return (group, record, ex) -> 0;
} コンシューマーバインディングの dlqPartitions プロパティを 1 に設定する(そして、バインダーの minPartitionCount が 1 に等しい)場合、DlqPartitionFunction を供給する必要はありません。フレームワークは常にパーティション 0 を使用します。コンシューマーバインディングの dlqPartitions プロパティを 1 よりも大きい値に設定した場合(または、バインダーの minPartitionCount が 1 よりも大きい場合)、パーティション数が元のトピックのものと同じであっても、DlqPartitionFunction Bean を必ず提供しなければなりません。 |
DLQ トピックのカスタム名を定義することもできます。これを行うには、アプリケーションコンテキストへの @Bean として DlqDestinationResolver の実装を作成します。バインダーがそのような Bean を検出すると、それが優先されます。それ以外の場合は、dlqName プロパティが使用されます。これらのどちらも見つからない場合は、デフォルトで error.<destination>.<group> になります。@Bean としての DlqDestinationResolver の例を次に示します。
@Bean
public DlqDestinationResolver dlqDestinationResolver() {
return (rec, ex) -> {
if (rec.topic().equals("word1")) {
return "topic1-dlq";
}
else {
return "topic2-dlq";
}
};
}DlqDestinationResolver の実装を提供する際に留意すべき重要なことの 1 つは、バインダーのプロビジョナーがアプリケーションのトピックを自動作成しないことです。これは、実装が送信する可能性のあるすべての DLQ トピックの名前をバインダーが推測する方法がないためです。この戦略を使用して DLQ 名を提供する場合、それらのトピックが事前に作成されていることを確認するのはアプリケーションの責任です。
1.13.2. デッドレタートピックでのレコードの処理
フレームワークは、ユーザーがデッドレターメッセージをどのように処理するかを予測できないため、メッセージを処理するための標準的なメカニズムを提供していません。デッドレタリングの理由が一時的なものである場合は、メッセージを元のトピックにルーティングして戻すことをお勧めします。ただし、課題が永続的な課題である場合は、無限ループが発生する可能性があります。このトピック内のサンプル Spring Boot アプリケーションは、これらのメッセージを元のトピックにルーティングする方法の例ですが、3 回試行すると、メッセージは「駐車場」トピックに移動します。このアプリケーションは、デッドレターのトピックから読み取る別の spring-cloud-stream アプリケーションです。5 秒間メッセージが受信されないと終了します。
例では、元の宛先が so8400out であり、コンシューマーグループが so8400 であると想定しています。
考慮すべき戦略がいくつかあります。
メインアプリケーションが実行されていないときにのみ再ルーティングを実行することを検討してください。そうしないと、一時的なエラーの再試行がすぐに使い果たされてしまいます。
または、2 段階のアプローチを使用します。このアプリケーションを使用して 3 番目のトピックにルーティングし、別のアプリケーションを使用してそこからメイントピックにルーティングします。
次のコードリストは、サンプルアプリケーションを示しています。
spring.cloud.stream.bindings.input.group=so8400replay
spring.cloud.stream.bindings.input.destination=error.so8400out.so8400
spring.cloud.stream.bindings.output.destination=so8400out
spring.cloud.stream.bindings.parkingLot.destination=so8400in.parkingLot
spring.cloud.stream.kafka.binder.configuration.auto.offset.reset=earliest
spring.cloud.stream.kafka.binder.headers=x-retries@SpringBootApplication
@EnableBinding(TwoOutputProcessor.class)
public class ReRouteDlqKApplication implements CommandLineRunner {
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) {
SpringApplication.run(ReRouteDlqKApplication.class, args).close();
}
private final AtomicInteger processed = new AtomicInteger();
@Autowired
private MessageChannel parkingLot;
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public Message<?> reRoute(Message<?> failed) {
processed.incrementAndGet();
Integer retries = failed.getHeaders().get(X_RETRIES_HEADER, Integer.class);
if (retries == null) {
System.out.println("First retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else if (retries.intValue() < 3) {
System.out.println("Another retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(retries.intValue() + 1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else {
System.out.println("Retries exhausted for " + failed);
parkingLot.send(MessageBuilder.fromMessage(failed)
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build());
}
return null;
}
@Override
public void run(String... args) throws Exception {
while (true) {
int count = this.processed.get();
Thread.sleep(5000);
if (count == this.processed.get()) {
System.out.println("Idle, exiting");
return;
}
}
}
public interface TwoOutputProcessor extends Processor {
@Output("parkingLot")
MessageChannel parkingLot();
}
}1.14. Kafka バインダーによるパーティショニング
Apache Kafka はトピックのパーティション分割をネイティブにサポートします。
たとえば、メッセージ処理を厳密に並べ替える場合など、特定のパーティションにデータを送信すると有利な場合があります(特定の顧客宛てのすべてのメッセージは同じパーティションに送信する必要があります)。
次の例は、プロデューサー側とコンシューマー側を構成する方法を示しています。
@SpringBootApplication
@EnableBinding(Source.class)
public class KafkaPartitionProducerApplication {
private static final Random RANDOM = new Random(System.currentTimeMillis());
private static final String[] data = new String[] {
"foo1", "bar1", "qux1",
"foo2", "bar2", "qux2",
"foo3", "bar3", "qux3",
"foo4", "bar4", "qux4",
};
public static void main(String[] args) {
new SpringApplicationBuilder(KafkaPartitionProducerApplication.class)
.web(false)
.run(args);
}
@InboundChannelAdapter(channel = Source.OUTPUT, poller = @Poller(fixedRate = "5000"))
public Message<?> generate() {
String value = data[RANDOM.nextInt(data.length)];
System.out.println("Sending: " + value);
return MessageBuilder.withPayload(value)
.setHeader("partitionKey", value)
.build();
}
}spring:
cloud:
stream:
bindings:
output:
destination: partitioned.topic
producer:
partition-key-expression: headers['partitionKey']
partition-count: 12 トピックは、すべてのコンシューマーグループに必要な同時実行性を実現するのに十分なパーティションを持つようにプロビジョニングする必要があります。上記の構成は、最大 12 のコンシューマーインスタンスをサポートします(concurrency が 2, 4 の場合は 6、同時実行性が 3 の場合など)。一般に、将来のコンシューマーまたは同時実行性の増加を考慮して、パーティションを「オーバープロビジョニング」するのが最善です。 |
上記の構成では、デフォルトのパーティショニング(key.hashCode() % partitionCount)を使用しています。これは、キー値に応じて、適切にバランスの取れたアルゴリズムを提供する場合と提供しない場合があります。partitionSelectorExpression または partitionSelectorClass プロパティを使用して、このデフォルトをオーバーライドできます。 |
パーティションは Kafka によってネイティブに処理されるため、コンシューマー側で特別な構成は必要ありません。Kafka は、インスタンス全体にパーティションを割り当てます。
次の Spring Boot アプリケーションは、Kafka ストリームをリッスンし、各メッセージの送信先のパーティション ID を(コンソールに)出力します。
@SpringBootApplication
@EnableBinding(Sink.class)
public class KafkaPartitionConsumerApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(KafkaPartitionConsumerApplication.class)
.web(false)
.run(args);
}
@StreamListener(Sink.INPUT)
public void listen(@Payload String in, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
System.out.println(in + " received from partition " + partition);
}
}spring:
cloud:
stream:
bindings:
input:
destination: partitioned.topic
group: myGroup 必要に応じてインスタンスを追加できます。Kafka は、パーティション割り当てのバランスを取り直します。インスタンス数(または instance count * concurrency)がパーティションの数を超えると、一部のコンシューマーはアイドル状態になります。
2. Kafka ストリームバインダー
2.1. 使用方法
Kafka Streams バインダーを使用するには、次の maven 座標を使用して、Spring Cloud Stream アプリケーションにバインダーを追加する必要があります。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka-streams</artifactId>
</dependency>Kafka Streams バインダーの新しいプロジェクトをブートストラップする簡単な方法は、Spring Initializr を使用してから、以下に示すように CloudStreams と Spring for KafkaStreams を選択することです。

2.2. 概要
Spring Cloud Stream には、Apache Kafka ストリーム (英語) バインディング用に明示的に設計されたバインダー実装が含まれています。このネイティブ統合により、Spring Cloud Stream「プロセッサー」アプリケーションはコアビジネスロジックで Apache Kafka ストリーム (英語) API を直接使用できます。
Kafka Streams バインダーの実装は、Spring for Apache Kafka プロジェクトによって提供される基盤上に構築されています。
Kafka Streams バインダーは、Kafka Streams の 3 つの主要な型である KStream、KTable、GlobalKTable のバインディング機能を提供します。
Kafka Streams アプリケーションは通常、レコードが受信トピックから読み取られ、ビジネスロジックを適用してから、変換されたレコードを送信トピックに書き込むモデルに従います。または、送信先のないプロセッサーアプリケーションを定義することもできます。
次のセクションでは、Spring Cloud Stream と Kafka ストリームの統合の詳細を見ていきます。
2.3. プログラミングモデル
Kafka Streams バインダーによって提供されるプログラミングモデルを使用する場合、高レベルの DSL をストリーミング (英語) と、高レベルと低レベルの両方のプロセッサー -API (英語) の組み合わせの両方をオプションとして使用できます。高レベルと低レベルの両方の API を混在させる場合、これは通常、KStream で transform または process API メソッドを呼び出すことによって実現されます。
2.3.1. 関数スタイル
Spring Cloud Stream 3.0.0 以降、Kafka Streams バインダーを使用すると、Java 8 で使用可能な関数型プログラミングスタイルを使用してアプリケーションを設計および開発できます。これは、アプリケーションを java.util.function.Function 型または java.util.function.Consumer 型のラムダ式として簡潔に表すことができることを意味します。
非常に基本的な例を見てみましょう。
@SpringBootApplication
public class SimpleConsumerApplication {
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
return input ->
input.foreach((key, value) -> {
System.out.println("Key: " + key + " Value: " + value);
});
}
} シンプルではありますが、これは完全なスタンドアロン Spring Boot アプリケーションであり、ストリーム処理に Kafka ストリームを活用しています。これは、送信バインディングがなく、受信バインディングが 1 つしかないコンシューマーアプリケーションです。アプリケーションはデータを消費し、KStream キーと値からの情報を標準出力に記録するだけです。アプリケーションには、SpringBootApplication アノテーションと Bean としてマークされたメソッドが含まれています。Bean メソッドは、KStream でパラメーター化された型 java.util.function.Consumer です。次に、実装では、本質的にラムダ式であるコンシューマーオブジェクトを返します。ラムダ式の中には、データを処理するためのコードが含まれています。
このアプリケーションでは、型 KStream の単一の入力バインディングがあります。バインダーは、process-in-0 という名前でアプリケーションのこのバインディングを作成します。つまり、関数 Bean 名の後にダッシュ文字(-)が続き、リテラル in の後に別のダッシュが続き、パラメーターの順序位置が続きます。このバインディング名を使用して、宛先などの他のプロパティを設定します。例: spring.cloud.stream.bindings.process-in-0.destination=my-topic。
| 宛先プロパティがバインディングに設定されていない場合(アプリケーションに十分な権限がある場合)、トピックはバインディングと同じ名前で作成されるか、そのトピックはすでに使用可能であると予想されます。 |
uber-jar(kstream-consumer-app.jar など)としてビルドしたら、次のように上記の例を実行できます。
アプリケーションが Spring の Component アノテーションを使用して機能 Bean を定義することを選択した場合、バインダーはそのモデルもサポートします。上記の関数 Bean は以下のように書き直すことができます。
@Component(name = "process")
public class SimpleConsumer implements java.util.function.Consumer<KStream<Object, String>> {
@Override
public void accept(KStream<Object, String> input) {
input.foreach((key, value) -> {
System.out.println("Key: " + key + " Value: " + value);
});
}
}java -jar kstream-consumer-app.jar --spring.cloud.stream.bindings.process-in-0.destination=my-topicこれは別の例で、入力バインディングと出力バインディングの両方を備えたフルプロセッサーです。これは、アプリケーションがトピックからデータを受信し、各単語の出現回数がタンブリングタイムウィンドウで計算される典型的な単語カウントの例です。
@SpringBootApplication
public class WordCountProcessorApplication {
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> process() {
return input -> input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.map((key, value) -> new KeyValue<>(value, value))
.groupByKey(Serialized.with(Serdes.String(), Serdes.String()))
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("word-counts-state-store"))
.toStream()
.map((key, value) -> new KeyValue<>(key.key(), new WordCount(key.key(), value,
new Date(key.window().start()), new Date(key.window().end()))));
}
public static void main(String[] args) {
SpringApplication.run(WordCountProcessorApplication.class, args);
}
} ここでも、これは完全な Spring Boot アプリケーションです。ここでの最初のアプリケーションとの違いは、Bean メソッドの型が java.util.function.Function であるということです。Function の最初のパラメーター化された型は入力 KStream 用で、2 番目の型は出力用です。メソッド本体には、Function 型のラムダ式が提供され、実装として実際のビジネスロジックが提供されます。前述のコンシューマーベースのアプリケーションと同様に、ここでの入力バインディングは、デフォルトで process-in-0 という名前が付けられています。出力の場合、バインディング名も自動的に process-out-0 に設定されます。
uber-jar(wordcount-processor.jar など)としてビルドしたら、次のように上記の例を実行できます。
java -jar wordcount-processor.jar --spring.cloud.stream.bindings.process-in-0.destination=words --spring.cloud.stream.bindings.process-out-0.destination=counts このアプリケーションは、Kafka トピック words からのメッセージを消費し、計算結果は出力トピック counts に公開されます。
Spring Cloud Stream は、受信トピックと発信トピックの両方からのメッセージが KStream オブジェクトとして自動的にバインドされることを保証します。開発者は、コードのビジネス面、つまりプロセッサーに必要なロジックの記述に専念できます。Kafka Streams インフラストラクチャに必要な Kafka Streams 固有の構成のセットアップは、フレームワークによって自動的に処理されます。
上で見た 2 つの例には、単一の KStream 入力バインディングがあります。どちらの場合も、バインディングは単一のトピックからレコードを受け取りました。複数のトピックを単一の KStream バインディングに多重化する場合は、以下の宛先としてコンマ区切りの Kafka トピックを指定できます。
spring.cloud.stream.bindings.process-in-0.destination=topic-1,topic-2,topic-3
さらに、トピックを通常の表現と照合する場合は、トピックパターンを宛先として提供することもできます。
spring.cloud.stream.bindings.process-in-0.destination=input.*
複数の入力バインディング
多くの重要な Kafka Streams アプリケーションは、複数のバインディングを介して複数のトピックからのデータを消費することがよくあります。たとえば、1 つのトピックは Kstream として消費され、別のトピックは KTable または GlobalKTable として消費されます。アプリケーションがデータをテーブル型として受け取りたいと思う理由はたくさんあります。基になるトピックがデータベースからの変更データキャプチャー(CDC)メカニズムを介して入力される、またはアプリケーションがダウンストリーム処理の最新の更新のみを気にするユースケースを考えてみてください。データを KTable または GlobalKTable としてバインドする必要があるとアプリケーションが指定した場合、Kafka Streams バインダーは、宛先を KTable または GlobalKTable に適切にバインドし、アプリケーションが操作できるようにします。Kafka Streams バインダーで複数の入力バインディングがどのように処理されるかについていくつかの異なるシナリオを見ていきます。
Kafka ストリームバインダーの BiFunction
これは、2 つの入力と 1 つの出力がある例です。この場合、アプリケーションは java.util.function.BiFunction を活用できます。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
return (userClicksStream, userRegionsTable) -> (userClicksStream
.leftJoin(userRegionsTable, (clicks, region) -> new RegionWithClicks(region == null ?
