4.0.5
序文
Spring のデータ統合への道のりの簡単な歴史
データ統合に関する Spring の旅は、Spring Integration から始まりました。そのプログラミングモデルにより、エンタープライズ統合パターン (英語) を採用して、データベース、メッセージブローカーなどの外部システムに接続できるアプリケーションを構築するための一貫した開発者エクスペリエンスを提供しました。
エンタープライズ環境でマイクロサービスが目立つようになったクラウド時代に早送りします。Spring Boot は、開発者がアプリケーションを構築する方法を変革しました。Spring のプログラミングモデルと Spring Boot によって処理されるランタイムの責任により、スタンドアロンの本番グレードの Spring ベースのマイクロサービスの開発がシームレスになりました。
これをデータ統合ワークロードに拡張するために、Spring Integration と Spring Boot が新しいプロジェクトにまとめられました。Spring Cloud Stream が誕生しました。
Spring Cloud Stream を使用すると、開発者は次のことができます。
データ中心のアプリケーションを個別に構築、テスト、デプロイします。
メッセージングによる構成を含む、最新のマイクロサービスアーキテクチャパターンを適用します。
アプリケーションの責任をイベント中心の考え方から切り離します。イベントは、時間内に発生した何かを表すことができ、ダウンストリームのコンシューマーアプリケーションは、それがどこで発生したか、プロデューサーの ID を知らなくても反応できます。
ビジネスロジックをメッセージブローカー (RabbitMQ、Apache Kafka、Amazon、Kinesis など) に移植します。
一般的なユースケースについては、フレームワークの自動コンテンツ型サポートに依存してください。さまざまなデータ変換型に拡張することが可能です。
などなど . . .
クイックスタート
この 3 ステップのガイドに従うことで、詳細に飛び込む前でも、5 分以内に Spring Cloud Stream を試すことができます。
選択したメッセージングミドルウェアからのメッセージを受信し(これについては後で詳しく説明します)、受信したメッセージをコンソールに記録する Spring Cloud Stream アプリケーションを作成する方法を示します。これを LoggingConsumer と呼びます。あまり実用的ではありませんが、主要な概念と抽象化のいくつかを導入しているため、このユーザーガイドの残りの部分を簡単に理解できます。
3 つのステップは次のとおりです。
Spring Initializr を使用したサンプルアプリケーションの作成
開始するには、Spring Initializr にアクセスしてください。そこから、LoggingConsumer アプリケーションを生成できます。そうするには:
依存関係セクションで、
streamの入力を開始します。「クラウドストリーム」オプションが表示されたら、それを選択します。"kafka" または "rabbit" のいずれかを入力し始めます。
"Kafka" または "RabbitMQ" を選択します。
基本的に、アプリケーションがバインドするメッセージングミドルウェアを選択します。すでにインストールされているものを使用するか、インストールと実行に慣れているものを使用することをお勧めします。また、Initilaizer 画面からわかるように、選択できる他のオプションがいくつかあります。例: Maven(デフォルト)の代わりに、ビルドツールとして Gradle を選択できます。
成果物フィールドに、"logging-consumer" と入力します。
成果物フィールドの値がアプリケーション名になります。ミドルウェアに RabbitMQ を選択した場合、Spring Initializr は次のようになります。

プロジェクトを生成するボタンをクリックします。
そうすることで、生成されたプロジェクトの圧縮バージョンがハードドライブにダウンロードされます。
プロジェクトディレクトリとして使用するフォルダーにファイルを解凍します。
| Spring Initializr で利用可能な多くの可能性を探索することをお勧めします。さまざまな種類の Spring アプリケーションを作成できます。 |
プロジェクトを IDE にインポートする
これで、プロジェクトを IDE にインポートできます。IDE によっては、特定のインポート手順に従う必要がある場合があることに注意してください。例: プロジェクトの生成方法(Maven または Gradle)によっては、特定のインポート手順に従う必要がある場合があります(たとえば、Eclipse または STS では、ファイル→インポート→ Maven →既存の Maven プロジェクトを使用する必要があります)。
インポートしたプロジェクトには、いかなる種類のエラーがあってはなりません。また、src/main/java には com.example.loggingconsumer.LoggingConsumerApplication が含まれている必要があります。
技術的には、この時点で、アプリケーションのメインクラスを実行できます。すでに有効な Spring Boot アプリケーションです。ただし、何も実行されないため、コードを追加します。
メッセージハンドラーの追加、構築、実行
com.example.loggingconsumer.LoggingConsumerApplication クラスを次のように変更します。
@SpringBootApplication
public class LoggingConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingConsumerApplication.class, args);
}
@Bean
public Consumer<Person> log() {
return person -> {
System.out.println("Received: " + person);
};
}
public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}
前のリストからわかるように:
関数型プログラミングモデル(Spring Cloud Function サポートを参照)を使用して、単一のメッセージハンドラーを
Consumerとして定義しています。このようなハンドラーをバインダーによって公開された入力宛先バインディングにバインドするために、フレームワークの規則に依存しています。
そうすることで、フレームワークのコア機能の 1 つを確認することもできます。受信メッセージのペイロードを型 Person に自動的に変換しようとします。
これで、メッセージをリッスンする完全に機能する Spring Cloud Stream アプリケーションができました。ここから、簡単にするために、ステップ 1 で RabbitMQ を選択したと仮定します。RabbitMQ がインストールされて実行されていると仮定すると、IDE で main メソッドを実行することでアプリケーションを起動できます。
次の出力が表示されます。
--- [ main] c.s.b.r.p.RabbitExchangeQueueProvisioner : declaring queue for inbound: input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg, bound to: input
--- [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [localhost:5672]
--- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2a3a299:0/SimpleConnection@66c83fc8. . .
. . .
--- [ main] o.s.i.a.i.AmqpInboundChannelAdapter : started inbound.input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg
. . .
--- [ main] c.e.l.LoggingConsumerApplication : Started LoggingConsumerApplication in 2.531 seconds (JVM running for 2.897)RabbitMQ 管理コンソールまたはその他の RabbitMQ クライアントに移動し、input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg にメッセージを送信します。anonymous.CbMIwdkJSBO1ZoPDOtHtCg 部分はグループ名を表し、生成されるため、環境によって異なるものになるはずです。より予測可能なものについては、spring.cloud.stream.bindings.input.group=hello (または任意の名前)を設定することにより、明示的なグループ名を使用できます。
メッセージの内容は、次のように Person クラスの JSON 表現である必要があります。
{"name":"Sam Spade"}次に、コンソールに次のように表示されます。
Received: Sam Spade
また、アプリケーションをビルドして Boot jar にパッケージ化し(./mvnw clean install を使用)、ビルドされた JAR を java -jar コマンドを使用して実行することもできます。
これで、(非常に基本的ではありますが)Spring Cloud Stream アプリケーションが機能します。
ストリーミングデータのコンテキストでの Spring 式言語(SpEL)
このリファレンスマニュアル全体を通して、Spring 式言語(SpEL)を利用できる多くの機能と例に出会うでしょう。それを使用することになると、特定の制限を理解することが重要です。
SpEL を使用すると、現在のメッセージと実行中のアプリケーションコンテキストにアクセスできます。ただし、特に受信メッセージのコンテキストで SpEL が表示できるデータの種類を理解することが重要です。ブローカーから、メッセージは byte[] の形式で到着します。次に、バインダーによって Message<byte[]> に変換されます。ご覧のとおり、メッセージのペイロードは生の形式を維持しています。メッセージのヘッダーは <String, Object> であり、値は通常、別のプリミティブまたはプリミティブのコレクション / 配列、つまりオブジェクトです。これは、バインダーがユーザーコード(関数)にアクセスできないため、必要な入力型を認識していないためです。そのため、バインダーは、郵便で配達される手紙のように、ペイロードといくつかの読み取り可能なメタデータをメッセージヘッダーの形式で封筒に効果的に配達しました。これは、メッセージのペイロードにアクセスできる間は、生データ(つまり、byte[])としてのみアクセスできることを意味します。また、開発者が具象型(Foo、Bar など)としてペイロードオブジェクトのフィールドに SpEL アクセスできるようにする機能を要求することは非常に一般的ですが、達成するのがどれほど難しいか、不可能でさえあるかがわかります。これは、問題を示す 1 つの例です。ペイロード型に基づいてさまざまな関数にルーティングするルーティング式があるとします。この要件は、byte[] から特定の型へのペイロード変換と、SpEL の適用を意味します。ただし、このような変換を実行するには、コンバーターに渡す実際の型を知る必要があります。これは、どちらがわからない関数のシグネチャーに由来します。この要件を解決するためのより良いアプローチは、型情報をメッセージヘッダー(application/json;type=foo.bar.Baz など)として渡すことです。1 年でアクセスおよび評価でき、SpEL 式が読みやすい、明確で読み取り可能な文字列値を取得します。