"UNKNOWN" : region, clicks),
Joined.with(Serdes.String(), Serdes.Long(), null))
.map((user, regionWithClicks) -> new KeyValue<>(regionWithClicks.getRegion(),
regionWithClicks.getClicks()))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
.reduce(Long::sum)
.toStream());
} ここでも、基本的なテーマは前の例と同じですが、ここでは 2 つの入力があります。Java の BiFunction サポートは、入力を目的の宛先にバインドするために使用されます。入力用にバインダーによって生成されるデフォルトのバインディング名は、それぞれ process-in-0 と process-in-1 です。デフォルトの出力バインディングは process-out-0 です。この例では、BiFunction の最初のパラメーターは最初の入力の KStream としてバインドされ、2 番目のパラメーターは 2 番目の入力の KTable としてバインドされます。
Kafka ストリームバインダーの BiConsumer
入力が 2 つあるが出力がない場合は、以下に示すように java.util.function.BiConsumer を使用できます。
@Bean
public BiConsumer<KStream<String, Long>, KTable<String, String>> process() {
return (userClicksStream, userRegionsTable) -> {}
}2 つの入力を超えて
3 つ以上の入力がある場合はどうなるでしょうか? 3 つ以上の入力が必要な場合があります。その場合、バインダーを使用すると、チェーンの部分関数を実行できます。関数型プログラミングの専門用語では、この手法は一般にカリー化として知られています。Java 8 の一部として関数型プログラミングのサポートが追加されたことで、Java でカレー関数を記述できるようになりました。Spring Cloud Stream Kafka Streams バインダーは、この機能を利用して、複数の入力バインディングを有効にすることができます。
例を見てみましょう。
@Bean
public Function<KStream<Long, Order>,
Function<GlobalKTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, EnrichedOrder>>>> enrichOrder() {
return orders -> (
customers -> (
products -> (
orders.join(customers,
(orderId, order) -> order.getCustomerId(),
(order, customer) -> new CustomerOrder(customer, order))
.join(products,
(orderId, customerOrder) -> customerOrder
.productId(),
(customerOrder, product) -> {
EnrichedOrder enrichedOrder = new EnrichedOrder();
enrichedOrder.setProduct(product);
enrichedOrder.setCustomer(customerOrder.customer);
enrichedOrder.setOrder(customerOrder.order);
return enrichedOrder;
})
)
)
);
} 上記のバインディングモデルの詳細を見てみましょう。このモデルでは、受信に 3 つの部分的に適用された関数があります。f(x)、f(y)、f(z) と呼びましょう。これらの関数を真の数学関数の意味で拡張すると、f(x) → (fy) → f(z) → KStream<Long, EnrichedOrder> のようになります。x 変数は KStream<Long, Order> を表し、y 変数は GlobalKTable<Long, Customer> を表し、z 変数は GlobalKTable<Long, Product> を表します。最初の関数 f(x) には、アプリケーションの最初の入力バインディング(KStream<Long, Order>)があり、その出力は関数 f(y)です。関数 f(y) には、アプリケーションの 2 番目の入力バインディング(GlobalKTable<Long, Customer>)があり、その出力はさらに別の関数 f(z) です。関数 f(z) の入力は、アプリケーションの 3 番目の入力(GlobalKTable<Long, Product>)であり、その出力は、アプリケーションの最終出力バインディングである KStream<Long, EnrichedOrder> です。それぞれ KStream、GlobalKTable、GlobalKTable である 3 つの部分関数からの入力は、ラムダ式の一部としてビジネスロジックを実装するためのメソッド本体で利用できます。
入力バインディングには、それぞれ enrichOrder-in-0、enrichOrder-in-1、enrichOrder-in-2 という名前が付けられています。出力バインディングの名前は enrichOrder-out-0 です。
カレー関数を使用すると、事実上任意の数の入力を持つことができます。ただし、Java で上記のように入力の数が少なく、それらに部分的に適用された関数を超えると、コードが読み取れなくなる可能性があることに注意してください。Kafka Streams アプリケーションが必要とする入力バインディングの数が適度に少なく、この機能モデルを使用する場合は、設計を再考し、アプリケーションを適切に分解することをお勧めします。
出力バインディング
Kafka Streams バインダーは、出力バインディングとして KStream または KTable のいずれかの型を許可します。バックグラウンドでは、バインダーは KStream で to メソッドを使用して、結果のレコードを出力トピックに送信します。アプリケーションが関数の出力として KTable を提供する場合でも、バインダーは KStream の to メソッドに委譲することにより、この手法を使用します。
たとえば、以下の両方の機能が機能します。
@Bean
public Function<KStream<String, String>, KTable<String, String>> foo() {
return KStream::toTable;
};
}
@Bean
public Function<KTable<String, String>, KStream<String, String>> bar() {
return KTable::toStream;
}複数の出力バインディング
Kafka Streams を使用すると、送信データを複数のトピックに書き込むことができます。この機能は、Kafka ストリームでは分岐として知られています。複数の出力バインディングを使用する場合は、送信戻り値の型として KStream の配列(KStream[])を指定する必要があります。
次に例を示します。
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>[]> process() {
Predicate<Object, WordCount> isEnglish = (k, v) -> v.word.equals("english");
Predicate<Object, WordCount> isFrench = (k, v) -> v.word.equals("french");
Predicate<Object, WordCount> isSpanish = (k, v) -> v.word.equals("spanish");
return input -> {
final Map<String, KStream<Object, WordCount>> stringKStreamMap = input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(TimeWindows.of(Duration.ofSeconds(5)))
.count(Materialized.as("WordCounts-branch"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value,
new Date(key.window().start()), new Date(key.window().end()))))
.split()
.branch(isEnglish)
.branch(isFrench)
.branch(isSpanish)
.noDefaultBranch();
return stringKStreamMap.values().toArray(new KStream[0]);
};
} プログラミングモデルは同じままですが、送信のパラメーター化された型は KStream[] です。上記の関数のデフォルトの出力バインディング名は、それぞれ process-out-0、process-out-1、process-out-2 です。バインダーが 3 つの出力バインディングを生成する理由は、返された KStream 配列の長さを 3 として検出するためです。この例では、noDefaultBranch() を提供していることに注意してください。代わりに defaultBranch() を使用した場合、追加の出力バインディングが必要になり、基本的に長さ 4 の KStream 配列が返されます。
Kafka ストリームの関数ベースのプログラミングスタイルの概要
要約すると、次の表は、機能パラダイムで使用できるさまざまなオプションを示しています。
| 入力数 | 出力数 | 使用するコンポーネント |
|---|---|---|
1 | 0 | java.util.function.Consumer |
2 | 0 | java.util.function.BiConsumer |
1 | 1..n | java.util.function.Function |
2 | 1..n | java.util.function.BiFunction |
> = 3 | 0..n | カレー関数を使用する |
この表に複数の出力がある場合、型は単に
KStream[]になります。
Kafka Streams バインダーの関数合成
Kafka Streams バインダーは、線形トポロジーの最小限の形式の機能合成をサポートします。Java 関数型 API サポートを使用すると、複数の関数を記述し、andThen メソッドを使用して独自に作成できます。例: 次の 2 つの関数があると仮定します。
@Bean
public Function<KStream<String, String>, KStream<String, String>> foo() {
return input -> input.peek((s, s2) -> {});
}
@Bean
public Function<KStream<String, String>, KStream<String, Long>> bar() {
return input -> input.peek((s, s2) -> {});
}バインダーに機能合成のサポートがなくても、次のようにこれら 2 つの機能を合成できます。
@Bean
pubic Funcion<KStream<String, String>, KStream<String, Long>> composed() {
foo().andThen(bar());
} 次に、spring.cloud.stream.function.definition=foo;bar;composed の形式の定義を提供できます。バインダーでの関数合成のサポートにより、明示的な関数合成を行うこの 3 番目の関数を記述する必要はありません。
代わりにこれを行うことができます:
spring.cloud.stream.function.definition=foo|barあなたもこれを行うことができます:
spring.cloud.stream.function.definition=foo|bar;foo;bar この例の合成関数のデフォルトのバインディング名は、foobar-in-0 と foobar-out-0 になります。
Kafka ストリームビンサーの機能構成の制限
java.util.function.Function Bean をお持ちの場合は、別の機能または複数の機能で構成できます。同じ機能 Bean を java.util.function.Consumer で構成することもできます。この場合、コンシューマーが最後に構成されたコンポーネントです。関数は複数の関数で構成でき、java.util.function.Consumer Bean で終了することもできます。
型 java.util.function.BiFunction の Bean を構成する場合、BiFunction は定義の最初の関数である必要があります。構成されたエンティティは、型 java.util.function.Function または java.util.funciton.Consumer のいずれかである必要があります。つまり、BiFunction Bean を取得してから、別の BiFunction で構成することはできません。
BiConsumer の型または Consumer が最初のコンポーネントである定義で構成することはできません。これが定義の最後のコンポーネントでない限り、出力が配列(分岐の場合は KStream[])である関数で構成することもできません。
関数定義の BiFunction の最初の Function も、カレー形式を使用する場合があります。例: 以下が可能です。
@Bean
public Function<KStream<String, String>, Function<KTable<String, String>, KStream<String, String>>> curriedFoo() {
return a -> b ->
a.join(b, (value1, value2) -> value1 + value2);
}
@Bean
public Function<KStream<String, String>, KStream<String, String>> bar() {
return input -> input.mapValues(value -> value + "From-anotherFooFunc");
} 関数定義は curriedFoo|bar である可能性があります。バックグラウンドでは、バインダーはカリー化された関数の 2 つの入力バインディングと、定義の最後の関数に基づいた出力バインディングを作成します。この場合のデフォルトの入力バインディングは、curriedFoobar-in-0 と curriedFoobar-in-1 になります。この例のデフォルトの出力バインディングは curriedFoobar-out-0 になります。
関数合成の出力として KTable を使用する際の特記事項
次の 2 つの機能があるとしましょう。
@Bean
public Function<KStream<String, String>, KTable<String, String>> foo() {
return KStream::toTable;
};
}
@Bean
public Function<KTable<String, String>, KStream<String, String>> bar() {
return KTable::toStream;
} それらを foo|bar として構成できますが、最初の関数(foo)は出力として KTable を持っているため、2 番目の関数(この場合は bar)は入力として KTable を持っている必要があることに注意してください。
2.3.2. 命令型プログラミングモデル。
バインダーの 3.1.0 バージョンから始めて、Kafka Streams バインダーベースのアプリケーションには上記の関数型プログラミングモデルを使用することをお勧めします。StreamListener のサポートは、Spring Cloud Stream の 3.1.0 以降で非推奨になりました。以下に、参照として StreamListener ベースの Kafka ストリームプロセッサーの詳細を示します。
以下は、StreamListener を使用したワードカウントの例に相当します。
@SpringBootApplication
@EnableBinding(KafkaStreamsProcessor.class)
public class WordCountProcessorApplication {
@StreamListener("input")
@SendTo("output")
public KStream<?, WordCount> process(KStream<?, String> input) {
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("WordCounts-multi"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))));
}
public static void main(String[] args) {
SpringApplication.run(WordCountProcessorApplication.class, args);
} ご覧のとおり、完全なアプリケーションにするには、EnableBinding と、StreamListener や SendTo などの他の追加のアノテーションを提供する必要があるため、これはもう少し冗長です。EnableBinding は、バインディングを含むバインディングインターフェースを指定する場所です。この場合、次の契約を持つストック KafkaStreamsProcessor バインディングインターフェースを使用しています。
public interface KafkaStreamsProcessor {
@Input("input")
KStream<?, ?> input();
@Output("output")
KStream<?, ?> output();
} これらの宣言を含むバインディングインターフェースを使用しているため、バインダーは入力 KStream と出力 KStream のバインディングを作成します。
機能スタイルで提供されるプログラミングモデルの明らかな違いに加えて、ここでメンションする必要がある 1 つの特定のことは、バインディング名がバインディングインターフェースで指定するものであるということです。例: 上記のアプリケーションでは、KafkaStreamsProcessor を使用しているため、バインディング名は input と output です。バインディングプロパティはそれらの名前を使用する必要があります。たとえば、spring.cloud.stream.bindings.input.destination、spring.cloud.stream.bindings.output.destination などです。バインダーがアプリケーションのバインディング名を生成するため、これは機能スタイルとは根本的に異なることに注意してください。これは、アプリケーションが EnableBinding を使用する機能モデルにバインディングインターフェースを提供しないためです。
これは、2 つの入力があるシンクの別の例です。
@EnableBinding(KStreamKTableBinding.class)
.....
.....
@StreamListener
public void process(@Input("inputStream") KStream<String, PlayEvent> playEvents,
@Input("inputTable") KTable<Long, Song> songTable) {
....
....
}
interface KStreamKTableBinding {
@Input("inputStream")
KStream<?, ?> inputStream();
@Input("inputTable")
KTable<?, ?> inputTable();
} 以下は、上記で見たのと同じ BiFunction ベースのプロセッサーと同等の StreamListener です。
@EnableBinding(KStreamKTableBinding.class)
....
....
@StreamListener
@SendTo("output")
public KStream<String, Long> process(@Input("input") KStream<String, Long> userClicksStream,
@Input("inputTable") KTable<String, String> userRegionsTable) {
....
....
}
interface KStreamKTableBinding extends KafkaStreamsProcessor {
@Input("inputX")
KTable<?, ?> inputTable();
} 最後に、3 つの入力とカレー関数を備えたアプリケーションに相当する StreamListener を次に示します。
@EnableBinding(CustomGlobalKTableProcessor.class)
...
...
@StreamListener
@SendTo("output")
public KStream<Long, EnrichedOrder> process(
@Input("input-1") KStream<Long, Order> ordersStream,
@Input("input-2") GlobalKTable<Long, Customer> customers,
@Input("input-3") GlobalKTable<Long, Product> products) {
KStream<Long, CustomerOrder> customerOrdersStream = ordersStream.join(
customers, (orderId, order) -> order.getCustomerId(),
(order, customer) -> new CustomerOrder(customer, order));
return customerOrdersStream.join(products,
(orderId, customerOrder) -> customerOrder.productId(),
(customerOrder, product) -> {
EnrichedOrder enrichedOrder = new EnrichedOrder();
enrichedOrder.setProduct(product);
enrichedOrder.setCustomer(customerOrder.customer);
enrichedOrder.setOrder(customerOrder.order);
return enrichedOrder;
});
}
interface CustomGlobalKTableProcessor {
@Input("input-1")
KStream<?, ?> input1();
@Input("input-2")
GlobalKTable<?, ?> input2();
@Input("input-3")
GlobalKTable<?, ?> input3();
@Output("output")
KStream<?, ?> output();
}EnableBinding を提供するだけでなく、独自のカスタムバインディングインターフェースも作成する必要があるため、上記の 2 つの例はさらに冗長であることに気付くかもしれません。機能モデルを使用すると、これらすべての儀式の詳細を回避できます。
Kafka Streams バインダーによって提供される一般的なプログラミングモデルの検討に移る前に、複数の出力バインディングの StreamListener バージョンを示します。
EnableBinding(KStreamProcessorWithBranches.class)
public static class WordCountProcessorApplication {
@Autowired
private TimeWindows timeWindows;
@StreamListener("input")
@SendTo({"output1","output2","output3"})
public KStream<?, WordCount>[] process(KStream<Object, String> input) {
Predicate<Object, WordCount> isEnglish = (k, v) -> v.word.equals("english");
Predicate<Object, WordCount> isFrench = (k, v) -> v.word.equals("french");
Predicate<Object, WordCount> isSpanish = (k, v) -> v.word.equals("spanish");
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(timeWindows)
.count(Materialized.as("WordCounts-1"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))))
.branch(isEnglish, isFrench, isSpanish);
}
interface KStreamProcessorWithBranches {
@Input("input")
KStream<?, ?> input();
@Output("output1")
KStream<?, ?> output1();
@Output("output2")
KStream<?, ?> output2();
@Output("output3")
KStream<?, ?> output3();
}
}要約すると、Kafka Streams バインダーを使用する際のさまざまなプログラミングモデルの選択を確認しました。
バインダーは、入力で KStream、KTable、GlobalKTable のバインディング機能を提供します。KTable および GlobalKTable バインディングは、入力でのみ使用できます。バインダーは、KStream の入力バインディングと出力バインディングの両方をサポートします。
Kafka Streams バインダーのプログラミングモデルの結果は、バインダーが完全に機能するプログラミングモデルを使用するか、StreamListener ベースの命令型アプローチを使用する柔軟性を提供することです。
2.4. プログラミングモデルの付属品
2.4.1. 単一のアプリケーション内の複数の Kafka ストリームプロセッサー
バインダーを使用すると、単一の Spring Cloud Stream アプリケーション内に複数の Kafka ストリームプロセッサーを含めることができます。以下のような申し込みが可能です。
@Bean
public java.util.function.Function<KStream<Object, String>, KStream<Object, String>> process() {
...
}
@Bean
public java.util.function.Consumer<KStream<Object, String>> anotherProcess() {
...
}
@Bean
public java.util.function.BiFunction<KStream<Object, String>, KTable<Integer, String>, KStream<Object, String>> yetAnotherProcess() {
...
}この場合、バインダーは、異なるアプリケーション ID を持つ 3 つの個別の Kafka Streams オブジェクトを作成します(これについては以下で詳しく説明します)。ただし、アプリケーションに複数のプロセッサーがある場合は、どの機能をアクティブにする必要があるかを Spring Cloud Stream に通知する必要があります。機能を有効にする方法は次のとおりです。
spring.cloud.stream.function.definition: process;anotherProcess;yetAnotherProcess
特定の機能をすぐにアクティブにしたくない場合は、このリストから削除できます。
これは、同じアプリケーションに単一の Kafka Streams プロセッサーと他の型の Function Bean があり、異なるバインダーを介して処理される場合にも当てはまります。(たとえば、通常の Kafka メッセージチャネルバインダーに基づく関数 Bean)
2.4.2. Kafka ストリームアプリケーション ID
アプリケーション ID は、Kafka Streams アプリケーションに提供する必要のある必須のプロパティです。Spring Cloud Stream Kafka Streams バインダーを使用すると、このアプリケーション ID を複数の方法で構成できます。
アプリケーションにシングルプロセッサーまたは StreamListener が 1 つしかない場合は、次のプロパティを使用して、これをバインダーレベルで設定できます。
spring.cloud.stream.kafka.streams.binder.applicationId.
便宜上、プロセッサーが 1 つしかない場合は、プロパティとして spring.application.name を使用してアプリケーション ID を委譲することもできます。
アプリケーションに複数の Kafka Streams プロセッサーがある場合は、プロセッサーごとにアプリケーション ID を設定する必要があります。機能モデルの場合は、プロパティとして各関数に接続できます。
たとえば次の機能があると想像してください。
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
...
}および
@Bean
public java.util.function.Consumer<KStream<Object, String>> anotherProcess() {
...
}次に、次のバインダーレベルのプロパティを使用して、それぞれのアプリケーション ID を設定できます。
spring.cloud.stream.kafka.streams.binder.functions.process.applicationId
および
spring.cloud.stream.kafka.streams.binder.functions.anotherProcess.applicationId
StreamListener の場合、プロセッサーの最初の入力バインディングでこれを設定する必要があります。
たとえば次の 2 つの StreamListener ベースのプロセッサーがあると想像してください。
@StreamListener
@SendTo("output")
public KStream<String, String> process(@Input("input") <KStream<Object, String>> input) {
...
}
@StreamListener
@SendTo("anotherOutput")
public KStream<String, String> anotherProcess(@Input("anotherInput") <KStream<Object, String>> input) {
...
}次に、次のバインディングプロパティを使用して、このアプリケーション ID を設定する必要があります。
spring.cloud.stream.kafka.streams.bindings.input.consumer.applicationId
および
spring.cloud.stream.kafka.streams.bindings.anotherInput.consumer.applicationId
関数ベースのモデルの場合も、アプリケーション ID をバインディングレベルで設定するこのアプローチは機能します。ただし、機能モデルを使用している場合は、上記のようにバインダーレベルで関数ごとに設定する方がはるかに簡単です。
本番デプロイの場合、構成を通じてアプリケーション ID を明示的に指定することを強くお勧めします。これは、アプリケーションを自動スケーリングする場合に特に重要になります。その場合、同じアプリケーション ID で各インスタンスをデプロイしていることを確認する必要があります。
アプリケーションがアプリケーション ID を提供しない場合、その場合、バインダーは静的アプリケーション ID を自動生成します。これは、アプリケーション ID を明示的に提供する必要がないため、開発シナリオで便利です。この方法で生成されたアプリケーション ID は、アプリケーションの再起動時に静的になります。機能モデルの場合、生成されるアプリケーション ID は、関数 Bean 名の後にリテラル applicationID が続きます。たとえば、関数 Bean 名の場合は process の場合は process-applicationID です。StreamListener の場合、関数 Bean 名を使用する代わりに、生成されたアプリケーション ID は、含まれているクラス名、メソッド名、リテラル applicationId を使用します。
アプリケーション ID 設定の概要
デフォルトでは、バインダーは関数または
StreamListenerメソッドごとにアプリケーション ID を自動生成します。単一のプロセッサーを使用している場合は、
spring.kafka.streams.applicationId、spring.application.name、spring.cloud.stream.kafka.streams.binder.applicationIdを使用できます。複数のプロセッサーがある場合は、プロパティ -
spring.cloud.stream.kafka.streams.binder.functions.<function-name>.applicationIdを使用して関数ごとにアプリケーション ID を設定できます。StreamListenerの場合、これは、入力バインディング名がinputであると仮定して、spring.cloud.stream.kafka.streams.bindings.input.applicationIdを使用して実行できます。
2.4.3. バインダーによって生成されたデフォルトのバインディング名を機能スタイルでオーバーライドする
デフォルトでは、バインダーは上記の戦略を使用して、機能スタイルを使用するときにバインディング名を生成します。つまり、<function-bean-name>-<in> | <out>-[0..n]、例: process-in-0、process-out-0 など。これらのバインディング名をオーバーライドする場合は、次のプロパティを指定することでそれを行うことができます。
spring.cloud.stream.function.bindings.<default binding name>。デフォルトのバインディング名は、バインダーによって生成された元のバインディング名です。
たとえばたとえば、この機能があります。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
} バインダーは、process-in-0、process-in-1、process-out-0 という名前のバインディングを生成します。完全に別のもの、おそらくさらにドメイン固有のバインディング名に変更したい場合は、以下のように行うことができます。
spring.cloud.stream.function.bindings.process-in-0=users
spring.cloud.stream.function.bindings.process-in-0=regions
および
spring.cloud.stream.function.bindings.process-out-0=clicks
その後、これらの新しいバインディング名にすべてのバインディングレベルプロパティを設定する必要があります。
上記の関数型プログラミングモデルでは、ほとんどの状況でデフォルトのバインディング名を順守することが理にかなっていることに注意してください。このオーバーライドを実行する必要がある唯一の理由は、構成プロパティの数が多く、バインディングをよりドメインに適したものにマップする場合です。
2.4.4. ブートストラップサーバー構成のセットアップ
Kafka Streams アプリケーションを実行するときは、Kafka ブローカーサーバー情報を提供する必要があります。この情報を提供しない場合、バインダーは、デフォルトの localhost:9092 でブローカーを実行していることを想定しています。そうでない場合は、それをオーバーライドする必要があります。これを行うにはいくつかの方法があります。
Boot プロパティの使用 -
spring.kafka.bootstrapServersバインダーレベルのプロパティ -
spring.cloud.stream.kafka.streams.binder.brokers
バインダーレベルのプロパティに関しては、通常の Kafka バインダーである spring.cloud.stream.kafka.binder.brokers を介して提供されるブローカープロパティを使用するかどうかは関係ありません。Kafka Streams バインダーは、最初に Kafka Streams バインダー固有のブローカープロパティが設定されているかどうかを確認し(spring.cloud.stream.kafka.streams.binder.brokers)、見つからない場合は spring.cloud.stream.kafka.binder.brokers を探します。
2.5. レコードの直列化と逆直列化
Kafka Streams バインダーを使用すると、2 つの方法でレコードを直列化および逆直列化できます。1 つは Kafka によって提供されるネイティブの直列化および逆直列化機能であり、もう 1 つは Spring Cloud Stream フレームワークのメッセージ変換機能です。詳細を見てみましょう。
2.5.1. 受信デシリアライズ
キーは常にネイティブ Serdes を使用して逆直列化されます。
値の場合、デフォルトでは、受信での逆直列化は Kafka によってネイティブに実行されます。これは、フレームワークによって逆直列化が行われた以前のバージョンの Kafka Streams バインダーからのデフォルトの動作に対する大きな変更であることに注意してください。
Kafka Streams バインダーは、java.util.function.Function|Consumer または StreamListener の型署名を調べて、一致する Serde 型を推測しようとします。Serdes に一致する順序は次のとおりです。
アプリケーションが型
Serdeの Bean を提供し、戻り値の型が受信キーまたは値型の実際の型でパラメーター化されている場合、アプリケーションはそのSerdeを受信逆直列化に使用します。たとえばアプリケーションに次のものがある場合、バインダーは、KStreamの入力値型がSerdeBean でパラメーター化された型と一致することを検出します。これは、受信の逆直列化に使用されます。
@Bean
public Serde<Foo> customSerde() {
...
}
@Bean
public Function<KStream<String, Foo>, KStream<String, Foo>> process() {
}次に、型を調べて、それらが Kafka ストリームによって公開されている型の 1 つであるかどうかを確認します。もしそうなら、使用してください。バインダーが Kafka ストリームから一致させようとする Serde 型は次のとおりです。
Integer, Long, Short, Double, Float, byte[], UUID and String.
Kafka ストリームによって提供される Serdes のいずれも型と一致しない場合、Spring Kafka によって提供される JsonSerde を使用します。この場合、バインダーは型が JSON フレンドリーであると想定します。これは、入力として複数の値オブジェクトがある場合に役立ちます。これは、バインダーが Java 型を修正するために内部的に推測するためです。ただし、
JsonSerdeにフォールバックする前に、バインダーはデフォルトのSerde`s set in the Kafka Streams configuration to see if it is a `Serdeで、受信 KStream の型と一致できるかどうかを確認します。
上記の戦略のいずれも機能しなかった場合、アプリケーションは構成を通じて `Serde` を提供する必要があります。これは、バインディングまたはデフォルトの 2 つの方法で構成できます。
最初に、バインダーは、Serde がバインディングレベルで提供されているかどうかを確認します。たとえば次のプロセッサーを使用している場合
@Bean
public BiFunction<KStream<CustomKey, AvroIn1>, KTable<CustomKey, AvroIn2>, KStream<CustomKey, AvroOutput>> process() {...} 次に、以下を使用してバインディングレベル Serde を提供できます。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde 入力バインディングごとに上記のように Serde を指定すると、優先順位が高くなり、バインダーは Serde 推論から遠ざかります。 |
デフォルトのキー / 値 Serdes を受信デシリアライズに使用する場合は、バインダーレベルで使用できます。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde
spring.cloud.stream.kafka.streams.binder.configuration.default.value.serdeKafka が提供するネイティブデコードが必要ない場合は、Spring Cloud Stream が提供するメッセージ変換機能を利用できます。ネイティブデコードがデフォルトであるため、Spring Cloud Stream で受信値オブジェクトを逆直列化するには、ネイティブデコードを明示的に無効にする必要があります。
たとえば上記と同じ BiFunction プロセッサーを使用している場合は、spring.cloud.stream.bindings.process-in-0.consumer.nativeDecoding: false すべての入力のネイティブデコードを個別に無効にする必要があります。それ以外の場合は、無効にしないものにはネイティブデコードが引き続き適用されます。
デフォルトでは、Spring Cloud Stream はコンテンツ型として application/json を使用し、適切な json メッセージコンバーターを使用します。次のプロパティと適切な MessageConverter Bean を使用して、カスタムメッセージコンバーターを使用できます。
spring.cloud.stream.bindings.process-in-0.contentType2.5.2. 送信直列化
送信直列化は、受信デ直列化の上記とほぼ同じルールに従います。受信の逆直列化と同様に、Spring Cloud Stream の以前のバージョンからの大きな変更の 1 つは、送信での直列化が Kafka によってネイティブに処理されることです。バインダーの 3.0 バージョンの前は、これはフレームワーク自体によって行われていました。
送信のキーは、バインダーによって推測される一致する Serde を使用して、Kafka によって常に直列化されます。キーの型を推測できない場合は、構成を使用して指定する必要があります。
値 serdes は、受信の逆直列化に使用されるのと同じルールを使用して推測されます。最初に、送信型がアプリケーションで提供された Bean からのものであるかどうかを確認するために一致します。そうでない場合は、- Integer、Long、Short、Double、Float、byte[]、UUID、String などの Kafka によって公開された Serde と一致するかどうかを確認します。それが機能しない場合は、Spring Kafka プロジェクトによって提供される JsonSerde にフォールバックしますが、最初にデフォルトの Serde 構成を調べて、一致するものがあるかどうかを確認します。これらはすべて、アプリケーションに対して透過的に行われることに注意してください。これらのいずれも機能しない場合、ユーザーは構成で使用する Serde を提供する必要があります。
上記と同じ BiFunction プロセッサーを使用しているとしましょう。次に、送信キー / 値 Serdes を次のように構成できます。
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerdeSerde 推論が失敗し、バインディングレベルの Serdes が提供されていない場合、バインダーは JsonSerde にフォールバックしますが、デフォルトの Serdes で一致するものを探します。
デフォルトの serdes は、デシリアライズで説明されている上記と同じ方法で構成されます。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde
アプリケーションが分岐機能を使用し、複数の出力バインディングがある場合、これらはバインディングごとに構成する必要があります。繰り返しになりますが、バインダーが Serde 型を推測できる場合は、この構成を行う必要はありません。
Kafka が提供するネイティブエンコーディングは必要ないが、フレームワークが提供するメッセージ変換を使用する場合は、ネイティブエンコーディングがデフォルトであるため、ネイティブエンコーディングを明示的に無効にする必要があります。たとえば上記と同じ BiFunction プロセッサーを使用している場合は、spring.cloud.stream.bindings.process-out-0.producer.nativeEncoding: false 分岐の場合は、すべての出力のネイティブエンコーディングを個別に無効にする必要があります。それ以外の場合は、無効にしないものにはネイティブエンコーディングが引き続き適用されます。
Spring Cloud Stream によって変換が行われる場合、デフォルトでは、コンテンツ型として application/json が使用され、適切な json メッセージコンバーターが使用されます。次のプロパティと対応する MessageConverter Bean を使用して、カスタムメッセージコンバーターを使用できます。
spring.cloud.stream.bindings.process-out-0.contentType ネイティブエンコーディング / デコーディングが無効になっている場合、バインダーはネイティブ Serdes の場合のように推論を行いません。アプリケーションは、すべての構成オプションを明示的に提供する必要があります。そのため、Spring Cloud Stream Kafka Streams アプリケーションを作成するときは、通常、逆直列化のデフォルトオプションを使用し、Kafka Streams が提供するネイティブの逆直列化を使用することをお勧めします。フレームワークによって提供されるメッセージ変換機能を使用する必要がある 1 つのシナリオは、アップストリームプロデューサーが特定の直列化戦略を使用している場合です。その場合、ネイティブメカニズムが失敗する可能性があるため、一致する逆直列化戦略を使用する必要があります。デフォルトの Serde メカニズムに依存する場合、アプリケーションは、バインダーが適切な Serde で受信と送信を正しくマップする方法を持っていることを確認する必要があります。そうしないと、問題が発生する可能性があります。
上で概説したデータの逆直列化アプローチは、プロセッサーのエッジ、つまり受信と送信にのみ適用可能であることに注意してください。ビジネスロジックでは、Serde オブジェクトを明示的に必要とする Kafka StreamsAPI を呼び出す必要がある場合があります。これらは依然としてアプリケーションの責任であり、開発者がそれに応じて処理する必要があります。
2.6. エラー処理
Apache Kafka Streams は、デシリアライゼーションエラーからの例外をネイティブに処理する機能を提供します。このサポートの詳細については、こちら [Apache] (英語) を参照してください。Apache Kafka Streams は、デフォルトで、LogAndContinueExceptionHandler と LogAndFailExceptionHandler の 2 種類のデシリアライゼーション例外ハンドラーを提供します。名前が示すように、前者はエラーをログに記録して次のレコードの処理を続行し、後者はエラーをログに記録して失敗します。LogAndFailExceptionHandler は、デフォルトのデシリアライゼーション例外ハンドラーです。
2.6.1. バインダーでの逆直列化例外の処理
Kafka Streams バインダーでは、次のプロパティを使用して、上記の逆直列化例外ハンドラーを指定できます。
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: logAndContinueまたは
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: logAndFail上記の 2 つの逆直列化例外ハンドラーに加えて、バインダーは、誤ったレコード(ポイズンピル)を DLQ(デッドレターキュー)トピックに送信するための 3 番目のハンドラーも提供します。この DLQ 例外ハンドラーを有効にする方法は次のとおりです。
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: sendToDlq上記のプロパティを設定すると、逆直列化エラーのすべてのレコードが自動的に DLQ トピックに送信されます。
DLQ メッセージを公開するトピック名は以下のように設定できます。
関数インターフェースである DlqDestinationResolver の実装を提供できます。DlqDestinationResolver は、ConsumerRecord と例外を入力として受け取り、トピック名を出力として指定できるようにします。Kafka ConsumerRecord にアクセスすることにより、BiFunction の実装でヘッダーレコードをイントロスペクトできます。
これは、DlqDestinationResolver の実装を提供する例です。
@Bean
public DlqDestinationResolver dlqDestinationResolver() {
return (rec, ex) -> {
if (rec.topic().equals("word1")) {
return "topic1-dlq";
}
else {
return "topic2-dlq";
}
};
}DlqDestinationResolver の実装を提供する際に留意すべき重要なことの 1 つは、バインダーのプロビジョナーがアプリケーションのトピックを自動作成しないことです。これは、実装が送信する可能性のあるすべての DLQ トピックの名前をバインダーが推測する方法がないためです。この戦略を使用して DLQ 名を提供する場合、それらのトピックが事前に作成されていることを確認するのはアプリケーションの責任です。
DlqDestinationResolver がアプリケーションに Bean として存在する場合、それが優先されます。このアプローチに従わず、構成を使用して静的 DLQ 名を指定する場合は、次のプロパティを設定できます。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.dlqName: custom-dlq (Change the binding name accordingly) これが設定されている場合、エラーレコードはトピック custom-dlq に送信されます。アプリケーションが上記の戦略のいずれも使用していない場合、error.<input-topic-name>.<application-id> という名前の DLQ トピックが作成されます。たとえば、バインディングの宛先トピックが inputTopic で、アプリケーション ID が process-applicationId の場合、デフォルトの DLQ トピックは error.inputTopic.process-applicationId です。DLQ を有効にする場合は、入力バインディングごとに DLQ トピックを明示的に作成することを常にお勧めします。
2.6.2. 入力コンシューマーバインディングごとの DLQ
プロパティ spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler は、アプリケーション全体に適用できます。これは、同じアプリケーションに複数の関数または StreamListener メソッドがある場合、このプロパティがそれらすべてに適用されることを意味します。ただし、単一のプロセッサー内に複数のプロセッサーまたは複数の入力バインディングがある場合は、バインダーが入力コンシューマーバインディングごとに提供するよりきめ細かい DLQ コントロールを使用できます。
次のプロセッサーを使用している場合
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
}最初の入力バインディングでのみ DLQ を有効にし、2 番目のバインディングで skipAndContinue を有効にしたい場合は、以下のようにコンシューマーで実行できます。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.deserializationExceptionHandler: sendToDlq spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.deserializationExceptionHandler: skipAndContinue
この方法で逆直列化例外ハンドラーを設定すると、バインダーレベルで設定するよりも優先されます。
2.6.3. DLQ パーティショニング
デフォルトでは、レコードは元のレコードと同じパーティションを使用して Dead-Letter トピックに公開されます。つまり、Dead-Letter トピックには、少なくとも元のレコードと同じ数のパーティションが必要です。
この動作を変更するには、DlqPartitionFunction 実装を @Bean としてアプリケーションコンテキストに追加します。そのような Bean は 1 つだけ存在できます。この機能は、コンシューマーグループ(ほとんどの状況でアプリケーション ID と同じ)、失敗した ConsumerRecord、例外とともに提供されます。例: 常にパーティション 0 にルーティングする場合は、次を使用できます。
@Bean
public DlqPartitionFunction partitionFunction() {
return (group, record, ex) -> 0;
} コンシューマーバインディングの dlqPartitions プロパティを 1 に設定する(そして、バインダーの minPartitionCount が 1 に等しい)場合、DlqPartitionFunction を供給する必要はありません。フレームワークは常にパーティション 0 を使用します。コンシューマーバインディングの dlqPartitions プロパティを 1 よりも大きい値に設定した場合(または、バインダーの minPartitionCount が 1 よりも大きい場合)、パーティション数が元のトピックのものと同じであっても、DlqPartitionFunction Bean を必ず提供しなければなりません。 |
Kafka Streams バインダーの例外処理機能を使用する際に留意すべき点がいくつかあります。
プロパティ
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandlerは、アプリケーション全体に適用できます。これは、同じアプリケーションに複数の関数またはStreamListenerメソッドがある場合、このプロパティがそれらすべてに適用されることを意味します。デシリアライズの例外処理は、ネイティブのデシリアライズおよびフレームワークが提供するメッセージ変換と一貫して機能します。
2.6.4. バインダーでの本番例外の処理
上記の逆直列化例外ハンドラーのサポートとは異なり、バインダーは、本番例外を処理するためのそのようなファーストクラスのメカニズムを提供しません。ただし、StreamsBuilderFactoryBean カスタマイザを使用して本番例外ハンドラーを構成することはできます。詳細については、以下の次のセクションを参照してください。
2.7. 重要なビジネスロジックの再試行
アプリケーションにとって重要なビジネスロジックの一部を再試行したいシナリオがあります。リレーショナルデータベースへの外部呼び出し、または Kafka Streams プロセッサーからの REST エンドポイントの呼び出しがある可能性があります。これらの呼び出しは、ネットワークの課題やリモートサービスが利用できないなどのさまざまな理由で失敗する可能性があります。多くの場合、これらの障害は、再試行できれば自己解決する可能性があります。デフォルトでは、Kafka Streams バインダーはすべての入力バインディングに対して RetryTemplate Bean を作成します。
関数に次のシグネチャーがある場合
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() デフォルトのバインディング名では、RetryTemplate は process-in-0-RetryTemplate として登録されます。これは、バインディング名(process-in-0)の後にリテラル -RetryTemplate が続くという規則に従います。複数の入力バインディングの場合、バインディングごとに個別の RetryTemplate Bean を使用できます。アプリケーションで使用可能で、spring.cloud.stream.bindings.<binding-name>.consumer.retryTemplateName を介して提供されるカスタム RetryTemplate Bean がある場合、入力バインディングレベルの再試行テンプレート構成プロパティよりも優先されます。
バインディングからの RetryTemplate がアプリケーションに挿入されると、アプリケーションのクリティカルセクションを再試行するために使用できます。次に例を示します。
@Bean
public java.util.function.Consumer<KStream<Object, String>> process(@Lazy @Qualifier("process-in-0-RetryTemplate") RetryTemplate retryTemplate) {
return input -> input
.process(() -> new Processor<Object, String>() {
@Override
public void init(ProcessorContext processorContext) {
}
@Override
public void process(Object o, String s) {
retryTemplate.execute(context -> {
//Critical business logic goes here.