さらに、ペイロードは特権データ(最終的な受信者によってのみ読み取られるデータ)であると見なされるため、ルーティングの決定にペイロードを使用することは非常に悪い習慣と見なされます。繰り返しになりますが、郵便配達の例えを使用すると、郵便配達員が封筒を開けて手紙の内容を読んで配達の決定を下すことは望ましくありません。ここでも同じ概念が当てはまります。特に、メッセージを生成するときにそのような情報を含めるのが比較的簡単な場合はそうです。これは、ネットワークを介して送信されるデータの設計に関連する一定レベルの規律を強制し、そのようなデータのどの部分がパブリックと見なされ、どの部分が特権を与えられるかを示します。
Spring Cloud Stream の導入
Spring Cloud Stream は、メッセージ駆動型のマイクロサービスアプリケーションを構築するためのフレームワークです。Spring Cloud Stream は Spring Boot に基づいて構築され、スタンドアロンの本番グレードの Spring アプリケーションを作成し、Spring Integration を使用してメッセージブローカーへの接続を提供します。永続的なパブリッシュ / サブスクライブセマンティクス、コンシューマーグループ、パーティションの概念を導入し、いくつかのベンダーのミドルウェアの独自の構成を提供します。
アプリケーションのクラスパスに spring-cloud-stream 依存関係を追加することにより、提供された spring-cloud-stream バインダーによって公開されるメッセージブローカーへの即時接続を取得し(詳細は後で説明します)、実行される機能要件を実装できます(受信メッセージに基づいて) java.util.function.Function による。
次のリストは簡単な例を示しています。
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
次のリストは、対応するテストを示しています。
@SpringBootTest(classes = SampleApplication.class)
@Import({TestChannelBinderConfiguration.class})
class BootTestStreamApplicationTests {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Test
void contextLoads() {
input.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(output.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
}
主な概念
Spring Cloud Stream は、メッセージ駆動型マイクロサービスアプリケーションの作成を簡素化する多くの抽象化とプリミティブを提供します。このセクションでは、以下の概要を説明します。
アプリケーションモデル
Spring Cloud Stream アプリケーションは、ミドルウェアに依存しないコアで構成されています。アプリケーションは、外部ブローカーによって公開された宛先とコード内の入出力引数との間のバインディングを確立することにより、外部と通信します。バインディングを確立するために必要なブローカー固有の詳細は、ミドルウェア固有のバインダー実装によって処理されます。
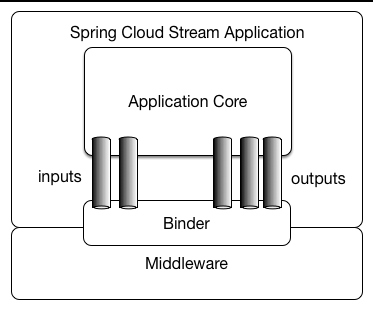
ファット JAR
Spring Cloud Stream アプリケーションは、テストのために IDE からスタンドアロンモードで実行できます。本番環境で Spring Cloud Stream アプリケーションを実行するには、Maven または Gradle 用に提供されている標準の Spring Boot ツールを使用して、実行可能(または「ファット」)JAR を作成できます。詳細については、Spring Boot リファレンスガイドを参照してください。
バインダーの抽象化
Spring Cloud Stream は、Kafka [GitHub] (英語) および Rabbit MQ [GitHub] (英語) のバインダー実装を提供します。フレームワークには、spring-cloud-stream アプリケーションとしてのアプリケーションの統合テスト用のテストバインダーも含まれています。詳細については、テストセクションを参照してください。
バインダーの抽象化もフレームワークの拡張ポイントの 1 つです。つまり、Spring Cloud Stream の上に独自のバインダーを実装できます。Spring Cloud Stream バインダーを最初から作成する方法 (英語) で、コミュニティメンバーのドキュメントを詳細に投稿します。例として、カスタムバインダーを実装するために必要な一連の手順を示します。手順は、Implementing Custom Binders セクションでも強調表示されています。
Spring Cloud Stream は構成に Spring Boot を使用し、バインダーの抽象化により、Spring Cloud Stream アプリケーションがミドルウェアに接続する方法に柔軟性を持たせることができます。例: デプロイヤーは、実行時に、外部宛先(Kafka トピックや RabbitMQ 交換など)とメッセージハンドラーの入力および出力(関数の入力パラメーターやその戻り引数など)の間のマッピングを動的に選択できます。このような構成は、外部構成プロパティを介して、Spring Boot でサポートされている任意の形式(アプリケーション引数、環境変数、application.yml または application.properties ファイルを含む)で提供できます。Spring Cloud Stream の導入セクションのシンクの例では、spring.cloud.stream.bindings.input.destination アプリケーションプロパティを raw-sensor-data に設定すると、raw-sensor-data Kafka トピックまたは raw-sensor-data RabbitMQ 交換にバインドされたキューから読み取られます。
Spring Cloud Stream は、クラスパスで見つかったバインダーを自動的に検出して使用します。同じコードでさまざまな型のミドルウェアを使用できます。これを行うには、ビルド時に別のバインダーを含めます。より複雑なユースケースの場合は、アプリケーションに複数のバインダーをパッケージ化して、実行時にバインダーを選択させることもできます(さらに、異なるバインディングに異なるバインダーを使用するかどうかも)。
永続的なパブリッシュ / サブスクライブのサポート
アプリケーション間の通信は、データが共有トピックを通じてブロードキャストされるパブリッシュ / サブスクライブモデルに従います。これは、相互作用する Spring Cloud Stream アプリケーションのセットの典型的なデプロイを示す次の図で確認できます。

センサーによって HTTP エンドポイントに報告されたデータは、raw-sensor-data という名前の共通の宛先に送信されます。宛先からは、時間枠の平均を計算するマイクロサービスアプリケーションと、生データを HDFS(Hadoop 分散ファイルシステム)に取り込む別のマイクロサービスアプリケーションによって個別に処理されます。データを処理するために、両方のアプリケーションは実行時にトピックを入力として宣言します。
パブリッシュ / サブスクライブ通信モデルは、プロデューサーとコンシューマーの両方の複雑さを軽減し、既存のフローを中断することなく、新しいアプリケーションをトポロジーに追加できるようにします。例: 平均計算アプリケーションの下流に、表示と監視のために最高温度値を計算するアプリケーションを追加できます。次に、障害検出のために同じ平均フローを解釈する別のアプリケーションを追加できます。ポイントツーポイントキューではなく共有トピックを介してすべての通信を行うと、マイクロサービス間の結合が減少します。
パブリッシュ / サブスクライブメッセージングの概念は新しいものではありませんが、Spring Cloud Stream は、アプリケーションモデルに対して柔軟な選択肢にするという追加のステップを踏んでいます。ネイティブミドルウェアサポートを使用することにより、Spring Cloud Stream は、さまざまなプラットフォーム間でのパブリッシュ / サブスクライブモデルの使用も簡素化します。
コンシューマーグループ
パブリッシュ / サブスクライブモデルを使用すると、共有トピックを介してアプリケーションを簡単に接続できますが、特定のアプリケーションの複数のインスタンスを作成してスケールアップする機能も同様に重要です。そうすると、アプリケーションのさまざまなインスタンスが競合するコンシューマー関連に配置され、インスタンスの 1 つだけが特定のメッセージを処理することが期待されます。
Spring Cloud Stream は、コンシューマーグループの概念を通じてこの動作をモデル化します。(Spring Cloud Stream コンシューマーグループは、Kafka コンシューマーグループに類似しており、それに触発されています)各コンシューマーバインディングは、spring.cloud.stream.bindings.<bindingName>.group プロパティを使用してグループ名を指定できます。次の図に示すコンシューマーの場合、このプロパティは spring.cloud.stream.bindings.<bindingName>.group=hdfsWrite または spring.cloud.stream.bindings.<bindingName>.group=average として設定されます。
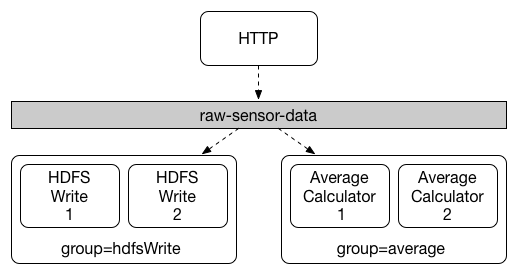
特定の宛先にサブスクライブするすべてのグループは、公開されたデータのコピーを受け取りますが、各グループの 1 人のメンバーだけがその宛先から特定のメッセージを受け取ります。デフォルトでは、グループが指定されていない場合、Spring Cloud Stream は、他のすべてのコンシューマーグループとパブリッシュ / サブスクライブ関連にある匿名の独立した単一メンバーのコンシューマーグループにアプリケーションを割り当てます。
コンシューマー型
2 種類のコンシューマーがサポートされています。
メッセージ主導 (非同期と呼ばれることもあります)
ポーリング (同期と呼ばれることもあります)
バージョン 2.0 より前は、非同期コンシューマーのみがサポートされていました。メッセージが利用可能になり、スレッドがそれを処理できるようになるとすぐにメッセージが配信されます。
メッセージが処理される速度を制御したい場合は、同期コンシューマーを使用することをお勧めします。
耐久性
Spring Cloud Stream の独創的なアプリケーションモデルと一致して、コンシューマーグループのサブスクリプションは永続的です。つまり、バインダーの実装により、グループサブスクリプションが永続的であり、グループのサブスクリプションが少なくとも 1 つ作成されると、グループ内のすべてのアプリケーションが停止しているときにメッセージが送信された場合でも、グループはメッセージを受信します。
匿名のサブスクリプションは、本質的に永続的ではありません。一部のバインダー実装(RabbitMQ など)では、永続的でないグループサブスクリプションを持つことができます。 |
一般に、アプリケーションを特定の宛先にバインドするときは、常にコンシューマーグループを指定することをお勧めします。Spring Cloud Stream アプリケーションをスケールアップするときは、入力バインディングごとにコンシューマーグループを指定する必要があります。そうすることで、アプリケーションのインスタンスが重複メッセージを受信するのを防ぎます(その動作が望まれる場合を除きます。これは異常です)。
パーティショニングのサポート
Spring Cloud Stream は、特定のアプリケーションの複数のインスタンス間でデータを分割するためのサポートを提供します。パーティション化されたシナリオでは、物理通信メディア(ブローカートピックなど)は、複数のパーティションに構造化されていると見なされます。1 つ以上のプロデューサーアプリケーションインスタンスが複数のコンシューマーアプリケーションインスタンスにデータを送信し、共通の特性によって識別されるデータが同じコンシューマーインスタンスによって処理されるようにします。
Spring Cloud Stream は、パーティション化された処理のユースケースを統一された方法で実装するための一般的な抽象化を提供します。パーティション化は、ブローカー自体が自然にパーティション化されているかどうか(たとえば、Kafka)またはそうでないか(たとえば、RabbitMQ)に使用できます。

パーティショニングはステートフル処理の重要な概念であり、関連するすべてのデータが一緒に処理されるようにすることが(パフォーマンスまたは一貫性の理由から)重要です。例: 時間枠平均計算の例では、特定のセンサーからのすべての測定値が同じアプリケーションインスタンスによって処理されることが重要です。
| パーティション処理シナリオを設定するには、データ生成側とデータ消費側の両方を構成する必要があります。 |
プログラミングモデル
プログラミングモデルを理解するには、次のコアコンセプトに精通している必要があります。
宛先バインダー : 外部メッセージングシステムとの統合を提供するコンポーネント。
バインディング : 外部メッセージングシステムとアプリケーションが提供するメッセージのプロデューサーとコンシューマー(宛先バインダーによって作成される)の間のブリッジ。
メッセージ : プロデューサーとコンシューマーが宛先バインダー(したがって、外部メッセージングシステムを介した他のアプリケーション)と通信するために使用する標準的なデータ構造。

宛先バインダー
宛先バインダーは Spring Cloud Stream の拡張コンポーネントであり、外部メッセージングシステムとの統合を容易にするために必要な構成と実装を提供します。この統合は、プロデューサーとコンシューマーとの間のメッセージの接続、委譲、ルーティング、データ型の変換、ユーザーコードの呼び出しなどを担当します。
バインダーは、そうでなければあなたの肩にかかるであろうボイラープレートの多くの責任を処理します。ただし、それを実現するために、バインダーには、ユーザーからの最小限でありながら必要な一連の指示の形での支援が必要です。これは通常、何らかの種類のバインディング構成の形で提供されます。
使用可能なすべてのバインダーおよびバインディング構成オプションについて説明することはこのセクションの範囲外ですが(マニュアルの残りの部分ではそれらを広範囲にカバーしています)、概念としてのバインディングには特別な注意が必要です。次のセクションでは、それについて詳しく説明します。
バインディング
前述のように、バインディングは、外部メッセージングシステム(キュー、トピックなど)とアプリケーションが提供するプロデューサーおよびコンシューマーの間のブリッジを提供します。
次の例は、メッセージのペイロードを String 型(コンテンツ型の交渉セクションを参照)として受信し、コンソールに記録し、大文字に変換した後にダウンストリームに送信する、完全に構成され機能している Spring Cloud Stream アプリケーションを示しています。
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> {
System.out.println("Received: " + value);
return value.toUpperCase();
};
}
}
上記の例は、通常の spring-boot アプリケーションと何ら変わりはありません。型 Function の単一の Bean を定義し、それだけです。では、どのようにして spring-cloud-stream アプリケーションになるのでしょうか ? クラスパス上に spring-cloud-stream とバインダーの依存関係と自動構成クラスが存在するという単純な理由で、spring-cloud-stream アプリケーションになり、Boot アプリケーションのコンテキストを spring-cloud-stream アプリケーションとして効果的に設定します。また、このコンテキストでは、型 Supplier、Function または Consumer の Bean は、追加の構成を避けるために、特定の命名規則と規則に従って、提供されたバインダーによって公開された宛先へのバインドをトリガーする事実上のメッセージハンドラーとして扱われます。
バインディングとバインディング名
バインディングは、バインダーとユーザーコードによって公開されるソースとターゲット間のブリッジを表す抽象化です。この抽象化には名前があり、spring-cloud-stream アプリケーションの実行に必要な構成を制限するために最善を尽くしますが、そのような名前を認識しています。追加のバインディングごとの構成が必要な場合に必要です。
このマニュアル全体を通して、spring.cloud.stream.bindings.input.destination=myQueue などの構成プロパティの例が表示されます。このプロパティ名の input セグメントは、バインディング名と呼ばれるものであり、いくつかのメカニズムを介して派生する可能性があります。次のサブセクションでは、spring-cloud-stream がバインディング名を制御するために使用する命名規則と構成要素について説明します。
バインディング名に . 文字などの特殊文字が含まれている場合は、バインディングキーを 括弧 ([]) で囲み、引用符で囲む必要があります。たとえば、spring.cloud.stream.bindings."[my.output.binding.key]".destination。 |
機能バインディング名
以前のバージョンの spring-cloud-stream で使用されていたアノテーションベースのサポート(レガシー)で必要とされる明示的な命名とは異なり、関数型プログラミングモデルは、名前のバインドに関してはデフォルトで単純な規則になっているため、アプリケーション構成が大幅に簡素化されます。最初の例を見てみましょう。
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
前の例では、メッセージハンドラーとして機能する単一の関数を持つアプリケーションがあります。Function として、入力と出力があります。入力バインディングと出力バインディングに名前を付けるために使用される命名規則は次のとおりです。
入力 -
<functionName> + -in- + <index>出力 -
<functionName> + -out- + <index>
in および out は、バインディングの型(入力や出力など)に対応します。index は、入力または出力バインディングのインデックスです。通常の単一入出力機能では常に 0 であるため、複数の入力引数と出力引数を持つ関数にのみ関連します。
たとえば、この関数の入力を "my-topic" と呼ばれるリモート宛先(トピック、キューなど)にマップする場合は、次のプロパティを使用します。
--spring.cloud.stream.bindings.uppercase-in-0.destination=my-topic
uppercase-in-0 がプロパティ名のセグメントとしてどのように使用されているかに注意してください。同じことが uppercase-out-0 にも当てはまります。
わかりやすいバインディング名
読みやすさを向上させるために、バインディングにさらにわかりやすい名前 (「アカウント」、「オーダー」など) を付けたい場合があります。別の見方としては、暗黙的なバインディング名を 明示的なバインディング名にマップできるということです。spring.cloud.stream.function.bindings.<binding-name> プロパティを使用してそれを行うことができます。このプロパティは、明示的な名前を必要とするカスタムインターフェースベースのバインディングに依存する既存のアプリケーションの移行パスも提供します。
以下に例を示します。
--spring.cloud.stream.function.bindings.uppercase-in-0=input
前の例では、uppercase-in-0 バインディング名を input にマップし、効果的に名前を変更しました。これで、すべての構成プロパティが代わりに input バインディング名を参照できるようになりました(例: --spring.cloud.stream.bindings.input.destination=my-topic)。
説明的なバインディング名は設定の可読性を高めるかもしれませんが、暗黙のバインディング名を明示的なバインディング名に対応させることで、別のレベルのミスディレクションを生み出すことにもなります。また、それ以降のすべての構成プロパティは明示的なバインディング名を使用するため、実際にどの関数に対応しているかを関連付けるために、常にこの "bindings" プロパティを参照する必要があります。特に、spring.cloud.stream.bindings.uppercase-in-0.destination=sample-topic のように、uppercase 関数の入力と sample-topic の出力が明確に関連付けられ、バインダーの出力先とバインディング名の間に明確なパスができる場合(関数構成を除く)は、このプロパティを使用しないことをお勧めします。 |
プロパティおよびその他の構成オプションの詳細については、構成オプションセクションを参照してください。
明示的なバインディングの作成
前のセクションでは、アプリケーションによって提供される Function、Supplier、または Consumer Bean の名前によって暗黙的に駆動されるバインディングがどのように作成されるかを説明しました。ただし、バインディングがどの関数にも関連付けられていない場合に、バインディングを明示的に作成する必要がある場合があります。これは通常、StreamBridge を介して他のフレームワークとの統合をサポートするために行われます。
Spring Cloud Stream を使用すると、spring.cloud.stream.input-bindings および spring.cloud.stream.output-bindings プロパティを介して入力および出力バインディングを明示的に定義できます。プロパティ名の複数形により、; を区切り文字として使用するだけで複数のバインディングを定義できることに気づきました。例として、次のテストケースを参照してください。
@Test
public void testExplicitBindings() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(EmptyConfiguration.class))
.web(WebApplicationType.NONE)
.run("--spring.jmx.enabled=false",
"--spring.cloud.stream.input-bindings=fooin;barin",
"--spring.cloud.stream.output-bindings=fooout;barout")) {
. . .