});
}
@Override
public void close() {
}
});
} または、以下のようにカスタム RetryTemplate を使用できます。
@EnableAutoConfiguration
public static class CustomRetryTemplateApp {
@Bean
@StreamRetryTemplate
RetryTemplate fooRetryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
RetryPolicy retryPolicy = new SimpleRetryPolicy(4);
FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();
backOffPolicy.setBackOffPeriod(1);
retryTemplate.setBackOffPolicy(backOffPolicy);
retryTemplate.setRetryPolicy(retryPolicy);
return retryTemplate;
}
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
return input -> input
.process(() -> new Processor<Object, String>() {
@Override
public void init(ProcessorContext processorContext) {
}
@Override
public void process(Object o, String s) {
fooRetryTemplate().execute(context -> {
//Critical business logic goes here.
});
}
@Override
public void close() {
}
});
}
} 再試行が完了すると、デフォルトでは最後の例外がスローされ、プロセッサーが終了することに注意してください。例外を処理して処理を続行する場合は、RecoveryCallback を execute メソッドに追加できます。例を次に示します。
retryTemplate.execute(context -> {
//Critical business logic goes here.
}, context -> {
//Recovery logic goes here.
return null;
));RetryTemplate、再試行ポリシー、バックオフポリシーなどの詳細については、Spring Retry [GitHub] (英語) プロジェクトを参照してください。
2.8. ステートストア
ステートストアは、高レベル DSL が使用され、ステートストアをトリガーする適切な呼び出しが行われると、Kafka ストリームによって自動的に作成されます。
受信 KTable バインディングを名前付き状態ストアとして実体化する場合は、次の戦略を使用して実行できます。
次の機能があるとしましょう。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
} 次に、次のプロパティを設定することにより、受信 KTable データが指定された状態ストアにマテリアライズされます。
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.materializedAs: incoming-storeアプリケーションでカスタム状態ストアを Bean として定義すると、それらが検出され、バインダーによって Kafka Streams ビルダーに追加されます。特にプロセッサー API を使用する場合は、状態ストアを手動で登録する必要があります。そのために、アプリケーションで StateStore を Bean として作成できます。このような Bean の定義例を次に示します。
@Bean
public StoreBuilder myStore() {
return Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("my-store"), Serdes.Long(),
Serdes.Long());
}
@Bean
public StoreBuilder otherStore() {
return Stores.windowStoreBuilder(
Stores.persistentWindowStore("other-store",
1L, 3, 3L, false), Serdes.Long(),
Serdes.Long());
}これらの状態ストアには、アプリケーションから直接アクセスできます。
ブートストラップ中に、上記の Bean はバインダーによって処理され、Streams ビルダーオブジェクトに渡されます。
ステートストアへのアクセス:
Processor<Object, Product>() {
WindowStore<Object, String> state;
@Override
public void init(ProcessorContext processorContext) {
state = (WindowStore)processorContext.getStateStore("mystate");
}
...
} これは、グローバルステートストアの登録に関しては機能しません。グローバルステートストアを登録するには、StreamsBuilderFactoryBean のカスタマイズに関する以下のセクションを参照してください。
2.9. インタラクティブクエリ
Kafka Streams バインダー API は、InteractiveQueryService と呼ばれるクラスを公開して、状態ストアをインタラクティブにクエリします。これは、アプリケーションで Spring Bean としてアクセスできます。アプリケーションからこの Bean にアクセスする簡単な方法は、Bean を autowire することです。
@Autowired
private InteractiveQueryService interactiveQueryService;この Bean にアクセスできるようになると、関心のある特定の状態ストアを照会できます。下記参照。
ReadOnlyKeyValueStore<Object, Object> keyValueStore =
interactiveQueryService.getQueryableStoreType("my-store", QueryableStoreTypes.keyValueStore());起動時に、ストアを取得するための上記のメソッド呼び出しが失敗する場合があります。例: まだ状態ストアの初期化の途中である可能性があります。このような場合は、この操作を再試行すると便利です。Kafka Streams バインダーは、これに対応するための単純な再試行メカニズムを提供します。
以下は、この再試行を制御するために使用できる 2 つのプロパティです。
spring.cloud.stream.kafka.streams.binder.stateStoreRetry.maxAttempts - デフォルトは
1です。spring.cloud.stream.kafka.streams.binder.stateStoreRetry.backOffInterval - デフォルトは
1000ミリ秒です。
kafka ストリームアプリケーションの複数のインスタンスが実行されている場合、インタラクティブにクエリする前に、クエリしている特定のキーをホストしているアプリケーションインスタンスを特定する必要があります。InteractiveQueryService API は、ホスト情報を識別するためのメソッドを提供します。
これを機能させるには、プロパティ application.server を次のように構成する必要があります。
spring.cloud.stream.kafka.streams.binder.configuration.application.server: <server>:<port>コードスニペットは次のとおりです。
org.apache.kafka.streams.state.HostInfo hostInfo = interactiveQueryService.getHostInfo("store-name",
key, keySerializer);
if (interactiveQueryService.getCurrentHostInfo().equals(hostInfo)) {
//query from the store that is locally available
}
else {
//query from the remote host
}これらのホスト検索メソッドの詳細については、メソッドに関する Javadoc を参照してください。これらのメソッドでも、起動時に、基になる KafkaStreams オブジェクトの準備ができていない場合、例外がスローされる可能性があります。前述の再試行プロパティは、これらのメソッドにも適用できます。
2.9.1. InteractiveQueryService を通じて利用可能な他の API メソッド
次の API メソッドを使用して、指定されたストアとキーの組み合わせに関連付けられた KeyQueryMetadata オブジェクトを取得します。
public <K> KeyQueryMetadata getKeyQueryMetadata(String store, K key, Serializer<K> serializer) 次の API メソッドを使用して、指定されたストアとキーの組み合わせに関連付けられた KakfaStreams オブジェクトを取得します。
public <K> KafkaStreams getKafkaStreams(String store, K key, Serializer<K> serializer)2.10. ヘルス指標
ヘルスインジケータには、依存関係 spring-boot-starter-actuator が必要です。maven の使用:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Spring Cloud Stream Kafka Streams Binder は、基になるストリームスレッドの状態をチェックするためのヘルスインジケーターを提供します。Spring Cloud Stream は、ヘルスインジケーターを有効にするプロパティ management.health.binders.enabled を定義します。Spring Cloud Stream ドキュメント (英語) を参照してください。
ヘルスインジケータは、各ストリームスレッドのメタデータについて次の詳細を提供します。
スレッド名
スレッドの状態:
CREATED、RUNNING、PARTITIONS_REVOKED、PARTITIONS_ASSIGNED、PENDING_SHUTDOWNまたはDEADアクティブタスク: タスク ID とパーティション
スタンバイタスク: タスク ID とパーティション
デフォルトでは、グローバルステータス(UP または DOWN)のみが表示されます。詳細を表示するには、プロパティ management.endpoint.health.show-details を ALWAYS または WHEN_AUTHORIZED に設定する必要があります。ヘルス情報の詳細については、Spring Boot Actuator ドキュメントを参照してください。
登録されているすべての Kafka スレッドが RUNNING 状態にある場合、ヘルスインジケーターのステータスは UP です。 |
Kafka Streams バインダー(KStream、KTable、GlobalKTable)には 3 つの個別のバインダーがあるため、それらすべてがヘルスステータスを報告します。show-details を有効にすると、報告される情報の一部が冗長になる場合があります。
同じアプリケーションに複数の Kafka Streams プロセッサーが存在する場合、それらすべてのヘルスチェックが報告され、Kafka Streams のアプリケーション ID によって分類されます。
2.11. Kafka ストリームメトリクスへのアクセス
Spring Cloud Stream Kafka Streams バインダーは、Micrometer MeterRegistry を介してエクスポートできる Kafka Streams メトリクスを提供します。
Spring Boot バージョン 2.2.x の場合、メトリクスのサポートは、バインダーによるカスタム Micrometer メトリクスの実装を通じて提供されます。Spring Boot バージョン 2.3.x の場合、Kafka ストリームメトリクスのサポートは、Micrometer を介してネイティブに提供されます。
Boot アクチュエーターエンドポイントを介してメトリクスにアクセスする場合は、必ず metrics をプロパティ management.endpoints.web.exposure.include に追加してください。次に、/acutator/metrics にアクセスして、使用可能なすべてのメトリクスのリストを取得し、同じ URI(/actuator/metrics/<metric-name>)を介して個別にアクセスできます。
2.12. 高レベル DSL と低レベルプロセッサー API の混合
Kafka Streams は、API の 2 つのバリアントを提供します。API のような高レベルの DSL があり、多くの関数型プログラマーに馴染みのあるさまざまな操作をチェーンで実行できます。Kafka Streams は、低レベルのプロセッサー API へのアクセスも提供します。プロセッサー API は非常に強力であり、はるかに低いレベルで物事を制御する機能を提供しますが、本質的に不可欠です。Spring Cloud Stream 用の Kafka Streams バインダーを使用すると、高レベル DSL を使用するか、DSL とプロセッサー API の両方を混在させることができます。これらのバリアントの両方を組み合わせると、アプリケーションのさまざまなユースケースを制御するための多くのオプションが得られます。アプリケーションは、transform または process メソッド API 呼び出しを使用して、プロセッサー API にアクセスできます。
これは、process API を使用して Spring Cloud Stream アプリケーションで DSL とプロセッサー API の両方を組み合わせる方法を示しています。
@Bean
public Consumer<KStream<Object, String>> process() {
return input ->
input.process(() -> new Processor<Object, String>() {
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(Object key, String value) {
//business logic
}
@Override
public void close() {
});
} これは、transform API を使用した例です。
@Bean
public Consumer<KStream<Object, String>> process() {
return (input, a) ->
input.transform(() -> new Transformer<Object, String, KeyValue<Object, String>>() {
@Override
public void init(ProcessorContext context) {
}
@Override
public void close() {
}
@Override
public KeyValue<Object, String> transform(Object key, String value) {
// business logic - return transformed KStream;
}
});
}process API メソッド呼び出しは終端記号操作ですが、transform API は非終端記号であり、DSL またはプロセッサー API のいずれかを使用してさらに処理を続行できる潜在的に変換された KStream を提供します。
2.13. 送信でのパーティションサポート
Kafka ストリームプロセッサーは通常、処理された出力を送信 Kafka トピックに送信します。送信トピックがパーティション化されており、プロセッサーが送信データを特定のパーティションに送信する必要がある場合、アプリケーションは型 StreamPartitioner の Bean を提供する必要があります。詳細については、StreamPartitioner [Apache] (英語) を参照してください。いくつかの例を見てみましょう。
これは、すでに何度も見たのと同じプロセッサーです。
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> process() {
...
}出力バインディングの宛先は次のとおりです。
spring.cloud.stream.bindings.process-out-0.destination: outputTopic トピック outputTopic に 4 つのパーティションがある場合、パーティション化戦略を提供しないと、Kafka ストリームはデフォルトのパーティション化戦略を使用しますが、特定のユースケースによっては希望する結果にならない場合があります。たとえば、spring に一致するすべてのキーをパーティション 0 に、cloud をパーティション 1 に、stream をパーティション 2 に、その他すべてをパーティション 3 に送信するとします。これはアプリケーションで行う必要があることです。
@Bean
public StreamPartitioner<String, WordCount> streamPartitioner() {
return (t, k, v, n) -> {
if (k.equals("spring")) {
return 0;
}
else if (k.equals("cloud")) {
return 1;
}
else if (k.equals("stream")) {
return 2;
}
else {
return 3;
}
};
}これは基本的な実装ですが、レコードのキー / 値、トピック名、パーティションの総数にアクセスできます。必要に応じて複雑なパーティショニング戦略を実装できます。
また、この Bean 名をアプリケーション構成とともに提供する必要があります。
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.streamPartitionerBeanName: streamPartitionerアプリケーションの各出力トピックは、このように個別に構成する必要があります。
2.14. StreamsBuilderFactoryBean カスタマイザー
多くの場合、KafkaStreams オブジェクトを作成する StreamsBuilderFactoryBean をカスタマイズする必要があります。Spring Kafka によって提供される基本的なサポートに基づいて、バインダーを使用して StreamsBuilderFactoryBean をカスタマイズできます。StreamsBuilderFactoryBeanCustomizer を使用して、StreamsBuilderFactoryBean 自体をカスタマイズできます。次に、このカスタマイザーを介して StreamsBuilderFactoryBean にアクセスできるようになると、KafkaStreamsCustomzier を使用して対応する KafkaStreams をカスタマイズできます。これらのカスタマイザーは両方とも Spring for Apache Kafka プロジェクトの一部です。
StreamsBuilderFactoryBeanCustomizer の使用例を次に示します。
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return sfb -> sfb.setStateListener((newState, oldState) -> {
//Do some action here!