}
}
@EnableAutoConfiguration
@Configuration
public static class EmptyConfiguration {
}ご覧のとおり、構成に関数が定義されていないときに 2 つの入力バインディングと 2 つの出力バインディングを宣言しましたが、これらのバインディングを正常に作成し、対応するチャネルにアクセスすることができました。
メッセージの生成と消費
関数を記述して @Bean として公開するだけで、Spring Cloud Stream アプリケーションを記述できます。Spring Integration アノテーションベースの構成または Spring Cloud Stream アノテーションベースの構成を使用することもできますが、spring-cloud-stream 3.x 以降では、関数実装を使用することをお勧めします。
Spring Cloud Function サポート
概要
Spring Cloud Stream v2.1 以降、ストリームハンドラーとソースを定義するための別の方法は、java.util.function.[Supplier/Function/Consumer] 型の Bean として表現できる Spring Cloud Function (英語) の組み込みサポートを使用することです。
バインディングによって公開される外部宛先にバインドする関数 Bean を指定するには、spring.cloud.function.definition プロパティを指定する必要があります。
型 java.util.function.[Supplier/Function/Consumer] の Bean が 1 つしかない場合は、関数 Bean が自動検出されるため、spring.cloud.function.definition プロパティをスキップできます。ただし、混乱を避けるために、このようなプロパティを使用することをお勧めします。型 java.util.function.[Supplier/Function/Consumer] の単一の Bean は、メッセージの処理以外の目的で存在する可能性があるため、この自動検出が邪魔になる場合がありますが、単一であると自動検出され、自動バインドされます。これらのまれなシナリオでは、false に設定された値を spring.cloud.stream.function.autodetect プロパティに提供することにより、自動検出を無効にすることができます。 |
これは、メッセージハンドラーを java.util.function.Function として公開するアプリケーションの例であり、データのコンシューマーおよびプロデューサーとして機能することにより、パススルーセマンティクスを効果的にサポートします。
@SpringBootApplication
public class MyFunctionBootApp {
public static void main(String[] args) {
SpringApplication.run(MyFunctionBootApp.class);
}
@Bean
public Function<String, String> toUpperCase() {
return s -> s.toUpperCase();
}
}
前の例では、toUpperCase と呼ばれる型 java.util.function.Function の Bean を定義して、指定された宛先バインダーによって公開される外部宛先に 'input' と 'output' をバインドする必要があるメッセージハンドラーとして動作させます。デフォルトでは、'input' と 'output' のバインディング名は toUpperCase-in-0 と toUpperCase-out-0 になります。バインディング名を確立するために使用される命名規則の詳細については、機能バインディング名セクションを参照してください。
以下は、他のセマンティクスをサポートするための単純な関数アプリケーションの例です。
これは、java.util.function.Supplier として公開されているソースセマンティクスの例です。
@SpringBootApplication
public static class SourceFromSupplier {
@Bean
public Supplier<Date> date() {
return () -> new Date(12345L);
}
}
これは、java.util.function.Consumer として公開されているシンクセマンティクスの例です。
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Consumer<String> sink() {
return System.out::println;
}
}
サプライヤー (ソース)
Function と Consumer は、呼び出しがどのようにトリガーされるかに関しては非常に簡単です。それらは、バインドされている宛先に送信されたデータ(イベント)に基づいてトリガーされます。言い換えれば、それらは典型的なイベント駆動型コンポーネントです。
ただし、トリガーに関しては、Supplier は独自のカテゴリにあります。定義上、データのソース(発信元)であるため、受信の宛先にサブスクライブせず、他のメカニズムによってトリガーされる必要があります。Supplier の実装についても問題があります。これは、必須またはリアクティブ的であり、そのようなサプライヤーのトリガーに直接関係します。
次のサンプルについて考えてみます。
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<String> stringSupplier() {
return () -> "Hello from Supplier";
}
}
上記の Supplier Bean は、get() メソッドが呼び出されるたびに文字列を生成します。ただし、このメソッドを呼び出すのは誰で、どのくらいの頻度ですか? フレームワークは、サプライヤーの呼び出しをトリガーするデフォルトのポーリングメカニズム(「誰?」の質問に答える)を提供し、デフォルトでは毎秒(「どのくらいの頻度で?」の質問に答える)をトリガーします。言い換えると、上記の構成では、毎秒 1 つのメッセージが生成され、各メッセージは、バインダーによって公開される output 宛先に送信されます。ポーリングメカニズムをカスタマイズする方法については、ポーリング構成プロパティセクションを参照してください。
別の例を考えてみましょう。
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.fromStream(Stream.generate(new Supplier<String>() {
@Override
public String get() {
try {
Thread.sleep(1000);
return "Hello from Supplier";
} catch (Exception e) {
// ignore
}
}
})).subscribeOn(Schedulers.elastic()).share();
}
}
前述の Supplier Bean は、リアクティブプログラミングスタイルを採用しています。通常、命令型サプライヤーとは異なり、get() メソッドの呼び出しにより、個々のメッセージではなくメッセージの連続ストリームが生成(サプライ)されるため、トリガーは 1 回だけにする必要があります。
フレームワークはプログラミングスタイルの違いを認識し、そのようなサプライヤーが 1 回だけトリガーされることを保証します。
ただし、あるデータソースをポーリングして、結果セットを表すデータの有限ストリームを返したいユースケースを想像してみてください。リアクティブプログラミングスタイルは、そのようなサプライヤーにとって完璧なメカニズムです。ただし、生成されるストリームの性質が有限であるため、このようなサプライヤーは定期的に呼び出す必要があります。
有限のデータストリームを生成することでこのようなユースケースをエミュレートする次のサンプルについて考えてみます。
@SpringBootApplication
public static class SupplierConfiguration {
@PollableBean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.just("hello", "bye");
}
}
Bean 自体は PollableBean アノテーション(@Bean のサブセット)でアノテーションが付けられているため、このようなサプライヤーの実装はリアクティブですが、ポーリングする必要があることをフレームワークに通知します。
PollableBean には、このアノテーションのポストプロセッサーに、アノテーション付きコンポーネントによって生成された結果を分割する必要があることを通知する splittable 属性が定義されており、デフォルトでは true に設定されています。つまり、フレームワークは、返される各項目を個別のメッセージとして送信して分割します。この動作が望ましくない場合は、false に設定できます。その場合、このようなサプライヤーは、生成された Flux を分割せずにそのまま返します。 |
サプライヤーとスレッド
これまでに学習したように、イベントによってトリガーされる Function や Consumer とは異なり(入力データがあります)、Supplier には入力がないため、別のメカニズムであるポーラーによってトリガーされます。ポーラーは、予測できないスレッドメカニズムを持っている可能性があります。また、ほとんどの場合、スレッドメカニズムの詳細は関数のダウンストリーム実行とは関係ありませんが、特定の場合、特にスレッドの親和性に一定の期待がある統合フレームワークでは問題が発生する可能性があります。例: スレッドローカルに格納されているトレースデータに依存する Spring Cloud Sleuth。このような場合、StreamBridge を介した別のメカニズムがあり、ユーザーはスレッドメカニズムをより細かく制御できます。詳細については、任意のデータを出力に送信する (たとえば外国のイベント駆動型ソース) セクションを参照してください。 |
コンシューマー (リアクティブ)
リアクティブ Consumer は、戻り値の型が void であり、サブスクライブする参照がないフレームワークを残すため、少し特別です。ほとんどの場合、Consumer<Flux<?>> を記述する必要はなく、代わりに、ストリームの最後の演算子として then 演算子を呼び出す Function<Flux<?>, Mono<Void>> として記述します。
例:
public Function<Flux<?>, Mono<Void>> consumer() {
return flux -> flux.map(..).filter(..).then();
}
ただし、明示的に Consumer<Flux<?>> を記述する必要がある場合は、受信 Flux をサブスクライブすることを忘れないでください。
また、リアクティブ関数と命令関数を混合する場合、関数の合成にも同じルールが適用されることに注意してください。Spring Cloud Function は確かに命令型のリアクティブ関数の作成をサポートしていますが、特定の制限に注意する必要があります。例: 命令型のコンシューマーとリアクティブ関数を構成したと仮定します。そのような組成の結果は、リアクティブ Consumer です。ただし、このセクションで前述したようなコンシューマーをサブスクライブする方法はないため、この制限に対処するには、コンシューマーをリアクティブにして手動でサブスクライブするか(前述のように)、機能を必須に変更する必要があります。
ポーリング構成プロパティ
次のプロパティは Spring Cloud Stream によって公開され、接頭辞 spring.integration.poller. が付けられます。
- fixedDelay
デフォルトのポーラーの遅延をミリ秒単位で修正しました。
デフォルト: 1000L.
- maxMessagesPerPoll
デフォルトのポーラーの各ポーリングイベントの最大メッセージ。
デフォルト: 1L.
- cron
cron トリガーの cron 式の値。
デフォルト: なし。
- initialDelay
定期的なトリガーの初期遅延。
デフォルト: 0.
- timeUnit
遅延値に適用する TimeUnit。
デフォルト: MILLISECONDS.
たとえば、--spring.integration.poller.fixed-delay=2000 は、2 秒ごとにポーリングするようにポーラー間隔を設定します。
バインディングごとのポーリング構成
前のセクションでは、すべてのバインディングに適用される単一のデフォルトポーラーを構成する方法を示しました。各マイクロサービスが単一のコンポーネント(サプライヤーなど)を表すように設計されたマイクロサービス spring-cloud-stream のモデルにうまく適合しているため、デフォルトのポーラー構成で十分ですが、異なるポーリング構成を必要とする複数のコンポーネントがある場合があります。
このような場合は、バインディングごとの方法でポーラーを構成してください。例: supply-out-0 をバインドする出力があると仮定します。この場合、spring.cloud.stream.bindings.supply-out-0.producer.poller.. プレフィックス(spring.cloud.stream.bindings.supply-out-0.producer.poller.fixed-delay=2000 など)を使用して、このようなバインディング用にポーラーを構成できます。
任意のデータを出力に送信する (たとえば外国のイベント駆動型ソース)
実際のデータソースは、バインダーではない外部(外部)システムからのものである場合があります。例: データのソースは、従来の REST エンドポイントである可能性があります。このようなソースを spring-cloud-stream で使用される機能メカニズムとどのように橋渡ししますか?
Spring Cloud Stream には 2 つのメカニズムがあるため、それらについて詳しく見ていきましょう。
ここでは、両方のサンプルで、ルート Web コンテキストにバインドされた delegateToSupplier と呼ばれる標準の MVC エンドポイントメソッドを使用し、受信リクエストを StreamBridge メカニズムを介してストリーミングに委譲します。
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, "--spring.cloud.stream.output-bindings=toStream");
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("toStream", body);
}
}
ここでは、StreamBridge Bean をオートワイヤーします。これにより、データを出力バインディングに送信して、非ストリームアプリケーションと spring-cloud-stream を効果的にブリッジできます。上記の例では、ソース関数が定義されていないことに注意してください(Supplier Bean など)。フレームワークには、事前にソースバインディングを作成するトリガーがありません。これは、構成に関数 Bean が含まれている場合に一般的です。StreamBridge は、send(..) 操作への最初の呼び出しで存在しないバインディングの出力バインディングの作成(および必要に応じて宛先の自動プロビジョニング)を開始し、その後の再利用のためにそれをキャッシュするため、これは問題ありません(詳細については StreamBridge と動的宛先を参照)。
ただし、初期化 (起動) 時に出力バインディングを事前に作成したい場合は、ソースの名前を宣言できる spring.cloud.stream.output-bindings プロパティを利用すると便利です。指定された名前は、ソースバインディングを作成するトリガーとして使用されます。; を使用して複数のソースを示すことができます (複数の出力バインディング) (例: --spring.cloud.stream.output-bindings=foo;bar)
また、streamBridge.send(..) メソッドはデータに Object を使用することに注意してください。つまり、POJO または Message を送信でき、出力を送信するときに、関数と同じレベルの一貫性を提供する関数またはサプライヤーからのものであるかのように、同じルーチンを実行します。これは、出力型の変換、パーティショニングなどが、関数によって生成された出力からのものであるかのように尊重されることを意味します。
StreamBridge と動的宛先
StreamBridge は、FROM コンシューマーのルーティングのセクションで説明されている使用例と同様に、出力先が事前にわからない場合にも使用できます。
例を見てみましょう
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, args);
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("myDestination", body);
}
}
ご覧のとおり、前の例は、spring.cloud.stream.output-bindings プロパティ(提供されていない)を介して提供される明示的なバインディング命令を除いて、前の例と非常に似ています。ここでは、バインディングとして存在しない myDestination 名にデータを送信しています。そのような名前は、FROM コンシューマーのルーティングセクションに従って動的宛先として扱われます。
前の例では、ストリームをフィードするための外部ソースとして ApplicationRunner を使用しています。
より実用的な例では、外部ソースが REST エンドポイントです。
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class);
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
streamBridge.send("myBinding", body);
}
}
delegateToSupplier メソッドの内部を見るとわかるように、StreamBridge を使用して myBinding バインディングにデータを送信しています。また、ここでは StreamBridge の動的機能の恩恵を受けており、myBinding が存在しない場合は自動的に作成されてキャッシュされ、そうでない場合は既存のバインディングが使用されます。
動的な宛先(バインディング)をキャッシュすると、動的な宛先が多数ある場合にメモリリークが発生する機能があります。ある程度の制御を行うために、デフォルトのキャッシュサイズが 10 の出力バインディングに自己排除キャッシュメカニズムを提供します。これは、動的宛先サイズがその数を超えると、既存のバインディングが排除される可能性があることを意味します。再作成する必要があり、パフォーマンスがわずかに低下する機能があります。spring.cloud.stream.dynamic-destination-cache-size プロパティを使用してキャッシュサイズを増やし、目的の値に設定できます。 |
curl -H "Content-Type: text/plain" -X POST -d "hello from the other side" http://localhost:8080/
2 つの例を示すことにより、このアプローチがあらゆる型の外国の情報源で機能することを強調したいと思います。
Solace PubSub+ バインダーを使用している場合、Spring Cloud Stream は scst_targetDestination ヘッダー (BinderHeaders.TARGET_DESTINATION 経由で取得可能) を予約しています。これにより、バインディングの構成された宛先からこのヘッダーで指定されたターゲット宛先にメッセージをリダイレクトできます。これにより、バインダーは動的宛先に発行するために必要なリソースを管理できるようになり、フレームワークによる管理の必要性が軽減され、前のメモで説明したキャッシュの課題が回避されます。詳細については、こちらを参照してください [GitHub] (英語) 。 |
StreamBridge を使用した出力コンテンツ型
必要に応じて、次のメソッドシグネチャー public boolean send(String bindingName, Object data, MimeType outputContentType) を使用して特定のコンテンツ型を提供することもできます。または、Message としてデータを送信する場合、そのコンテンツ型が尊重されます。
StreamBridge で特定のバインダー型を使用する
Spring Cloud Stream は、複数のバインダーシナリオをサポートします。たとえば、Kafka からデータを受信し、それを RabbitMQ に送信している場合があります。
複数のバインダーのシナリオの詳細については、バインダーセクション、特にクラスパス上の複数のバインダーを参照してください。
StreamBridge の使用を計画していて、アプリケーションで複数のバインダーを構成している場合は、使用するバインダーも StreamBridge に指示する必要があります。そのために、send メソッドにはさらに 2 つのバリエーションがあります。
public boolean send(String bindingName, @Nullable String binderType, Object data)
public boolean send(String bindingName, @Nullable String binderType, Object data, MimeType outputContentType)
ご覧のとおり、提供できる追加の引数が 1 つあります。binderType は、動的バインディングを作成するときに使用するバインダーを BindingService に指示します。
spring.cloud.stream.output-bindings プロパティが使用されている場合、またはバインディングが別のバインダーですでに作成されている場合、binderType 引数は効果がありません。 |
StreamBridge でのチャネルインターセプターの使用
StreamBridge は MessageChannel を使用して出力バインディングを確立するため、StreamBridge を介してデータを送信するときにチャネルインターセプターをアクティブ化できます。StreamBridge に適用するチャネルインターセプターを決定するのはアプリケーション次第です。Spring Cloud Stream は、@GlobalChannelInterceptor(patterns = "*") で通知されない限り、検出されたすべてのチャネルインターセプターを StreamBridge に注入するわけではありません。
アプリケーションに次の 2 つの異なる StreamBridge バインディングがあると仮定します。
streamBridge.send("foo-out-0", message);
および
streamBridge.send("bar-out-0", message);
ここで、両方の StreamBridge バインディングにチャネルインターセプターを適用する場合は、次の GlobalChannelInterceptor Bean を宣言できます。
@Bean
@GlobalChannelInterceptor(patterns = "*")
public ChannelInterceptor customInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}ただし、上記のグローバルアプローチが気に入らず、バインディングごとに専用のインターセプターが必要な場合は、次のようにすることができます。
@Bean
@GlobalChannelInterceptor(patterns = "foo-*")
public ChannelInterceptor fooInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}および
@Bean
@GlobalChannelInterceptor(patterns = "bar-*")
public ChannelInterceptor barInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}パターンをより厳密にしたり、ビジネスニーズに合わせてカスタマイズしたりする柔軟性があります。
このアプローチにより、アプリケーションは、使用可能なすべてのインターセプターを適用するのではなく、StreamBridge に注入するインターセプターを決定することができます。
StreamBridge は、StreamBridge のすべての send メソッドを含む StreamOperations インターフェースを介して契約を提供します。アプリケーションは StreamOperations を使用してオートワイヤーすることを選択できます。これは、StreamOperations インターフェースにモックまたは同様のメカニズムを提供することにより、StreamBridge を使用するコードの単体テストに関して便利です。 |
リアクティブ機能のサポート
Spring Cloud Function はプロジェクト Reactor (英語) の上に構築されているため、Supplier、Function、Consumer を実装する際に、リアクティブプログラミングモデルの恩恵を受けるために行う必要のあることはあまりありません。
例:
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Function<Flux<String>, Flux<String>> reactiveUpperCase() {
return flux -> flux.map(val -> val.toUpperCase());
}
}
リアクティブまたは命令型プログラミングモデルを選択する際に理解しておく必要がある重要なことはほとんどありません。 完全にリアクティブか、それとも単に API か ? リアクティブ API を使用しても、そのような API のすべてのリアクティブ機能を利用できるとは限りません。つまり、バックプレッシャーやその他の高度な機能などは、互換性のあるシステム (Reactive Kafka バインダーなど) で動作している場合にのみ機能します。通常の Kafka または Rabbit またはその他の非リアクティブバインダーを使用している場合、ストリームの実際のソースまたはターゲットはリアクティブがないため、リアクティブ API 自体の便利さからのみ恩恵を受け、その高度な機能から恩恵を受けることはできません。 エラー処理と再試行 このマニュアル全体を通して、フレームワークベースのエラー処理、再試行、その他の機能、それらに関連する構成プロパティに関する参照がいくつかあります。これらは命令型関数にのみ影響し、リアクティブ関数に関しては同じ期待を抱くべきではないことを理解することが重要です。そして、ここに理由があります... リアクティブ関数と命令型関数には基本的な違いがあります。命令型関数は、フレームワークが受信する各メッセージで呼び出されるメッセージハンドラーです。N 個のメッセージに対して、このような関数が N 回呼び出されるため、このような関数をラップして、エラー処理、再試行などの追加機能を追加できます。リアクティブ関数は初期化関数です。これは、フレームワークによって提供されたものに接続するために、ユーザーによって提供された Flux/Mono への参照を取得するために 1 回だけ呼び出されます。その後、私たち (フレームワーク) はストリームをまったく表示または制御できません。リアクティブ関数では、エラー処理と再試行 ( |
関数構成
関数型プログラミングモデルを使用すると、一連の単純な関数から複雑なハンドラーを動的に合成できる関数型合成の恩恵を受けることもできます。例として、上記で定義したアプリケーションに次の関数 Bean を追加しましょう。
@Bean
public Function<String, String> wrapInQuotes() {
return s -> "\"" + s + "\"";
}
そして、spring.cloud.function.definition プロパティを変更して、‘ toUpperCase ’ と ‘ wrapInQuotes ’ の両方から新しい関数を作成するという意図を反映します。これを行うには、Spring Cloud Function は | (パイプ) シンボルに依存します。例を終了すると、プロパティは次のようになります。