});
} 上記は、StreamsBuilderFactoryBean をカスタマイズするためにできることの例として示されています。基本的に、StreamsBuilderFactoryBean から使用可能なミューテーション操作を呼び出してカスタマイズできます。このカスタマイザは、ファクトリ Bean が開始される直前にバインダーによって呼び出されます。
StreamsBuilderFactoryBean にアクセスできるようになったら、基になる KafkaStreams オブジェクトをカスタマイズすることもできます。これを行うための青写真があります。
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return factoryBean -> {
factoryBean.setKafkaStreamsCustomizer(new KafkaStreamsCustomizer() {
@Override
public void customize(KafkaStreams kafkaStreams) {
kafkaStreams.setUncaughtExceptionHandler((t, e) -> {
});
}
});
};
}KafkaStreamsCustomizer は、基礎となる KafkaStreams が開始される直前に StreamsBuilderFactoryBeabn によって呼び出されます。
アプリケーション全体に存在できる StreamsBuilderFactoryBeanCustomizer は 1 つだけです。次に、複数の Kafka ストリームプロセッサーはそれぞれ個別の StreamsBuilderFactoryBean オブジェクトによってバックアップされるため、どのように説明しますか? その場合、それらのプロセッサーごとにカスタマイズを変える必要がある場合、アプリケーションはアプリケーション ID に基づいて何らかのフィルターを適用する必要があります。
たとえば
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return factoryBean -> {
if (factoryBean.getStreamsConfiguration().getProperty(StreamsConfig.APPLICATION_ID_CONFIG)
.equals("processor1-application-id")) {
factoryBean.setKafkaStreamsCustomizer(new KafkaStreamsCustomizer() {
@Override
public void customize(KafkaStreams kafkaStreams) {
kafkaStreams.setUncaughtExceptionHandler((t, e) -> {
});
}
});
}
};2.14.1. カスタマイザーを使用してグローバル状態ストアを登録する
上記のように、バインダーは、グローバル状態ストアを機能として登録するためのファーストクラスの方法を提供しません。そのためには、カスタマイザーを使用する必要があります。これがその方法です。
@Bean
public StreamsBuilderFactoryBeanCustomizer customizer() {
return fb -> {
try {
final StreamsBuilder streamsBuilder = fb.getObject();
streamsBuilder.addGlobalStore(...);
}
catch (Exception e) {
}
};
} 繰り返しますが、複数のプロセッサーがある場合は、上記のようにアプリケーション ID を使用して他の StreamsBuilderFactoryBean オブジェクトを除外することにより、グローバル状態ストアを右側の StreamsBuilder に接続する必要があります。
2.14.2. カスタマイザーを使用した実動例外ハンドラーの登録
エラー処理のセクションでは、バインダーが本番例外を処理するためのファーストクラスの方法を提供しないことを示しました。その場合でも、StreamsBuilderFacotryBean カスタマイザーを使用して実動例外ハンドラーを登録することができます。下記参照。
@Bean
public StreamsBuilderFactoryBeanCustomizer customizer() {
return fb -> {
fb.getStreamsConfiguration().put(StreamsConfig.DEFAULT_PRODUCTION_EXCEPTION_HANDLER_CLASS_CONFIG,
CustomProductionExceptionHandler.class);
};
} 繰り返しになりますが、複数のプロセッサーがある場合は、正しい StreamsBuilderFactoryBean に対して適切に設定することをお勧めします。構成プロパティを使用してこのような本番例外ハンドラーを追加することもできますが(詳細については以下を参照)、プログラムによるアプローチを選択する場合はこれがオプションです。
2.15. タイムスタンプ抽出
Kafka Streams を使用すると、タイムスタンプのさまざまな概念に基づいてコンシューマーレコードの処理を制御できます。デフォルトでは、Kafka Streams はコンシューマーレコードに埋め込まれたタイムスタンプメタデータを抽出します。入力バインディングごとに異なる TimestampExtractor 実装を提供することにより、このデフォルトの動作を変更できます。これを行う方法の詳細を次に示します。
@Bean
public Function<KStream<Long, Order>,
Function<KTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, Order>>>> process() {
return orderStream ->
customers ->
products -> orderStream;
}
@Bean
public TimestampExtractor timestampExtractor() {
return new WallclockTimestampExtractor();
} 次に、コンシューマーバインディングごとに上記の TimestampExtractor Bean 名を設定します。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.timestampExtractorBeanName=timestampExtractor
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.timestampExtractorBeanName=timestampExtractor
spring.cloud.stream.kafka.streams.bindings.process-in-2.consumer.timestampExtractorBeanName=timestampExtractor"カスタムタイムスタンプエクストラクターを設定するために入力コンシューマーバインディングをスキップすると、そのコンシューマーはデフォルト設定を使用します。
2.16. Kafka ストリームベースのバインダーと通常の Kafka バインダーを備えたマルチバインダー
通常の Kafka バインダーに基づく関数 / コンシューマー / サプライヤーと Kafka ストリームベースのプロセッサーの両方を備えたアプリケーションを使用できます。ただし、単一の関数またはコンシューマー内で両方を混在させることはできません。
これは、同じアプリケーション内に両方のバインダーベースのコンポーネントがある例です。
@Bean
public Function<String, String> process() {
return s -> s;
}
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> kstreamProcess() {
return input -> input;
}これは、構成の関連部分です。
spring.cloud.stream.function.definition=process;kstreamProcess
spring.cloud.stream.bindings.process-in-0.destination=foo
spring.cloud.stream.bindings.process-out-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-in-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-out-0.destination=foobar 上記と同じアプリケーションを使用している場合、状況は少し複雑になりますが、2 つの異なる Kafka クラスターを処理します。たとえば、通常の process は Kafka クラスター 1 とクラスター 2 の両方に作用します(クラスター 1 からデータを受信してクラスターに送信します) -2)Kafka Streams プロセッサーが Kafka クラスター 2 に作用しています。次に、Spring Cloud Stream が提供するマルチバインダー機能を使用する必要があります。
そのシナリオで構成がどのように変更されるかを次に示します。
# multi binder configuration
spring.cloud.stream.binders.kafka1.type: kafka
spring.cloud.stream.binders.kafka1.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-1} #Replace kafkaCluster-1 with the approprate IP of the cluster
spring.cloud.stream.binders.kafka2.type: kafka
spring.cloud.stream.binders.kafka2.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2} #Replace kafkaCluster-2 with the approprate IP of the cluster
spring.cloud.stream.binders.kafka3.type: kstream
spring.cloud.stream.binders.kafka3.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2} #Replace kafkaCluster-2 with the approprate IP of the cluster
spring.cloud.stream.function.definition=process;kstreamProcess
# From cluster 1 to cluster 2 with regular process function
spring.cloud.stream.bindings.process-in-0.destination=foo
spring.cloud.stream.bindings.process-in-0.binder=kafka1 # source from cluster 1
spring.cloud.stream.bindings.process-out-0.destination=bar
spring.cloud.stream.bindings.process-out-0.binder=kafka2 # send to cluster 2
# Kafka Streams processor on cluster 2
spring.cloud.stream.bindings.kstreamProcess-in-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-in-0.binder=kafka3
spring.cloud.stream.bindings.kstreamProcess-out-0.destination=foobar
spring.cloud.stream.bindings.kstreamProcess-out-0.binder=kafka3 上記の構成に注意してください。2 種類のバインダーがありますが、全部で 3 つのバインダーがあります。最初のバインダーはクラスター 1 に基づく通常の Kafka バインダー(kafka1)、次にクラスター 2 に基づく別の Kafka バインダー(kafka2)、最後に kstream バインダー(kafka3)です。アプリケーションの最初のプロセッサーは、kafka1 からデータを受信し、kafka2 に公開します。ここで、両方のバインダーは通常の Kafka バインダーに基づいていますが、クラスターが異なります。2 番目のプロセッサーである Kafka Streams プロセッサーは、kafka2 と同じクラスターであるがバインダー型が異なる kafka3 からのデータを消費します。
Kafka Streams ファミリーのバインダーには 3 つの異なるバインダー型(kstream、ktable、globalktable)があるため、アプリケーションにこれらのバインダーのいずれかに基づく複数のバインディングがある場合は、バインダー型として明示的に指定する必要があります。
たとえば、以下のようなプロセッサーを使用している場合
@Bean
public Function<KStream<Long, Order>,
Function<KTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, EnrichedOrder>>>> enrichOrder() {
...
}次に、これをマルチバインダーシナリオで次のように構成する必要があります。これは、単一のアプリケーション内で複数のクラスターを処理する複数のプロセッサーが存在する真のマルチバインダーシナリオがある場合にのみ必要であることに注意してください。その場合、他のプロセッサーのバインダー型やクラスターと区別するために、バインダーにバインディングを明示的に提供する必要があります。
spring.cloud.stream.binders.kafka1.type: kstream
spring.cloud.stream.binders.kafka1.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.binders.kafka2.type: ktable
spring.cloud.stream.binders.kafka2.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.binders.kafka3.type: globalktable
spring.cloud.stream.binders.kafka3.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.bindings.enrichOrder-in-0.binder=kafka1 #kstream
spring.cloud.stream.bindings.enrichOrder-in-1.binder=kafka2 #ktablr
spring.cloud.stream.bindings.enrichOrder-in-2.binder=kafka3 #globalktable
spring.cloud.stream.bindings.enrichOrder-out-0.binder=kafka1 #kstream
# rest of the configuration is omitted.2.17. 状態のクリーンアップ
デフォルトでは、バインディングが停止してもローカル状態はクリーンアップされません。これは、Spring Kafka バージョン 2.7 から有効な動作と同じです。詳細については、Spring Kafka ドキュメントを参照してください。この動作を変更するには、単一の CleanupConfig @Bean (開始時、停止時、どちらもクリーンアップしないように構成されている)をアプリケーションコンテキストに追加するだけです。Bean が検出され、ファクトリの Bean に接続されます。
2.18. Kafka ストリームトポロジの視覚化
Kafka Streams バインダーは、外部ツールを使用してトポロジーを視覚化できるトポロジー記述を取得するための以下のアクチュエーターエンドポイントを提供します。
/actuator/kafkastreamstopology
/actuator/kafkastreamstopology/<application-id of the processor>
これらのエンドポイントにアクセスするには、Spring Boot からのアクチュエーターと Web の依存関係を含める必要があります。さらに、kafkastreamstopology を management.endpoints.web.exposure.include プロパティに追加する必要もあります。デフォルトでは、kafkastreamstopology エンドポイントは無効になっています。
2.19. Kafka Streams アプリケーションでのイベント型ベースのルーティング
通常のメッセージチャネルベースのバインダーで使用可能なルーティング機能は、Kafka ストリームバインダーではサポートされていません。ただし、Kafka Streams バインダーは、受信レコードのイベント型レコードヘッダーを介したルーティング機能を引き続き提供します。
イベント型に基づくルーティングを有効にするには、アプリケーションは次のプロパティを提供する必要があります。
spring.cloud.stream.kafka.streams.bindings.<binding-name>.consumer.eventTypes.
これはコンマ区切りの値にすることができます。
例: この関数があると仮定しましょう:
@Bean
public Function<KStream<Integer, Foo>, KStream<Integer, Foo>> process() {
return input -> input;
} また、受信レコードのイベント型が foo または bar の場合、この関数のビジネスロジックのみを実行する必要があると仮定します。これは、バインディングの eventTypes プロパティを使用して次のように表すことができます。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.eventTypes=foo,bar
これで、アプリケーションの実行時に、バインダーはヘッダー event_type の各受信レコードをチェックし、値が foo または bar として設定されているかどうかを確認します。どちらも見つからない場合、関数の実行はスキップされます。
デフォルトでは、バインダーはレコードヘッダーキーが event_type であることを想定していますが、これはバインディングごとに変更できます。たとえば、このバインディングのヘッダーキーをデフォルトではなく my_event に変更する場合は、次のように変更できます。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.eventTypeHeaderKey=my_event.
2.20. Kafka Streams バインダーでの結合の視覚化と制御
バージョン 3.1.2 以降、Kafka Streams バインダーはバインディングの視覚化と制御をサポートします。サポートされているライフサイクルフェーズは、STOPPED と STARTED の 2 つだけです。ライフサイクルフェーズ PAUSED および RESUMED は、Kafka Streams バインダーでは使用できません。
バインディングの視覚化と制御をアクティブにするには、アプリケーションに次の 2 つの依存関係を含める必要があります。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>webflux を使用したい場合は、標準の Web 依存関係の代わりに spring-boot-starter-webflux を含めることができます。
さらに、次のプロパティも設定する必要があります。
management.endpoints.web.exposure.include=bindingsこの機能をさらに説明するために、次のアプリケーションをガイドとして使用してみましょう。
@SpringBootApplication
public class KafkaStreamsApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaStreamsApplication.class, args);
}
@Bean
public Consumer<KStream<String, String>> consumer() {
return s -> s.foreach((key, value) -> System.out.println(value));
}
@Bean
public Function<KStream<String, String>, KStream<String, String>> function() {
return ks -> ks;
}
} ご覧のとおり、アプリケーションには 2 つの Kafka ストリーム関数があります。1 つはコンシューマー関数で、もう 1 つは関数です。コンシューマーバインディングは、デフォルトで consumer-in-0 という名前が付けられています。同様に、関数の場合、入力バインディングは function-in-0 であり、出力バインディングは function-out-0 です。
アプリケーションが開始されると、次のバインディングエンドポイントを使用してバインディングの詳細を見つけることができます。
curl http://localhost:8080/actuator/bindings | jq .
[
{
"bindingName": "consumer-in-0",
"name": "consumer-in-0",
"group": "consumer-applicationId",
"pausable": false,
"state": "running",
"paused": false,
"input": true,
"extendedInfo": {}
},
{
"bindingName": "function-in-0",
"name": "function-in-0",
"group": "function-applicationId",
"pausable": false,
"state": "running",
"paused": false,
"input": true,
"extendedInfo": {}
},
{
"bindingName": "function-out-0",
"name": "function-out-0",
"group": "function-applicationId",
"pausable": false,
"state": "running",
"paused": false,
"input": false,
"extendedInfo": {}
}
]3 つのバインディングすべての詳細については、上記を参照してください。
ここで、consumer-in-0 バインディングを停止しましょう。
curl -d '{"state":"STOPPED"}' -H "Content-Type: application/json" -X POST http://localhost:8080/actuator/bindings/consumer-in-0こでは、このバインディングを介してレコードは受信されません。
バインディングを再開します。
curl -d '{"state":"STARTED"}' -H "Content-Type: application/json" -X POST http://localhost:8080/actuator/bindings/consumer-in-01 つの関数に複数のバインディングが存在する場合、それらのバインディングのいずれかでこれらの操作を呼び出すことが機能します。これは、単一の関数のすべてのバインディングが同じ StreamsBuilderFactoryBean によってサポートされているためです。上記の機能では、function-in-0 または function-out-0 のいずれかが機能します。
2.21. Kafka Streams プロセッサーを手動で開始する
Spring Cloud Stream Kafka Streams バインダーは、Spring for Apache Kafka の StreamsBuilderFactoryBean の上に StreamsBuilderFactoryManager と呼ばれる抽象化を提供します。このマネージャー API は、バインダーベースのアプリケーションでプロセッサーごとに複数の StreamsBuilderFactoryBean を制御するために使用されます。バインダーを使用するときに、アプリケーションでさまざまな StreamsBuilderFactoryBean オブジェクトの自動起動を手動で制御する場合は、StreamsBuilderFactoryManager を使用する必要があります。プロセッサーの自動始動をオフにするために、プロパティ spring.kafka.streams.auto-startup を使用し、これを false に設定することができます。次に、アプリケーションで、以下のようなものを使用して、StreamsBuilderFactoryManager を使用してプロセッサーを起動できます。
@Bean
public ApplicationRunner runner(StreamsBuilderFactoryManager sbfm) {
return args -> {
sbfm.start();
};
} この機能は、アプリケーションをメインスレッドで起動し、Kafka Streams プロセッサーを個別に起動させる場合に便利です。例: 復元する必要のある大きな状態ストアがある場合、デフォルトの場合のようにプロセッサーが正常に起動すると、アプリケーションの起動がブロックされる可能性があります。ある種のライブネスプローブメカニズム(Kubernetes など)を使用している場合、アプリケーションがダウンしていると見なして再起動を試みる場合があります。これを修正するには、spring.kafka.streams.auto-startup を false に設定し、上記のアプローチに従うことができます。
Spring Cloud Stream バインダーを使用する場合、StreamsBuilderFactoryBean オブジェクトはバインダーによって内部的に管理されるため、Spring for Apache Kafka から StreamsBuilderFactoryBean を直接処理するのではなく、StreamsBuilderFactoryManager を処理することに注意してください。
2.22. Kafka Streams プロセッサーを選択的に手動で開始する
上記のアプローチでは、StreamsBuilderFactoryManager を介してアプリケーション内のすべての Kafka ストリームプロセッサーに無条件に自動開始 false が適用されますが、個別に選択された Kafka ストリームプロセッサーのみが自動開始されないことが望ましい場合がよくあります。たとえば、アプリケーションに 3 つの異なる関数(プロセッサー)があり、そのうちの 1 つについて、アプリケーションの起動の一部として起動したくないとします。このような状況の例を次に示します。
@Bean
public Function<KStream<?, ?>, KStream<?, ?>> process1() {
}
@Bean
public Consumer<KStream<?, ?>> process2() {
}
@Bean
public BiFunction<KStream<?, ?>, KTable<?, ?>, KStream<?, ?>> process3() {
} 上記のシナリオで、spring.kafka.streams.auto-startup を false に設定すると、アプリケーションの起動時にプロセッサーはいずれも自動起動しません。その場合は、前述のように、基盤となる StreamsBuilderFactoryManager で start() を呼び出して、プログラムでプロセッサーを起動する必要があります。ただし、1 つのプロセッサーのみを選択的に無効にするユースケースがある場合は、そのプロセッサーの個別のバインディングで auto-startup を設定する必要があります。process3 関数を自動起動したくないとします。これは、process3-in-0 と process3-in-1 の 2 つの入力バインディングを持つ BiFunction です。このプロセッサーの自動起動を回避するには、これらの入力バインディングのいずれかを選択し、それらに auto-startup を設定します。どのバインディングを選択してもかまいません。必要に応じて、両方に auto-startup を false に設定することもできますが、1 つで十分です。これらは同じファクトリ Bean を共有しているため、両方のバインディングで autoStartup を false に設定する必要はありませんが、わかりやすくするためにそうすることが理にかなっていると考えられます。
このプロセッサーの自動起動を無効にするために使用できる Spring Cloud Stream プロパティは次のとおりです。
spring.cloud.stream.bindings.process3-in-0.consumer.auto-startup: falseまたは
spring.cloud.stream.bindings.process3-in-1.consumer.auto-startup: false 次に、以下に示すように、REST エンドポイントまたは BindingsEndpoint API を使用して、プロセッサーを手動で起動できます。このためには、Spring Boot アクチュエーターがクラスパスに依存していることを確認する必要があります。
curl -d '{"state":"STARTED"}' -H "Content-Type: application/json" -X POST http://localhost:8080/actuator/bindings/process3-in-0または
@Autowired
BindingsEndpoint endpoint;
@Bean
public ApplicationRunner runner() {
return args -> {
endpoint.changeState("process3-in-0", State.STARTED);
};
}このメカニズムの詳細については、リファレンスドキュメントのこのセクションを参照してください。
このセクションに従って auto-startup を無効にしてバインディングを制御する場合、これはコンシューマーバインディングでのみ使用可能であることに注意してください。つまり、プロデューサーバーインディング process3-out-0 を使用する場合、このプロデューサーバーインディングはコンシューマーバインディングと同じ StreamsBuilderFactoryBean を使用しますが、プロセッサーの自動起動を無効にすることに関しては何の効果もありません。 |
2.23. Spring Cloud Sleuth を使用したトレース
Spring Cloud Sleuth が Spring Cloud Stream Kafka Streams バインダーベースのアプリケーションのクラスパス上にある場合、そのコンシューマーとプロデューサーの両方にトレース情報が自動的に組み込まれます。ただし、アプリケーション固有の操作をトレースするには、ユーザーコードで明示的にインストルメント化する必要があります。これは、アプリケーションの Spring Cloud Sleuth から KafkaStreamsTracing Bean を注入し、この注入された Bean を介してさまざまな Kafka ストリーム操作を呼び出すことで実行できます。これはそれを使用するいくつかの例です。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> clicks(KafkaStreamsTracing kafkaStreamsTracing) {
return (userClicksStream, userRegionsTable) -> (userClicksStream
.transformValues(kafkaStreamsTracing.peek("span-1", (key, value) -> LOG.info("key/value: " + key + "/" + value)))
.leftJoin(userRegionsTable, (clicks, region) -> new RegionWithClicks(region == null ?