--spring.cloud.function.definition=toUpperCase|wrapInQuotes
| Spring Cloud Function によって提供される関数合成サポートの大きな利点の 1 つは、反応型および命令型の関数を合成できるという事実です。 |
コンポジションの結果は単一の関数であり、ご想像のとおり、他の構成プロパティに関しては非常に不便な非常に長くてわかりにくい名前(foo|bar|baz|xyz. . . など)を持つ可能性があります。これは、機能バインディング名セクションで説明されている説明的なバインディング名機能が役立つ場合があります。
例: toUpperCase|wrapInQuotes にわかりやすい名前を付けたい場合は、次のプロパティ spring.cloud.stream.function.bindings.toUpperCase|wrapInQuotes-in-0=quotedUpperCaseInput を使用して、他の構成プロパティがそのバインディング名(spring.cloud.stream.bindings.quotedUpperCaseInput.destination=myDestination など)を参照できるようにします。
機能構成と横断的関心事
関数の合成により、実行時に 1 つとして表すことができる、単純で個別に管理 / テスト可能なコンポーネントのセットに分解することで、複雑さに効果的に対処できます。しかし、それだけがメリットではありません。
また、コンポジションを使用して、コンテンツの強化など、特定の横断的非機能関心事に対処することもできます。例: 特定のヘッダーが不足している可能性のある受信メッセージがある場合、または一部のヘッダーがビジネス機能が期待する正確な状態にない場合を想定します。これで、これらの関心事に対処する別の機能を実装し、それをメインのビジネス機能で構成することができます。
例を見てみましょう
@SpringBootApplication
public class DemoStreamApplication {
public static void main(String[] args) {
SpringApplication.run(DemoStreamApplication.class,
"--spring.cloud.function.definition=enrich|echo",
"--spring.cloud.stream.function.bindings.enrich|echo-in-0=input",
"--spring.cloud.stream.bindings.input.destination=myDestination",
"--spring.cloud.stream.bindings.input.group=myGroup");
}
@Bean
public Function<Message<String>, Message<String>> enrich() {
return message -> {
Assert.isTrue(!message.getHeaders().containsKey("foo"), "Should NOT contain 'foo' header");
return MessageBuilder.fromMessage(message).setHeader("foo", "bar").build();
};
}
@Bean
public Function<Message<String>, Message<String>> echo() {
return message -> {
Assert.isTrue(message.getHeaders().containsKey("foo"), "Should contain 'foo' header");
System.out.println("Incoming message " + message);
return message;
};
}
}
些細なことですが、この例は、1 つの関数が受信メッセージを追加のヘッダー(機能以外の問題)で強化する方法を示しているため、他の関数(echo)はそれから利益を得ることができます。echo 関数はクリーンな状態を保ち、ビジネスロジックのみに焦点を合わせます。構成されたバインディング名を単純化するための spring.cloud.stream.function.bindings プロパティの使用箇所も確認できます。
複数の入力引数と出力引数を持つ関数
バージョン 3.0 以降 spring-cloud-stream は、複数の入力および / または複数の出力(戻り値)を持つ関数のサポートを提供します。これは実際にはどういう意味で、どのような種類のユースケースを対象としていますか?
ビッグデータ: 扱っているデータのソースが非常に整理されておらず、さまざまな型のデータ要素(オーダー、トランザクションなど)が含まれており、効果的に整理する必要があると想像してください。
データ集約: 別のユースケースでは、2 つ以上の受信 _stream からのデータ要素をマージする必要がある場合があります。
上記は、データの複数のストリームを受け入れたり生成したりするために単一の関数を使用する必要がある可能性があるいくつかのユースケースについて説明しています。これが、ここで対象としている型のユースケースです。
また、ここではストリームの概念が少し異なることに注意してください。このような関数は、(個々の要素ではなく)実際のデータストリームへのアクセスが許可されている場合にのみ価値があると想定されています。そのため、spring-cloud-functions によってもたらされる依存関係の一部として、クラスパスですでに利用可能なプロジェクト Reactor (英語) によって提供される抽象化(つまり、Flux および Mono)に依存しています。
もう 1 つの重要な側面は、複数の入力と出力の表現です。java は、さまざまな異なる抽象化を提供して、それらの抽象化が a)無制限、b)アリティの欠如、c)このコンテキストですべて重要な型情報の欠如 であるものの複数を表します。例として、Collection または配列を見てみましょう。これにより、単一の型の複数を記述したり、すべてを Object にアップキャストしたりして、spring-cloud-stream の透過型変換機能に影響を与えることができます。
これらすべての要件に対応するために、最初のサポートは、Project Reactor によって提供される別の抽象化である Tuples を利用する署名に依存しています。ただし、より柔軟な署名を許可するよう取り組んでいます。
| このようなアプリケーションで使用されるバインディング名を確立するために使用される命名規則を理解するには、バインディングとバインディング名セクションを参照してください。 |
いくつかのサンプルを見てみましょう。
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<Tuple2<Flux<String>, Flux<Integer>>, Flux<String>> gather() {
return tuple -> {
Flux<String> stringStream = tuple.getT1();
Flux<String> intStream = tuple.getT2().map(i -> String.valueOf(i));
return Flux.merge(stringStream, intStream);
};
}
}
上記の例は、2 つの入力(最初の型 String と 2 番目の型 Integer)を受け取り、型 String の単一の出力を生成する関数を示しています。
上記の例では、2 つの入力バインディングは gather-in-0 と gather-in-1 になり、一貫性を保つために、出力バインディングも同じ規則に従い、gather-out-0 という名前が付けられます。
それを知っていると、バインディング固有のプロパティを設定できます。例: 以下は、gather-in-0 バインディングのコンテンツ型をオーバーライドします。
--spring.cloud.stream.bindings.gather-in-0.content-type=text/plain
@SpringBootApplication
public class SampleApplication {
@Bean
public static Function<Flux<Integer>, Tuple2<Flux<String>, Flux<String>>> scatter() {
return flux -> {
Flux<Integer> connectedFlux = flux.publish().autoConnect(2);
UnicastProcessor even = UnicastProcessor.create();
UnicastProcessor odd = UnicastProcessor.create();
Flux<Integer> evenFlux = connectedFlux.filter(number -> number % 2 == 0).doOnNext(number -> even.onNext("EVEN: " + number));
Flux<Integer> oddFlux = connectedFlux.filter(number -> number % 2 != 0).doOnNext(number -> odd.onNext("ODD: " + number));
return Tuples.of(Flux.from(even).doOnSubscribe(x -> evenFlux.subscribe()), Flux.from(odd).doOnSubscribe(x -> oddFlux.subscribe()));
};
}
}
上記の例は、前のサンプルとは多少逆であり、型 Integer の単一の入力を受け取り、2 つの出力(両方とも型 String)を生成する関数を示しています。
上記の例では、入力バインディングは scatter-in-0 であり、出力バインディングは scatter-out-0 と scatter-out-1 です。
そして、次のコードでテストします。
@Test
public void testSingleInputMultiOutput() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleApplication.class))
.run("--spring.cloud.function.definition=scatter")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
for (int i = 0; i < 10; i++) {
inputDestination.send(MessageBuilder.withPayload(String.valueOf(i).getBytes()).build());
}
int counter = 0;
for (int i = 0; i < 5; i++) {
Message<byte[]> even = outputDestination.receive(0, 0);
assertThat(even.getPayload()).isEqualTo(("EVEN: " + String.valueOf(counter++)).getBytes());
Message<byte[]> odd = outputDestination.receive(0, 1);
assertThat(odd.getPayload()).isEqualTo(("ODD: " + String.valueOf(counter++)).getBytes());
}
}
}
1 つのアプリケーションで複数の機能
複数のメッセージハンドラーを 1 つのアプリケーションにグループ化する必要がある場合もあります。これを行うには、いくつかの関数を定義します。
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Bean
public Function<String, String> reverse() {
return value -> new StringBuilder(value).reverse().toString();
}
}
上記の例では、2 つの関数 uppercase と reverse を定義する構成があります。最初に、前述のように、競合(複数の関数)があることに注意する必要があります。バインドする実際の関数を指す spring.cloud.function.definition プロパティを提供して、競合を解決する必要があります。ここを除いて、; 区切り文字を使用して両方の関数を指します(以下のテストケースを参照)。
| 複数の入力 / 出力を持つ関数と同様に、バインディングとバインディング名セクションを参照して、そのようなアプリケーションで使用されるバインディング名を確立するために使用される命名規則を理解しましょう。 |
そして、次のコードでテストします。
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
ReactiveFunctionConfiguration.class))
.run("--spring.cloud.function.definition=uppercase;reverse")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "uppercase-in-0");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "uppercase-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-1");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
バッチコンシューマー
バッチリスナーをサポートする MessageChannelBinder を使用していて、この機能がコンシューマーバインディングに対して有効になっている場合、spring.cloud.stream.bindings.<binding-name>.consumer.batch-mode を true に設定して、メッセージのバッチ全体を List の関数に渡すことができます。
@Bean
public Function<List<Person>, Person> findFirstPerson() {
return persons -> persons.get(0);
}
バッチプロデューサー
メッセージのコレクションを返すことにより、プロデューサー側でバッチ処理の概念を使用することもできます。これにより、コレクション内の各メッセージがバインダーによって個別に送信されるという逆の効果が効果的に提供されます。
次の関数について考えてみます。
@Bean
public Function<String, List<Message<String>>> batch() {
return p -> {
List<Message<String>> list = new ArrayList<>();
list.add(MessageBuilder.withPayload(p + ":1").build());
list.add(MessageBuilder.withPayload(p + ":2").build());
list.add(MessageBuilder.withPayload(p + ":3").build());
list.add(MessageBuilder.withPayload(p + ":4").build());
return list;
};
}
返されたリストの各メッセージは個別に送信され、4 つのメッセージが出力先に送信されます。
関数としての Spring Integration フロー
関数を実装する場合、エンタープライズ統合パターン (英語) (EIP)のカテゴリに適合する複雑な要件がある場合があります。これらは、EIP のリファレンス実装である Spring Integration(SI)などのフレームワークを使用して処理するのが最適です。
ありがたいことに、SI はすでにゲートウェイとしての統合フローを介して統合フローを関数として公開するためのサポートを提供しています。次のサンプルを検討してください。
@SpringBootApplication
public class FunctionSampleSpringIntegrationApplication {
public static void main(String[] args) {
SpringApplication.run(FunctionSampleSpringIntegrationApplication.class, args);
}
@Bean
public IntegrationFlow uppercaseFlow() {
return IntegrationFlows.from(MessageFunction.class, "uppercase")
.<String, String>transform(String::toUpperCase)
.logAndReply(LoggingHandler.Level.WARN);
}
public interface MessageFunction extends Function<Message<String>, Message<String>> {
}
}
SI に精通している人のために、IntegrationFlow 型の Bean を定義し、uppercase と呼ばれる Function<String, String> (SI DSL を使用)として公開する統合フローを宣言していることがわかります。MessageFunction インターフェースを使用すると、適切な型変換のために入力と出力の型を明示的に宣言できます。型変換の詳細については、コンテンツ型の交渉セクションを参照してください。
生の入力を受け取るには、from(Function.class, …) を使用できます。
結果の関数は、ターゲットバインダーによって公開される入力および出力の宛先にバインドされます。
| このようなアプリケーションで使用されるバインディング名を確立するために使用される命名規則を理解するには、バインディングとバインディング名セクションを参照してください。 |
特に関数型プログラミングモデルに関する Spring Integration と Spring Cloud Stream の相互運用性の詳細については、この投稿 (英語) が非常に興味深いと思うかもしれません。Spring Integration と Spring Cloud Stream/ 関数の最高のものをマージすることで適用できるさまざまなパターンを少し深く掘り下げているからです。
ポーリングされたコンシューマーの使用
概要
ポーリングされたコンシューマーを使用する場合は、オンデマンドで PollableMessageSource をポーリングします。ポーリングされたコンシューマーのバインディングを定義するには、spring.cloud.stream.pollable-source プロパティを提供する必要があります。
ポーリングされたコンシューマーバインディングの次の例について考えてみます。
--spring.cloud.stream.pollable-source=myDestination 前の例のポーリング可能なソース名 myDestination は、myDestination-in-0 バインディング名が機能プログラミングモデルと一貫性を保つようにします。
前の例でポーリングされたコンシューマーを考えると、次のように使用できます。
@Bean
public ApplicationRunner poller(PollableMessageSource destIn, MessageChannel destOut) {
return args -> {
while (someCondition()) {
try {
if (!destIn.poll(m -> {
String newPayload = ((String) m.getPayload()).toUpperCase();
destOut.send(new GenericMessage<>(newPayload));
})) {
Thread.sleep(1000);
}
}
catch (Exception e) {
// handle failure
}
}
};
}
手動ではなく、Spring に似た代替手段は、スケジュールされたタスク Bean を構成することです。例:
@Scheduled(fixedDelay = 5_000)
public void poll() {
System.out.println("Polling...");
this.source.poll(m -> {
System.out.println(m.getPayload());
}, new ParameterizedTypeReference<Foo>() { });
}
PollableMessageSource.poll() メソッドは MessageHandler 引数を取ります(ここに示すように、多くの場合ラムダ式)。メッセージが受信され、正常に処理された場合は、true を返します。
メッセージ駆動型コンシューマーと同様に、MessageHandler が例外をスローすると、Error Handling に従って、メッセージはエラーチャネルに公開されます。
通常、poll() メソッドは、MessageHandler が終了したときにメッセージを確認応答します。メソッドが異常終了した場合、メッセージは拒否されます(再キューイングされません)が、エラーの処理を参照してください。次の例に示すように、確認応答の責任を取ることで、その動作をオーバーライドできます。
@Bean
public ApplicationRunner poller(PollableMessageSource dest1In, MessageChannel dest2Out) {
return args -> {
while (someCondition()) {
if (!dest1In.poll(m -> {
StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).noAutoAck();
// e.g. hand off to another thread which can perform the ack
// or acknowledge(Status.REQUEUE)
})) {
Thread.sleep(1000);
}
}
};
}
リソースリークを回避するために、ある時点でメッセージを ack (または nack)する必要があります。 |
一部のメッセージングシステム (Apache Kafka など) では、ログに単純なオフセットが保持されます。配信が失敗し、StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).acknowledge(Status.REQUEUE); で再キューに入れられた場合、その後正常に確認されたメッセージは再配信されます。 |
オーバーロードされた poll メソッドもあり、その定義は次のとおりです。
poll(MessageHandler handler, ParameterizedTypeReference<?> type)
type は、次の例に示すように、受信メッセージのペイロードを変換できるようにする変換ヒントです。
boolean result = pollableSource.poll(received -> {
Map<String, Foo> payload = (Map<String, Foo>) received.getPayload();
...
}, new ParameterizedTypeReference<Map<String, Foo>>() {});
エラーの処理
デフォルトでは、ポーリング可能なソースに対してエラーチャネルが構成されています。コールバックが例外をスローすると、ErrorMessage がエラーチャネル(<destination>.<group>.errors)に送信されます。このエラーチャネルは、グローバル Spring Integration errorChannel にもブリッジされます。
エラーを処理するために、@ServiceActivator を使用していずれかのエラーチャネルにサブスクライブできます。サブスクリプションがない場合、エラーは単にログに記録され、メッセージは成功したものとして確認されます。エラーチャネルサービスアクティベータが例外をスローした場合、メッセージは(デフォルトで)拒否され、再配信されません。サービスアクティベータが RequeueCurrentMessageException をスローした場合、メッセージはブローカで再キューイングされ、後続のポーリングで再度取得されます。
リスナーが RequeueCurrentMessageException を直接スローした場合、メッセージは上記のように再キューイングされ、エラーチャネルに送信されません。
イベントルーティング
イベントルーティングは、Spring Cloud Stream のコンテキストでは、a)イベントを特定のイベントサブスクライバーにルーティングする機能、または b)イベントサブスクライバーによって生成されたイベントを特定の宛先にルーティングする機能です。ここでは、これをルート "TO" およびルート "FROM" と呼びます。
コンシューマーへのルーティング
ルーティングは、Spring Cloud Function 3.0 で利用可能な RoutingFunction に依存することで実現できます。必要なのは、--spring.cloud.stream.function.routing.enabled=true アプリケーションプロパティを介してそれを有効にするか、spring.cloud.function.routing-expression プロパティを提供することです。有効にすると、RoutingFunction はすべてのメッセージを受信する入力宛先にバインドされ、提供された命令に基づいて他の機能にルーティングされます。
ルーティング宛先の名前をバインドするために、functionRouter-in-0 を使用します(RoutingFunction.FUNCTION_NAME およびバインド命名規則機能バインディング名を参照)。 |
指示は、個々のメッセージとアプリケーションのプロパティで提供できます。
ここにいくつかのサンプルがあります:
メッセージヘッダーの使用
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class,
"--spring.cloud.stream.function.routing.enabled=true");
}
@Bean
public Consumer<String> even() {
return value -> {
System.out.println("EVEN: " + value);
};
}
@Bean
public Consumer<String> odd() {
return value -> {
System.out.println("ODD: " + value);
};
}
}
バインダーによって公開された functionRouter-in-0 宛先(つまり、rabbit、kafka)にメッセージを送信することにより、そのようなメッセージは適切な(「偶数」または「奇数」)コンシューマーにルーティングされます。
デフォルトでは、RoutingFunction は spring.cloud.function.definition または spring.cloud.function.routing-expression (SpEL を使用するより動的なシナリオの場合)ヘッダーを検索し、見つかった場合、その値はルーティング命令として扱われます。
例: spring.cloud.function.routing-expression ヘッダーを値 T(java.lang.System).currentTimeMillis() % 2 == 0 ? 'even' : 'odd' に設定すると、odd または even 関数のいずれかにリクエストが半ランダムにルーティングされます。また、SpEL の場合、評価コンテキストのルートオブジェクトは Message であるため、個々のヘッダー(またはメッセージ)でも ….routing-expression=headers['type'] で評価を行うことができます。
アプリケーションプロパティの使用
spring.cloud.function.routing-expression および / または spring.cloud.function.definition は、アプリケーションプロパティとして渡すことができます(例: spring.cloud.function.routing-expression=headers['type'])。
@SpringBootApplication
public class RoutingStreamApplication {
public static void main(String[] args) {
SpringApplication.run(RoutingStreamApplication.class,
"--spring.cloud.function.routing-expression="