"UNKNOWN" : region, clicks),
Joined.with(Serdes.String(), Serdes.Long(), null))
.transform(kafkaStreamsTracing.map("span-2", (key, value) -> {
LOG.info("Click Info: " + value.getRegion() + "/" + value.getClicks());
return new KeyValue<>(value.getRegion(),
value.getClicks());
}))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
.reduce(Long::sum, Materialized.as(CLICK_UPDATES))
.toStream());
} 上記の例では、明示的なトレースインストルメンテーションを追加する場所が 2 つあります。まず、受信 KStream からのキー / 値情報をログに記録します。この情報がログに記録されると、関連するスパン ID とトレース ID もログに記録されるため、監視システムはそれらを追跡し、同じスパン ID と関連付けることができます。次に、map 操作を呼び出すときは、KStream クラスで直接呼び出すのではなく、transform 操作内にラップしてから、KafkaStreamsTracing から map を呼び出します。この場合も、ログに記録されるメッセージにはスパン ID とトレース ID が含まれます。
これは別の例で、さまざまな Kafka Streams ヘッダーにアクセスするために低レベルのトランスフォーマー API を使用しています。spring-cloud-sleuth がクラスパス上にある場合、すべてのトレースヘッダーにもこのようにアクセスできます。
@Bean
public Function<KStream<String, String>, KStream<String, String>> process(KafkaStreamsTracing kafkaStreamsTracing) {
return input -> input.transform(kafkaStreamsTracing.transformer(
"transformer-1",
() -> new Transformer<String, String, KeyValue<String, String>>() {
ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public KeyValue<String, String> transform(String key, String value) {
LOG.info("Headers: " + this.context.headers());
LOG.info("K/V:" + key + "/" + value);
// More transformations, business logic execution, etc. go here.
return KeyValue.pair(key, value);
}
@Override
public void close() {
}
}));
}2.24. 構成オプション
このセクションには、Kafka Streams バインダーで使用される構成オプションが含まれています。
バインダーに関連する一般的な構成オプションとプロパティについては、コアドキュメントを参照してください。
2.24.1. Kafka ストリームバインダーのプロパティ
次のプロパティはバインダーレベルで使用でき、spring.cloud.stream.kafka.streams.binder. のプレフィックスを付ける必要があります。Kafka Streams バインダーで再利用されるプロパティを提供する Kafka バインダーには、spring.cloud.stream.kafka.binder ではなく spring.cloud.stream.kafka.streams.binder のプレフィックスを付ける必要があります。このルールの唯一の例外は、Kafka ブートストラップサーバープロパティを定義する場合です。この場合、どちらのプレフィックスも機能します。
- 構成
Apache Kafka Streams API に関連するプロパティを含むキー / 値のペアでマップします。このプロパティには、
spring.cloud.stream.kafka.streams.binder.というプレフィックスを付ける必要があります。次に、このプロパティの使用例をいくつか示します。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.cloud.stream.kafka.streams.binder.configuration.commit.interval.ms=1000 ストリーム構成に含まれる可能性のあるすべてのプロパティの詳細については、Apache Kafka ストリームドキュメントの StreamsConfig JavaDocs を参照してください。StreamsConfig から設定できるすべての構成は、これを通じて設定できます。このプロパティを使用する場合、これはバインダーレベルのプロパティであるため、アプリケーション全体に適用されます。アプリケーションにプロセッサーが 個以上ある場合は、すべてのプロセッサーがこれらのプロパティを取得します。application.id などのプロパティの場合、これは問題になるため、このバインダーレベルの configuration プロパティを使用して StreamsConfig のプロパティがどのようにマップされるかを慎重に調べる必要があります。
- 関数。<function-bean-name> .applicationId
機能スタイルのプロセッサーにのみ適用されます。これは、アプリケーションの機能ごとにアプリケーション ID を設定するために使用できます。複数の機能がある場合、これはアプリケーション ID を設定するための便利な方法です。
- 関数。<function-bean-name> .configuration
関数型プロセッサーにのみ適用されます。Apache Kafka ストリーム API に関連するプロパティを含むキー / 値ペアでマップします。これは、上記のバインダーレベルの
configurationプロパティに似ていますが、このレベルのconfigurationプロパティは、指定された関数に対してのみ制限されます。複数のプロセッサーがあり、特定の関数に基づいて構成へのアクセスを制限する場合は、これを使用できます。ここでは、すべてのStreamsConfigプロパティを使用できます。- ブローカー
ブローカーの URL
デフォルト:
localhost- zkNodes
Zookeeper URL
デフォルト:
localhost- deserializationExceptionHandler
デシリアライズエラーハンドラー型。このハンドラーはバインダーレベルで適用されるため、アプリケーション内のすべての入力バインディングに対して適用されます。コンシューマーの拘束力のあるレベルで、よりきめ細かい方法でそれを制御する方法があります。可能な値は -
logAndContinue、logAndFail、skipAndContinueまたはsendToDlqです。デフォルト:
logAndFail- applicationId
Kafka Streams アプリケーションの application.id をバインダーレベルでグローバルに設定する便利な方法。アプリケーションに複数の関数または
StreamListenerメソッドが含まれている場合は、アプリケーション ID を別の方法で設定する必要があります。アプリケーション ID の設定について詳しく説明している上記を参照してください。デフォルト: アプリケーションは静的アプリケーション ID を生成します。詳細については、アプリケーション ID のセクションを参照してください。
- stateStoreRetry.maxAttempts
Max は、状態ストアへの接続を試みます。
デフォルト: 1
- stateStoreRetry.backoffPeriod
再試行時に状態ストアに接続しようとしたときのバックオフ期間。
デフォルト: 1000 ミリ秒
- consumerProperties
バインダーレベルでの任意のコンシューマー特性。
- producerProperties
バインダーレベルでの任意のプロデューサープロパティ。
- includeStoppedProcessorsForHealthCheck
プロセッサーのバインディングがアクチュエーターを介して停止されると、このプロセッサーはデフォルトではヘルスチェックに参加しません。このプロパティを
trueに設定すると、バインディングアクチュエーターエンドポイントを介して現在停止しているプロセッサーを含むすべてのプロセッサーのヘルスチェックが有効になります。デフォルト: false
2.24.2. Kafka ストリームプロデューサーのプロパティ
次のプロパティは Kafka Streams プロデューサーでのみ使用可能であり、接頭辞 spring.cloud.stream.kafka.streams.bindings.<binding name>.producer. を付ける必要があります。便宜上、複数の出力バインディングがあり、それらすべてに共通の値が必要な場合は、接頭辞 spring.cloud.stream.kafka.streams.default.producer. を使用して構成できます。
- keySerde
使用するキー serde
デフォルト: メッセージの逆直列化 / 直列化に関する上記の説明を参照してください
- valueSerde
使用する値 serde
デフォルト: メッセージの逆直列化 / 直列化に関する上記の説明を参照してください
- useNativeEncoding
ネイティブエンコーディングを有効 / 無効にするフラグ
デフォルト:
true.- streamPartitionerBeanName
コンシューマーで使用されるカスタム送信パーティショナー Bean 名。アプリケーションは、カスタム
StreamPartitionerを Spring Bean として提供でき、この Bean の名前を、デフォルトの名前の代わりに使用するためにプロデューサーに提供できます。デフォルト: 送信パーティションのサポートについては、上記の説明を参照してください。
- producedAs
プロセッサーが生成するシンクコンポーネントのカスタム名。
Deafult:
none(Kafka ストリームによって生成されます)
2.24.3. Kafka はコンシューマーの特性をストリーミングします
次のプロパティは Kafka Streams コンシューマーで使用でき、接頭辞 spring.cloud.stream.kafka.streams.bindings.<binding-name>.consumer. を付ける必要があります。便宜上、複数の入力バインディングがあり、それらすべてに共通の値が必要な場合は、接頭辞 spring.cloud.stream.kafka.streams.default.consumer. を使用して構成できます。
- applicationId
入力バインディングごとに application.id を設定します。これは、
StreamListenerベースのプロセッサーにのみ推奨されます。機能ベースのプロセッサーについては、上記で概説した他のアプローチを参照してください。デフォルト: 上記を参照。
- keySerde
使用するキー serde
デフォルト: メッセージの逆直列化 / 直列化に関する上記の説明を参照してください
- valueSerde
使用する値 serde
デフォルト: メッセージの逆直列化 / 直列化に関する上記の説明を参照してください
- materializedAs
受信 KTable 型を使用するときにマテリアライズする状態ストア
デフォルト:
none.- useNativeDecoding
ネイティブデコードを有効 / 無効にするフラグ
デフォルト:
true.- dlqName
DLQ トピック名。
デフォルト: エラー処理と DLQ の説明については、上記を参照してください。
- startOffset
消費するコミットされたオフセットがない場合に開始するオフセット。これは主に、コンシューマーがトピックから初めて消費するときに使用されます。Kafka Streams はデフォルト戦略として
earliestを使用し、バインダーは同じデフォルトを使用します。これは、このプロパティを使用してlatestにオーバーライドできます。デフォルト:
earliest.
メモ: コンシューマーで resetOffsets を使用しても、Kafka Streams バインダーには影響しません。メッセージチャネルベースのバインダーとは異なり、Kafka Streams バインダーはオンデマンドで開始または終了しようとはしません。
- deserializationExceptionHandler
デシリアライズエラーハンドラー型。このハンドラーは、前述のバインダーレベルのプロパティとは対照的に、コンシューマーバインディングごとに適用されます。可能な値は -
logAndContinue、logAndFail、skipAndContinueまたはsendToDlqです。デフォルト:
logAndFail- timestampExtractorBeanName
コンシューマーで使用される特定のタイムスタンプ抽出機能 Bean 名。アプリケーションは
TimestampExtractorを Spring Bean として提供でき、この Bean の名前は、デフォルトの名前の代わりに使用するためにコンシューマーに提供できます。デフォルト: タイムスタンプエクストラクターに関する上記の説明を参照してください。
- eventTypes
このバインディングでサポートされているイベント型のコンマ区切りリスト。
デフォルト:
none- eventTypeHeaderKey
このバインディングを介した各受信レコードのイベント型ヘッダーキー。
デフォルト:
event_type- consumedAs
プロセッサーが消費しているソースコンポーネントのカスタム名。
Deafult:
none(Kafka ストリームによって生成されます)
2.24.4. 並行性に関する特記事項
Kafka ストリームでは、num.stream.threads プロパティを使用して、プロセッサーが作成できるスレッドの数を制御できます。これは、バインダー、関数、プロデューサー、コンシューマーレベルで上記のさまざまな configuration オプションを使用して実行できます。コア Spring Cloud Stream がこの目的のために提供する concurrency プロパティを使用することもできます。これを使用するときは、コンシューマーに使用する必要があります。関数または StreamListener のいずれかに複数の入力バインディングがある場合は、これを最初の入力バインディングに設定します。たとえば spring.cloud.stream.bindings.process-in-0.consumer.concurrency を設定すると、バインダーによって num.stream.threads として変換されます。複数のプロセッサーがあり、1 つのプロセッサーがバインディングレベルの同時実行性を定義し、他のプロセッサーは定義しない場合、バインディングレベルの同時実行性がないプロセッサーは、デフォルトで spring.cloud.stream.kafka.streams.binder.configuration.num.stream.threads で指定されたバインダー全体のプロパティに戻ります。このバインダー構成が使用できない場合、アプリケーションは Kafka Streams によって設定されたデフォルトを使用します。
3. ヒント、コツ、レシピ
3.1. Kafka を使用したシンプルな DLQ
3.1.1. 問題文
開発者として、Kafka トピックのレコードを処理するコンシューマーアプリケーションを作成したいと思います。ただし、処理中にエラーが発生した場合は、アプリケーションを完全に停止させたくありません。代わりに、エラーのあるレコードを DLT(Dead-Letter-Topic)に送信してから、新しいレコードの処理を続行したいと思います。
3.1.2. ソリューション
この問題の解決策は、Spring Cloud Stream の DLQ 機能を使用することです。この議論の目的のために、以下が私たちのプロセッサー関数であると仮定しましょう。
@Bean
public Consumer<byte[]> processData() {
return s -> {
throw new RuntimeException();
};これは、処理するすべてのレコードに対して例外をスローする非常に簡単な関数ですが、この関数を使用して、他の同様の状況に拡張することができます。
エラーのあるレコードを DLT に送信するには、次の構成を提供する必要があります。
spring.cloud.stream:
bindings:
processData-in-0:
group: my-group
destination: input-topic
kafka:
bindings:
processData-in-0:
consumer:
enableDlq: true
dlqName: input-topic-dlqDLQ をアクティブ化するには、アプリケーションでグループ名を指定する必要があります。匿名のコンシューマーは DLQ 機能を使用できません。また、Kafka コンシューマーバインディングの enableDLQ プロパティを true に設定して、DLQ を有効にする必要があります。最後に、Kafka コンシューマーバインディングで dlqName を提供することにより、オプションで DLT 名を提供できます。それ以外の場合は、この場合はデフォルトで input-topic-dlq.my-group.error になります。
上記のコンシューマーの例では、ペイロードの型は byte[] であることに注意してください。デフォルトでは、Kafka バインダーの DLQ プロデューサーは型 byte[] のペイロードを想定しています。そうでない場合は、適切なシリアライザーの構成を提供する必要があります。例: コンシューマー関数を次のように書き直してみましょう。
@Bean
public Consumer<String> processData() {
return s -> {
throw new RuntimeException();
};
}次に、Spring Cloud Stream に、DLT に書き込むときにデータをどのように直列化するかを指示する必要があります。このシナリオの変更された構成は次のとおりです。
spring.cloud.stream:
bindings:
processData-in-0:
group: my-group
destination: input-topic
kafka:
bindings:
processData-in-0:
consumer:
enableDlq: true
dlqName: input-topic-dlq
dlqProducerProperties:
configuration:
value.serializer: org.apache.kafka.common.serialization.StringSerializer3.2. 高度な再試行オプションを備えた DLQ
3.2.1. 問題文
これは上記のレシピに似ていますが、開発者として、再試行の処理方法を構成したいと思います。
3.2.2. ソリューション
上記のレシピに従った場合、処理でエラーが発生したときに、Kafka バインダーに組み込まれているデフォルトの再試行オプションを取得します。
デフォルトでは、バインダーは 1 秒の初期遅延で最大 3 回試行され、2.0 乗数はそれぞれ最大遅延 10 秒でバックオフします。これらの構成はすべて、次のように変更できます。
spring.cloud.stream.bindings.processData-in-0.consumer.maxAtttempts
spring.cloud.stream.bindings.processData-in-0.consumer.backOffInitialInterval
spring.cloud.stream.bindings.processData-in-0.consumer.backOffMultipler
spring.cloud.stream.bindings.processData-in-0.consumer.backOffMaxInterval必要に応じて、ブール値のマップを提供することにより、再試行可能な例外のリストを提供することもできます。元:
spring.cloud.stream.bindings.processData-in-0.consumer.retryableExceptions.java.lang.IllegalStateException=true
spring.cloud.stream.bindings.processData-in-0.consumer.retryableExceptions.java.lang.IllegalArgumentException=falseデフォルトでは、上記のマップにリストされていない例外は再試行されます。それが望ましくない場合は、次のように指定して無効にすることができます。
spring.cloud.stream.bindings.processData-in-0.consumer.defaultRetryable=false 独自の RetryTemplate を提供し、バインダーによってスキャンされて使用される @StreamRetryTemplate としてマークすることもできます。これは、より高度な再試行戦略とポリシーが必要な場合に役立ちます。
複数の @StreamRetryTemplate Bean がある場合は、プロパティを使用して、バインディングで必要な Bean を指定できます。
spring.cloud.stream.bindings.processData-in-0.consumer.retry-template-name=<your-retry-template-bean-name>3.3. DLQ を使用した逆直列化エラーの処理
3.3.1. 問題文
Kafka コンシューマーで deserilzartion 例外が発生したプロセッサーがあります。Spring Cloud Stream DLQ メカニズムがそのシナリオをキャッチすることを期待しますが、そうではありません。どうすればこれを処理できますか?
3.3.2. ソリューション
Spring Cloud Stream が提供する通常の DLQ メカニズムは、Kafka コンシューマーが回復不能な逆直列化の例外をスローした場合には役立ちません。これは、コンシューマーの poll() メソッドが戻る前でもこの例外が発生するためです。Spring for Apache Kafka プロジェクトは、この状況でバインダーを支援するためのいくつかの優れた方法を提供します。調べてみましょう。
これが私たちの機能であると仮定します:
@Bean
public Consumer<String> functionName() {
return s -> {
System.out.println(s);
};
} これは、String パラメーターを受け取る簡単な関数です。
Spring Cloud Stream が提供するメッセージコンバーターをバイパスし、代わりにネイティブデシリアライザーを使用したいと考えています。String 型の場合はあまり意味がありませんが、AVRO などのより複雑な型の場合は、外部デシリアライザーに依存する必要があるため、変換を Kafka に委譲する必要があります。
ここで、コンシューマーがデータを受け取ったときに、脱セリル化エラーを引き起こす不良レコードがあると仮定します。たとえば、誰かが String ではなく Integer を渡した可能性があります。その場合、アプリケーションで何もしなければ、例外はチェーンを介して伝播され、アプリケーションは最終的に終了します。
これを処理するために、SeekToCurrentErrorHandler を構成する ListenerContainerCustomizer @Bean を追加できます。この SeekToCurrentErrorHandler は DeadLetterPublishingRecoverer で構成されています。また、コンシューマー用に ErrorHandlingDeserializer を構成する必要があります。それは多くの複雑なことのように聞こえますが、実際には、この場合、これらの 3 つの Bean に要約されます。
@Bean
public ListenerContainerCustomizer<AbstractMessageListenerContainer<byte[], byte[]>> customizer(SeekToCurrentErrorHandler errorHandler) {
return (container, dest, group) -> {
container.setErrorHandler(errorHandler);
};
} @Bean
public SeekToCurrentErrorHandler errorHandler(DeadLetterPublishingRecoverer deadLetterPublishingRecoverer) {
return new SeekToCurrentErrorHandler(deadLetterPublishingRecoverer);
} @Bean
public DeadLetterPublishingRecoverer publisher(KafkaOperations bytesTemplate) {
return new DeadLetterPublishingRecoverer(bytesTemplate);
} それぞれを分析してみましょう。最初のものは、SeekToCurrentErrorHandler を取る ListenerContainerCustomizer Bean です。これで、コンテナーはその特定のエラーハンドラーでカスタマイズされます。コンテナーのカスタマイズについて詳しくは、こちらを参照してください。
2 番目の Bean は、DLT への公開で構成された SeekToCurrentErrorHandler です。SeekToCurrentErrorHandler の詳細については、こちらを参照してください。
3 番目の Bean は、DLT への送信を最終的に担当する DeadLetterPublishingRecoverer です。デフォルトでは、DLT トピックの名前は ORIGINAL_TOPIC_NAME.DLT です。ただし、変更できます。詳細については、ドキュメントを参照してください。
また、アプリケーション構成を介して ErrorHandlingDeserializer を構成する必要があります。
ErrorHandlingDeserializer は実際のデシリアライザーに委譲します。エラーが発生した場合は、レコードのキー / 値を null に設定し、メッセージの生のバイトを含めます。次に、ヘッダーに例外を設定し、このレコードをリスナーに渡します。リスナーは、登録されたエラーハンドラーを呼び出します。
必要な構成は次のとおりです。
spring.cloud.stream:
function:
definition: functionName
bindings:
functionName-in-0:
group: group-name
destination: input-topic
consumer:
use-native-decoding: true
kafka:
bindings:
functionName-in-0:
consumer:
enableDlq: true
dlqName: dlq-topic
dlqProducerProperties:
configuration:
value.serializer: org.apache.kafka.common.serialization.StringSerializer
configuration:
value.deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer
spring.deserializer.value.delegate.class: org.apache.kafka.common.serialization.StringDeserializer バインディングの configuration プロパティを介して ErrorHandlingDeserializer を提供しています。また、委譲する実際のデシリアライザーが StringDeserializer であることも示しています。
上記の dlq プロパティは、このレシピの説明には関係がないことに注意してください。これらは、純粋にアプリケーションレベルのエラーに対処することのみを目的としています。
3.4. Kafka バインダーの基本的なオフセット管理
3.4.1. 問題文
Spring Cloud Stream Kafka コンシューマーアプリケーションを作成したいのですが、Kafka コンシューマーオフセットをどのように管理するかがわかりません。説明できますか?
3.4.2. ソリューション
これに関するドキュメントセクションを読んで、完全に理解することをお勧めします。
これが gist です。
Kafka は、デフォルトで 2 種類のオフセット(earliest と latest)をサポートしています。それらのセマンティクスは、それらの名前から自明です。
初めてコンシューマーを実行していると仮定します。Spring Cloud Stream アプリケーションで group.id を見逃すと、匿名のコンシューマーになります。匿名のコンシューマーがある場合は常に、その場合、Spring Cloud Stream アプリケーションは、デフォルトで、トピックパーティションで使用可能な latest オフセットから開始されます。一方、group.id を明示的に指定すると、デフォルトでは、Spring Cloud Stream アプリケーションは、トピックパーティションで使用可能な earliest オフセットから開始されます。
上記の両方の場合(明示的なグループと匿名グループを持つコンシューマー)、開始オフセットは、プロパティ spring.cloud.stream.kafka.bindings.<binding-name>.consumer.startOffset を使用し、earliest または latest のいずれかに設定することで切り替えることができます。
ここで、以前にコンシューマーを実行し、再度開始したと仮定します。この場合、コンシューマーがコンシューマーグループに対してすでにコミットされたオフセットを見つけるため、上記の場合の開始オフセットセマンティクスは適用されません(匿名コンシューマーの場合、アプリケーションは group.id を提供しませんが、バインダーは自動生成)。最後にコミットされたオフセット以降をピックアップするだけです。これは、startOffset 値が提供されている場合でも当てはまります。
ただし、resetOffsets プロパティを使用して、コンシューマーが最後にコミットされたオフセットから開始するデフォルトの動作をオーバーライドできます。これを行うには、プロパティ spring.cloud.stream.kafka.bindings.<binding-name>.consumer.resetOffsets を true (デフォルトでは false)に設定します。次に、startOffset 値(earliest または latest のいずれか)を指定していることを確認してください。これを実行してからコンシューマーアプリケーションを起動すると、起動するたびに、これが初めて起動するかのように起動し、パーティションのコミットされたオフセットを無視します。
3.5. Kafka で任意のオフセットを求めています
3.5.1. 問題文
Kafka バインダーを使用すると、オフセットを earliest または latest のいずれかに設定できることはわかっていますが、オフセットを主要な任意のオフセットにシークする必要があります。Spring Cloud Stream Kafka バイナーを使用してこれを実現する方法はありますか?
3.5.2. ソリューション
以前、Kafka バインダーを使用して基本的なオフセット管理に取り組む方法を見てきました。デフォルトでは、バインダーは、少なくともその reipce で見たメカニズムを介して、任意のオフセットに巻き戻すことを許可しません。ただし、このユースケースを実現するためにバインダーが提供する低レベルの戦略がいくつかあります。調べてみましょう。
まず、earliest または latest 以外の任意のオフセットにリセットする場合は、resetOffsets 構成をデフォルトの false のままにしてください。次に、型 KafkaBindingRebalanceListener のカスタム Bean を提供する必要があります。これは、すべてのコンシューマーバインディングに注入されます。これはいくつかのデフォルトのメソッドが付属しているインターフェースですが、ここに興味を持っているメソッドがあります:
/**
* Invoked when partitions are initially assigned or after a rebalance. Applications
* might only want to perform seek operations on an initial assignment. While the
* 'initial' argument is true for each thread (when concurrency is greater than 1),
* implementations should keep track of exactly which partitions have been sought.
* There is a race in that a rebalance could occur during startup and so a topic/
* partition that has been sought on one thread may be re-assigned to another
* thread and you may not wish to re-seek it at that time.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
* @param initial true if this is the initial assignment on the current thread.
*/
default void onPartitionsAssigned(String bindingName, Consumer<?, ?> consumer,
Collection<TopicPartition> partitions, boolean initial) {
// do nothing
}詳細を見てみましょう。
基本的に、このメソッドは、トピックパーティションの最初の割り当て中、またはリバランス後に毎回呼び出されます。説明をわかりやすくするために、トピックが foo であり、4 つのパーティションがあると仮定します。最初は、グループ内の 1 つのコンシューマーのみを開始し、このコンシューマーはすべてのパーティションから消費します。コンシューマーが初めて起動すると、4 つのパーティションすべてが最初に割り当てられます。ただし、デフォルトで消費するパーティションを開始するのではなく(グループを定義しているため、earliest)、パーティションごとに、任意のオフセットをシークした後に消費するようにします。以下のように、特定のオフセットから消費するビジネスケースがあると想像してください。
Partition start offset
0 1000
1 2000
2 2000
3 1000これは、上記の方法を以下のように実装することで実現できます。
@Override
public void onPartitionsAssigned(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions, boolean initial) {
Map<TopicPartition, Long> topicPartitionOffset = new HashMap<>();
topicPartitionOffset.put(new TopicPartition("foo", 0), 1000L);
topicPartitionOffset.put(new TopicPartition("foo", 1), 2000L);
topicPartitionOffset.put(new TopicPartition("foo", 2), 2000L);
topicPartitionOffset.put(new TopicPartition("foo", 3), 1000L);
if (initial) {
partitions.forEach(tp -> {
if (topicPartitionOffset.containsKey(tp)) {
final Long offset = topicPartitionOffset.get(tp);
try {
consumer.seek(tp, offset);
}
catch (Exception e) {
// Handle excpetions carefully.
}
}
});
}
} これは単なる基本的な実装です。実際のユースケースはこれよりもはるかに複雑であり、それに応じて調整する必要がありますが、これは確かに基本的なスケッチを提供します。コンシューマー seek が失敗すると、いくつかのランタイム例外がスローされる可能性があり、その場合の対処方法を決定する必要があります。
3.5.3. 同じグループ ID で 2 番目のコンシューマーを開始した場合はどうなるでしょうか?
2 番目のコンシューマーを追加すると、リバランスが発生し、一部のパーティションが移動します。新しいコンシューマーがパーティション 2 と 3 を取得するとします。この新しい Spring Cloud Stream コンシューマーがこの onPartitionsAssigned メソッドを呼び出すと、これがこのコンシューマーのパーティション 2 および 3 の最初の割り当てであることがわかります。initial 引数の条件付きチェックのためにシーク操作を実行します。最初のコンシューマーの場合、現在は 0 と 1 のパーティションしかありません。ただし、このコンシューマーの場合、これは単なるリバランスイベントであり、最初の割り当てとは見なされません。initial 引数の条件付きチェックのため、指定されたオフセットを再シークしません。
3.6. Kafka バインダーを使用して手動で確認するにはどうすればよいですか?
3.6.1. 問題文
Kafka バインダーを使用して、コンシューマーのメッセージを手動で確認したい。それ、どうやったら出来るの?
3.6.2. ソリューション
デフォルトでは、Kafka バインダーは Spring for Apache Kafka プロジェクトのデフォルトのコミット設定に委譲します。Spring Kafka のデフォルトの ackMode は batch です。詳細については、こちらを参照してください。
このデフォルトのコミット動作を無効にし、手動コミットに依存したい場合があります。次の手順でそれを行うことができます。
プロパティ spring.cloud.stream.kafka.bindings.<binding-name>.consumer.ackMode を MANUAL または MANUAL_IMMEDIATE のいずれかに設定します。このように設定すると、コンシューマーメソッドが受信するメッセージに kafka_acknowledgment (KafkaHeaders.ACKNOWLEDGMENT から)というヘッダーが存在します。
例: これをコンシューマー向けの方法として想像してください。
@Bean
public Consumer<Message<String>> myConsumer() {
return msg -> {
Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (acknowledgment != null) {
System.out.println("Acknowledgment provided");
acknowledgment.acknowledge();
}
};
} 次に、プロパティ spring.cloud.stream.bindings.myConsumer-in-0.consumer.ackMode を MANUAL または MANUAL_IMMEDIATE に設定します。
3.7. Spring Cloud Stream のデフォルトのバインディング名を上書きするにはどうすればよいですか?
3.7.1. 問題文
Spring Cloud Stream は、関数の定義と署名に基づいてデフォルトのバインディングを作成しますが、これらをよりドメインに適した名前にオーバーライドするにはどうすればよいですか?
3.7.2. ソリューション
以下が関数のシグネチャーであると想定します。
@Bean
public Function<String, String> uppercase(){
...
}デフォルトでは、Spring Cloud Stream は以下のようにバインディングを作成します。
大文字の 0
大文字 -out-0
次のプロパティを使用して、これらのバインディングを何かにオーバーライドできます。
spring.cloud.stream.function.bindings.uppercase-in-0=my-transformer-in
spring.cloud.stream.function.bindings.uppercase-out-0=my-transformer-out この後、すべてのバインディングプロパティは、新しい名前 my-transformer-in および my-transformer-out で作成する必要があります。
これは、Kafka ストリームと複数の入力を使用した別の例です。
@Bean
public BiFunction<KStream<String, Order>, KTable<String, Account>, KStream<String, EnrichedOrder>> processOrder() {
...
}デフォルトでは、Spring Cloud Stream はこの関数に対して 3 つの異なるバインディング名を作成します。
processOrder-in-0
processOrder-in-1
processOrder-out-0
これらのバインディングにいくつかの構成を設定するたびに、これらのバインディング名を使用する必要があります。それが好きではなく、たとえば、のような、よりドメインフレンドリーで読みやすいバインディング名を使用したいと考えています。
オーダー
アカウント
enrichedOrders
これらの 3 つのプロパティを設定するだけで、簡単にそれを行うことができます
spring.cloud.stream.function.bindings.processOrder-in-0= オーダー
spring.cloud.stream.function.bindings.processOrder-in-1= アカウント
spring.cloud.stream.function.bindings.processOrder-out-0=enrichedOrders
これを行うと、デフォルトのバインディング名が上書きされ、それらに設定するプロパティは、これらの新しいバインディング名にある必要があります。
3.8. レコードの一部としてメッセージキーを送信するにはどうすればよいですか?
3.8.1. 問題文
レコードのペイロードと一緒にキーを送信する必要がありますが、Spring Cloud Stream でそれを行う方法はありますか?
3.8.2. ソリューション
多くの場合、キーと値を含むレコードとして、マップのような連想データ構造を送信する必要があります。Spring Cloud Stream を使用すると、簡単な方法でそれを行うことができます。以下は、これを行うための基本的な青写真ですが、特定のユースケースに適合させることをお勧めします。
これがサンプルプロデューサーメソッド(別名 Supplier)です。
@Bean
public Supplier<Message<String>> supplier() {
return () -> MessageBuilder.withPayload("foo").setHeader(KafkaHeaders.MESSAGE_KEY, "my-foo").build();
} これは、String ペイロードだけでなく、キーも使用してメッセージを送信する簡単な関数です。KafkaHeaders.MESSAGE_KEY を使用してキーをメッセージヘッダーとして設定していることに注意してください。
キーをデフォルトの kafka_messageKey から変更する場合は、構成で次のプロパティを指定する必要があります。
spring.cloud.stream.kafka.bindings.supplier-out-0.producer.messageKeyExpression=headers['my-special-key'] バインディング名 supplier-out-0 を使用していることに注意してください。これは関数名であるため、それに応じて更新してください。
次に、メッセージを生成するときにこの新しいキーを使用します。
3.9. Spring Cloud Stream によって行われるメッセージ変換の代わりに、ネイティブシリアライザーとデシリアライザーを使用するにはどうすればよいですか?
3.9.1. 問題文
Spring Cloud Stream でメッセージコンバーターを使用する代わりに、Kafka でネイティブシリアライザーとデシリアライザーを使用したいと思います。デフォルトでは、Spring Cloud Stream は、内部の組み込みメッセージコンバーターを使用してこの変換を処理します。これをバイパスして、Kafka に責任を委譲するにはどうすればよいですか?
3.9.2. ソリューション
これは本当に簡単です。
ネイティブ直列化を有効にするには、次のプロパティを指定するだけです。
spring.cloud.stream.kafka.bindings.<binding-name>.producer.useNativeEncoding: true次に、serailzer も設定する必要があります。これを行うにはいくつかの方法があります。
spring.cloud.stream.kafka.bindings.<binding-name>.producer.configurarion.key.serializer: org.apache.kafka.common.serialization.StringSerializer
spring.cloud.stream.kafka.bindings.<binding-name>.producer.configurarion.value.serializer: org.apache.kafka.common.serialization.StringSerializerまたはバインダー構成を使用します。
spring.cloud.stream.kafka.binder.configurarion.key.serializer: org.apache.kafka.common.serialization.StringSerializer
spring.cloud.stream.kafka.binder.configurarion.value.serializer: org.apache.kafka.common.serialization.StringSerializerバインダー方式を使用する場合、すべてのバインディングに対して適用されますが、バインディングでの設定はバインディングごとに行われます。
デシリアライズ側では、デシリアライザーを構成として提供する必要があります。
以下に例を示します。
spring.cloud.stream.kafka.bindings.<binding-name>.consumer.configurarion.key.deserializer: org.apache.kafka.common.serialization.StringDeserializer
spring.cloud.stream.kafka.bindings.<binding-name>.producer.configurarion.value.deserializer: org.apache.kafka.common.serialization.StringDeserializerバインダーレベルで設定することもできます。
ネイティブデコードを強制するために設定できるオプションのプロパティがあります。
spring.cloud.stream.kafka.bindings.<binding-name>.consumer.useNativeDecoding: trueただし、Kafka バインダーの場合、これは不要です。バインダーに到達するまでに、Kafka は構成済みのデシリアライザーを使用してすでにデシリアライズしているためです。
3.10. Kafka Streams バインダーでオフセットリセットがどのように機能するかを説明します
3.10.1. 問題文
デフォルトでは、Kafka Streams バインダーは、常に新しいコンシューマーの最も早いオフセットから開始します。場合によっては、最新のオフセットから開始することが有益であるか、アプリケーションによって要求されます。Kafka Streams バインダーを使用するとそれが可能になります。
3.10.2. ソリューション
ソリューションを検討する前に、次のシナリオを見てみましょう。
@Bean
public BiConsumer<KStream<Object, Object>, KTable<Object, Object>> myBiConsumer{
(s, t) -> s.join(t, ...)
...
}2 つの入力バインディングを必要とする BiConsumer Bean があります。この場合、最初のバインディングは KStream 用で、2 番目のバインディングは KTable 用です。このアプリケーションを初めて実行するとき、デフォルトでは、両方のバインディングは earliest オフセットから始まります。いくつかの要件のために latest オフセットから始めたいのはどうですか? これを行うには、次のプロパティを有効にします。
spring.cloud.stream.kafka.streams.bindings.myBiConsumer-in-0.consumer.startOffset: latest
spring.cloud.stream.kafka.streams.bindings.myBiConsumer-in-1.consumer.startOffset: latest1 つのバインディングのみを latest オフセットから開始し、もう 1 つをデフォルトの earliest からコンシューマーに開始する場合は、後者のバインディングを構成から除外します。
コミットオフセットが存在したら、これらの設定は光栄とコミットオフセットが優先されていない、ということを覚えておいてください。
3.11. Kafka でのレコードの送信(生成)の成功を追跡する
3.11.1. 問題文
Kafka プロデューサーアプリケーションを持っており、成功したすべてのセディングを追跡したいと思っています。
3.11.2. ソリューション
アプリケーションに次のサプライヤーがあると仮定します。
@Bean
public Supplier<Message<String>> supplier() {
return () -> MessageBuilder.withPayload("foo").setHeader(KafkaHeaders.MESSAGE_KEY, "my-foo").build();
} 次に、成功したすべての送信情報をキャプチャーするために、新しい MessageChannel Bean を定義する必要があります。
@Bean
public MessageChannel fooRecordChannel() {
return new DirectChannel();
} 次に、アプリケーション構成でこのプロパティを定義して、recordMetadataChannel の Bean 名を指定します。
spring.cloud.stream.kafka.bindings.supplier-out-0.producer.recordMetadataChannel: fooRecordChannel この時点で、正常に送信された情報が fooRecordChannel に送信されます。
以下のように IntegrationFlow を記述して、情報を確認できます。
@Bean
public IntegrationFlow integrationFlow() {
return f -> f.channel("fooRecordChannel")
.handle((payload, messageHeaders) -> payload);
}handle メソッドでは、ペイロードは Kafka に送信されたものであり、メッセージヘッダーには kafka_recordMetadata と呼ばれる特別なキーが含まれています。その値は、トピックパーティション、現在のオフセットなどに関する情報を含む RecordMetadata です。
3.12. Kafka にカスタムヘッダーマッパーを追加する
3.12.1. 問題文
いくつかのヘッダーを設定する Kafka プロデューサーアプリケーションがありますが、コンシューマーアプリケーションにありません。何故ですか?
3.12.2. ソリューション
通常の状況では、これで問題ありません。
次のプロデューサーがいると想像してみてください。
@Bean
public Supplier<Message<String>> supply() {
return () -> MessageBuilder.withPayload("foo").setHeader("foo", "bar").build();
}コンシューマー側では、ヘッダー "foo" が表示されるはずですが、以下では課題は発生しません。
@Bean
public Consumer<Message<String>> consume() {
return s -> {
final String foo = (String)s.getHeaders().get("foo");
System.out.println(foo);
};
} アプリケーションでカスタムヘッダーマッパーを提供する場合、これは機能しません。アプリケーションに空の KafkaHeaderMapper があるとしましょう。
@Bean
public KafkaHeaderMapper kafkaBinderHeaderMapper() {
return new KafkaHeaderMapper() {
@Override
public void fromHeaders(MessageHeaders headers, Headers target) {
}
@Override
public void toHeaders(Headers source, Map<String, Object> target) {
}
};
} それが実装である場合、コンシューマーの foo ヘッダーを見逃すことになります。おそらく、これらの KafkaHeaderMapper メソッド内にいくつかのロジックがある可能性があります。foo ヘッダーにデータを入力するには、次のものが必要です。
@Bean
public KafkaHeaderMapper kafkaBinderHeaderMapper() {
return new KafkaHeaderMapper() {
@Override
public void fromHeaders(MessageHeaders headers, Headers target) {
final String foo = (String) headers.get("foo");
target.add("foo", foo.getBytes());
}
@Override
public void toHeaders(Headers source, Map<String, Object> target) {
final Header foo = source.lastHeader("foo");
target.put("foo", new String(foo.value()));
}
} これにより、プロデューサーからコンシューマーに foo ヘッダーが適切に入力されます。
3.12.3. id ヘッダーに関する特記事項
Spring Cloud Stream では、id ヘッダーは特別なヘッダーですが、一部のアプリケーションでは、custom-id、ID、Id などの特別なカスタム ID ヘッダーが必要になる場合があります。最初のもの(custom-id)は、カスタムヘッダーマッパーなしでプロデューサーからコンシューマーに伝播します。ただし、フレームワークで予約されている id ヘッダーのバリアント(ID、Id、iD など)を使用して作成すると、フレームワークの内部で問題が発生します。このユースケースの詳細については、この StackOverflow スレッド (英語) を参照してください。その場合、大文字と小文字を区別する ID ヘッダーをマップするためにカスタム KafkaHeaderMapper を使用する必要があります。例: 次のプロデューサーがいるとします。
@Bean
public Supplier<Message<String>> supply() {
return () -> MessageBuilder.withPayload("foo").setHeader("Id", "my-id").build();
} 上記のヘッダー Id は、フレームワーク id ヘッダーと衝突するため、消費側から削除されます。この課題を解決するために、カスタム KafkaHeaderMapper を提供できます。
@Bean
public KafkaHeaderMapper kafkaBinderHeaderMapper1() {
return new KafkaHeaderMapper() {
@Override
public void fromHeaders(MessageHeaders headers, Headers target) {
final String myId = (String) headers.get("Id");
target.add("Id", myId.getBytes());
}
@Override
public void toHeaders(Headers source, Map<String, Object> target) {
final Header Id = source.lastHeader("Id");
target.put("Id", new String(Id.value()));
}
};
} これにより、id ヘッダーと Id ヘッダーの両方がプロデューサー側からコンシューマー側で使用できるようになります。
3.13. トランザクションで複数のトピックを作成する
3.13.1. 問題文
複数の Kafka トピックへのトランザクションメッセージを生成するにはどうすればよいですか?
詳細については、この StackOverflow の質問 (英語) を参照してください。
3.13.2. ソリューション
トランザクションに Kafka バインダーのトランザクションサポートを使用してから、AfterRollbackProcessor を提供します。複数のトピックを作成するには、StreamBridge API を使用します。
以下は、このためのコードスニペットです。
@Autowired
StreamBridge bridge;
@Bean
Consumer<String> input() {
return str -> {
System.out.println(str);
this.bridge.send("left", str.toUpperCase());
this.bridge.send("right", str.toLowerCase());
if (str.equals("Fail")) {
throw new RuntimeException("test");
}
};
}
@Bean
ListenerContainerCustomizer<AbstractMessageListenerContainer<?, ?>> customizer(BinderFactory binders) {
return (container, dest, group) -> {
ProducerFactory<byte[], byte[]> pf = ((KafkaMessageChannelBinder) binders.getBinder(null,
MessageChannel.class)).getTransactionalProducerFactory();
KafkaTemplate<byte[], byte[]> template = new KafkaTemplate<>(pf);
DefaultAfterRollbackProcessor rollbackProcessor = rollbackProcessor(template);
container.setAfterRollbackProcessor(rollbackProcessor);
};
}
DefaultAfterRollbackProcessor rollbackProcessor(KafkaTemplate<byte[], byte[]> template) {
return new DefaultAfterRollbackProcessor<>(
new DeadLetterPublishingRecoverer(template), new FixedBackOff(2000L, 2L), template, true);
}3.13.3. 必要な構成
spring.cloud.stream.kafka.binder.transaction.transaction-id-prefix: tx-
spring.cloud.stream.kafka.binder.required-acks=all
spring.cloud.stream.bindings.input-in-0.group=foo
spring.cloud.stream.bindings.input-in-0.destination=input
spring.cloud.stream.bindings.left.destination=left
spring.cloud.stream.bindings.right.destination=right
spring.cloud.stream.kafka.bindings.input-in-0.consumer.maxAttempts=1テストするには、次を使用できます。
@Bean
public ApplicationRunner runner(KafkaTemplate<byte[], byte[]> template) {
return args -> {
System.in.read();
template.send("input", "Fail".getBytes());
template.send("input", "Good".getBytes());
};
}いくつかの重要な注意事項:
DLT を手動で構成するため、アプリケーション構成に DLQ 設定がないことを確認してください(デフォルトでは、初期のコンシューマー機能に基づいて input.DLT という名前のトピックに公開されます)。また、バインダーによる再試行を回避するために、1 へのコンシューマーバインディングで maxAttempts をリセットします。上記の例では、最大で合計 3 回試行されます(最初の試行 + FixedBackoff での 2 回の試行)。
このコードをテストする方法の詳細については、StackOverflow スレッド (英語) を参照してください。Spring Cloud Stream を使用して、コンシューマー関数を追加してテストする場合は、コンシューマーバインディングの isolation-level を read-committed に設定してください。
この StackOverflow スレッド (英語) もこの議論に関連しています。
3.14. 複数のポーリング可能なコンシューマーを実行するときに避けるべき落とし穴
3.14.1. 問題文
ポーリング可能なコンシューマーの複数のインスタンスを実行し、インスタンスごとに一意の client.id を生成するにはどうすればよいですか?
3.14.2. ソリューション
次の定義を持っていると仮定します:
spring.cloud.stream.pollable-source: foo
spring.cloud.stream.bindings.foo-in-0.group: my-group アプリケーションを実行すると、Kafka コンシューマーは client.id(consumer-my-group-1 など)を生成します。実行中のアプリケーションのインスタンスごとに、この client.id は同じになり、予期しない問題が発生します。
これを修正するために、アプリケーションの各インスタンスに次のプロパティを追加できます。
spring.cloud.stream.kafka.bindings.foo-in-0.consumer.configuration.client.id=${client.id}詳細については、この GitHub の課題 (英語) を参照してください。
付録
付録 A: ビルド
A.1. 基本的なコンパイルとテスト
ソースをビルドするには、JDK 1.7 をインストールする必要があります。
ビルドでは Maven ラッパーを使用するため、特定のバージョンの Maven をインストールする必要はありません。テストを有効にするには、ビルドする前に Kafka サーバー 0.9 以降を実行しておく必要があります。サーバーの実行の詳細については、以下を参照してください。
主なビルドコマンドは
$ ./mvnw clean install
必要に応じて "-DskipTests" を追加して、テストの実行を回避することもできます。
以下の例では、Maven(> = 3.3.3)を自分でインストールして、./mvnw の代わりに mvn コマンドを実行することもできます。これを行う場合、ローカル Maven 設定に Spring プレリリースアーティファクトのリポジトリ宣言が含まれていない場合は、-P spring も追加する必要があります。 |
-Xmx512m -XX:MaxPermSize=128m のような値で MAVEN_OPTS 環境変数を設定することにより、Maven で使用可能なメモリの量を増やす必要がある場合があることに注意してください。これは .mvn 構成でカバーしようとしているため、ビルドを成功させるためにそれを行う必要がある場合は、チケットを発行して設定をソース管理に追加してください。 |
ミドルウェアを必要とするプロジェクトには通常 docker-compose.yml が含まれているため、Docker Compose (英語) を使用して Docker コンテナーでミドルウェアサーバーを実行することを検討してください。
A.2. ドキュメント
ドキュメントを生成する「完全な」プロファイルがあります。
A.3. コードの操作
IDE の設定がない場合は、コードを操作するときに Spring Tools Suite または Eclipse (英語) を使用することをお勧めします。maven サポートには、m2eclipe (英語) eclipse プラグインを使用します。他の IDE やツールも課題なく動作するはずです。
A.3.1. m2eclipse を使用して Eclipse にインポートする
Eclipse を使用する場合は、m2eclipeeclipse (英語) プラグインをお勧めします。m2eclipse をまだインストールしていない場合は、"eclipsemarketplace" から入手できます。
残念ながら、m2e はまだ Maven 3.3 をサポートしていないため、プロジェクトを Eclipse にインポートしたら、プロジェクトに .settings.xml ファイルを使用するように m2eclipse に指示する必要もあります。これを行わないと、プロジェクトの POM に関連するさまざまなエラーが表示される場合があります。Eclipse 設定を開き、Maven 設定を展開して、ユーザー設定を選択します。ユーザー設定フィールドで、参照をクリックし、インポートした Spring Cloud プロジェクトに移動して、そのプロジェクトの .settings.xml ファイルを選択します。適用、OK の順にクリックして、設定の変更を保存します。
または、リポジトリ設定を .settings.xml [GitHub] (英語) から独自の ~/.m2/settings.xml にコピーすることもできます。 |
A.3.2. m2eclipse なしで Eclipse にインポートする
m2eclipse を使用したくない場合は、次のコマンドを使用して Eclipse プロジェクトのメタデータを生成できます。
$ ./mvnw eclipse:eclipse
生成された日食プロジェクトは、file メニューから import existing projects を選択することでインポートできます。
[[ 貢献 ] == 貢献
Spring Cloud は、制限のない Apache 2.0 ライセンスでリリースされており、課題には Github トラッカーを使用し、プルリクエストをマスターにマージする、非常に標準的な Github 開発プロセスに従っています。些細なことでも貢献したい場合は、遠慮なく以下のガイドラインに従ってください。
A.4. コントリビューターライセンス契約に署名する
重要なパッチまたはプルリクエストを受け入れる前に、コントリビューターの同意書 (英語) に署名する必要があります。コントリビューターの同意書に署名しても、メインリポジトリへのコミット権は誰にも付与されませんが、あなたのコントリビュートを受け入れることができることを意味します。アクティブなコントリビューターは、コアチームに参加するように求められ、プルリクエストをマージする機能が与えられる場合があります。
A.5. コード規約とハウスキーピング
これらはいずれもプルリクエストに必須ではありませんが、すべて役に立ちます。これらは、元のプルリクエストの後、マージの前に追加することもできます。
Spring Framework コード形式の規則を使用してください。Eclipse を使用する場合は、Spring Cloud Build [GitHub] (英語) プロジェクトから
eclipse-code-formatter.xmlファイルを使用してフォーマッター設定をインポートできます。IntelliJ を使用している場合は、Eclipse コードフォーマッタープラグイン (英語) を使用して同じファイルをインポートできます。すべての新しい
.javaファイルに、少なくともあなたを識別する@authorタグ、できればクラスの目的に関する段落を含む単純な Javadoc クラスコメントが含まれていることを確認してください。ASF ライセンスヘッダーコメントをすべての新しい
.javaファイルに追加します (プロジェクト内の既存のファイルからコピーする)大幅に変更する .java ファイルに
@authorとして自分自身を追加します(外観上の変更以上のもの)。いくつかの Javadoc を追加し、名前空間を変更する場合は、いくつかの XSDdoc 要素を追加します。
いくつかの単体テストも大いに役立ちます。誰かがそれをしなければなりません。
他の誰もブランチを使用していない場合は、現在のマスター(またはメインプロジェクトの他のターゲットブランチ)に対してリベースしてください。
コミットメッセージを作成するときは、次の規則 (英語) に従ってください。既存の課題を修正する場合は、コミットメッセージの最後に
Fixes gh-XXXXを追加してください(XXXX は課題番号です)。