+ "T(java.lang.System).nanoTime() % 2 == 0 ? 'even' : 'odd'");
}
@Bean
public Consumer<Integer> even() {
return value -> System.out.println("EVEN: " + value);
}
@Bean
public Consumer<Integer> odd() {
return value -> System.out.println("ODD: " + value);
}
}
| リアクティブ関数はパブリッシャーを渡すために一度だけ呼び出されるため、個々のアイテムへのアクセスが制限されるため、アプリケーションプロパティを介して命令を渡すことは、リアクティブ関数にとって特に重要です。 |
ルーティング機能と出力バインディング
RoutingFunction は Function であるため、他の機能と同じように扱われます。
RoutingFunction が別の Function にルーティングする場合、その出力は RoutingFunction の出力バインディング (予想どおり functionRouter-in-0 ) に送信されます。しかし、RoutingFunction が Consumer にルーティングした場合はどうなりますか ? 言い換えれば、RoutingFunction の呼び出しの結果は、出力バインディングに送信されるものを何も生成しない可能性があるため、1 つでも持つ必要があります。バインディングを作成するときは、RoutingFunction を少し異なる方法で扱います。また、ユーザーとしては透過的ですが (実際には何もする必要はありません)、メカニズムのいくつかを認識しておくと、その内部の仕組みを理解できます。
ルールは次のとおりです。RoutingFunction の出力バインディングは作成せず、入力のみを作成します。Consumer にルーティングすると、出力バインディングがないため、RoutingFunction は実質的に Consumer になります。ただし、RoutingFunction が出力を生成する別の Function にルーティングされた場合、RoutingFunction の出力バインディングは動的に作成され、その時点で RoutingFunction はバインディング(入力バインディングと出力バインディングの両方を持つ)に関して通常の Function として機能します。
FROM コンシューマーのルーティング
静的な宛先とは別に、Spring Cloud Stream を使用すると、アプリケーションは動的にバインドされた宛先にメッセージを送信できます。これは、たとえば、実行時にターゲットの宛先を決定する必要がある場合に役立ちます。アプリケーションは、2 つの方法のいずれかでこれを行うことができます。
spring.cloud.stream.sendto.destination
解決する宛先の名前に設定された spring.cloud.stream.sendto.destination ヘッダーを指定することにより、フレームワークに委譲して出力宛先を動的に解決することもできます。
次の例を考えてみましょう。
@SpringBootApplication
@Controller
public class SourceWithDynamicDestination {
@Bean
public Function<String, Message<String>> destinationAsPayload() {
return value -> {
return MessageBuilder.withPayload(value)
.setHeader("spring.cloud.stream.sendto.destination", value).build();};
}
}
この例ではっきりとわかるように些細なことですが、出力は、spring.cloud.stream.sendto.destination ヘッダーが入力引数の値に設定されたメッセージです。フレームワークはこのヘッダーを参照し、その名前の宛先を作成または検出して出力を送信しようとします。
宛先名が事前にわかっている場合は、他の宛先と同様にプロデューサープロパティを構成できます。または、NewDestinationBindingCallback<> Bean を登録すると、バインディングが作成される直前に呼び出されます。コールバックは、バインダーによって使用される拡張プロデューサープロパティのジェネリクス型を取ります。それには 1 つの方法があります:
void configure(String destinationName, MessageChannel channel, ProducerProperties producerProperties,
T extendedProducerProperties);
次の例は、RabbitMQ バインダーの使用方法を示しています。
@Bean
public NewDestinationBindingCallback<RabbitProducerProperties> dynamicConfigurer() {
return (name, channel, props, extended) -> {
props.setRequiredGroups("bindThisQueue");
extended.setQueueNameGroupOnly(true);
extended.setAutoBindDlq(true);
extended.setDeadLetterQueueName("myDLQ");
};
}
複数のバインダー型で動的宛先をサポートする必要がある場合は、汎用型に Object を使用し、必要に応じて extended 引数をキャストします。 |
また、【 StreamBridge の使い方】セクションを参照して、同様のケースでさらに別のオプション(StreamBridge)をどのように利用できるかを確認してください。
後処理 (メッセージを送信した後)
関数が呼び出されると、その結果はフレームワークによってターゲットの宛先に送信され、関数呼び出しサイクルが事実上完了します。
ただし、このようなサイクルは、このサイクルの完了後に追加のタスクが実行されるまで、ビジネスの観点から完全には完了しない可能性があります。これは、このスタックオーバーフローの投稿 (英語) で説明されている Consumer と StreamBridge の単純な組み合わせで実現できますが、バージョン 4.0.3 以降、フレームワークは、Spring Cloud Function プロジェクトによって提供される PostProcessingFunction を介してこの課題を解決するためのより慣用的なアプローチを提供します。PostProcessingFunction は、このような後処理タスクを実装する場所を提供するために設計された 1 つの追加メソッド postProcess(Message>) を含む特別なセミマーカー関数です。
package org.springframework.cloud.function.context
. . .
public interface PostProcessingFunction<I, O> extends Function<I, O> {
default void postProcess(Message<O> result) {
}
}選択肢は 2 つあります。
オプション 1: 関数を PostProcessingFunction として実装し、その postProcess(Message>) メソッドを実装することで追加の後処理動作を組み込むこともできます。
private static class Uppercase implements PostProcessingFunction<String, String> {
@Override
public String apply(String input) {
return input.toUpperCase();
}
@Override
public void postProcess(Message<String> result) {
System.out.println("Function Uppercase has been successfully invoked and its result successfully sent to target destination");
}
}
. . .
@Bean
public Function<String, String> uppercase() {
return new Uppercase();
} オプション 2: 既存の関数がすでにあり、その実装を変更したくない場合、関数を POJO として維持したい場合は、postProcess(Message>) メソッドのみを実装し、この新しい後処理関数を他の関数と組み合わせることができます。
private static class Logger implements PostProcessingFunction<?, String> {
@Override
public void postProcess(Message<String> result) {
System.out.println("Function has been successfully invoked and its result successfully sent to target destination");
}
}
. . .
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
@Bean
public Function<String, String> logger() {
return new Logger();
}
. . .
// and then have your function definition as such `uppercase|logger`NOTE: 関数合成の場合、PostProcessingFunction の最後のインスタンス (存在する場合) のみが有効になります。例: 次の関数定義があるとします。foo|bar|baz と foo と baz は両方とも PostProcessingFunction のインスタンスです。baz.postProcess(Message>) のみが呼び出されます。baz が PostProcessingFunction のインスタンスではない場合、後処理機能は実行されません。
単にポストプロセッサーを別の Function として構成するだけで、関数を構成することで簡単にそれを行うことができると主張する人もいるかもしれません。確かにその可能性はありますが、この場合の後処理機能は、前の関数の呼び出し直後、メッセージがターゲット宛先に送信される前、つまり関数呼び出しサイクルが完了する前に呼び出されます。
エラー処理
このセクションでは、フレームワークによって提供されるエラー処理メカニズムの背後にある一般的な考え方について説明します。例として Rabbit バインダーを使用します。これは、個々のバインダーが、基盤となるブローカー機能(Kafka バインダーなど)に固有のサポートされている特定のメカニズムに対して異なるプロパティのセットを定義するためです。
エラーが発生し、Spring Cloud Stream はそれらに対処するためのいくつかの柔軟なメカニズムを提供します。この手法は、バインダーの実装、基盤となるメッセージングミドルウェアの機能、プログラミングモデルに依存していることに注意してください(これについては後で詳しく説明します)。
メッセージハンドラー (関数) が例外をスローするたびに、バインダーに反映されます。その時点で、バインダーは、Spring Retry [GitHub] (英語) ライブラリによって提供される RetryTemplate を使用して、同じメッセージの再試行を数回 (デフォルトでは 3 回) 試みます。再試行が失敗した場合、メッセージをドロップするか、再処理のためにメッセージを再キューイングするか、失敗したメッセージを DLQ に送信するエラー処理メカニズム次第です。
Rabbit と Kafka の両方がこれらの概念 (特に DLQ) をサポートしています。ただし、他のバインダではそうでない場合もあるため、サポートされているエラー処理オプションの詳細については、個々のバインダのドキュメントを参照してください。
ただし、リアクティブ関数は個々のメッセージを処理せず、フレームワークによって提供されるストリーム (つまり、Flux) をユーザーによって提供されるストリームに接続する方法を提供するため、メッセージハンドラーとしての資格がないことに注意してください。何でこれが大切ですか? これは、再試行テンプレート、失敗したメッセージのドロップ、再試行、DLQ、これらすべてを支援する構成プロパティに関してこのセクションの後半で説明する内容は、メッセージハンドラー (つまり、命令型関数) にのみ適用されるためです。
Reactive API は、独自の演算子とメカニズムの非常に豊富なライブラリを提供し、単純なメッセージハンドラーの場合よりもはるかに複雑なさまざまなリアクティブなユースケースに固有のエラー処理を支援します。reactor.core.publisher.Flux にある public final Flux<T> retryWhen(Retry retrySpec); などを使用してください。
@Bean
public Function<Flux<String>, Flux<String>> uppercase() {
return flux -> flux
.retryWhen(Retry.backoff(3, Duration.ofMillis(1000)))
.map(v -> v.toUpperCase());
}
失敗したメッセージを削除する
デフォルトでは、システムはエラーハンドラーを提供します。最初のエラーハンドラーは、単にエラーメッセージをログに記録します。2 番目のエラーハンドラーはバインダー固有のエラーハンドラーで、特定のメッセージングシステム (DLQ への送信など) のコンテキストでエラーメッセージを処理します。ただし、(この現在のシナリオでは) 追加のエラー処理構成が提供されていないため、このハンドラーは何もしません。本質的にログに記録された後、メッセージはドロップされます。
許容できる場合もありますが、ほとんどの場合はそうではありません。メッセージの損失を回避するために何らかの回復メカニズムが必要です。
エラーメッセージの処理
前のセクションで、デフォルトでは、エラーになったメッセージは効果的にログに記録され、ドロップされると述べました。このフレームワークは、カスタムエラーハンドラーを提供するためのメカニズムも公開します (つまり、通知の送信やデータベースへの書き込みなど)。これを行うには、エラーに関するすべての情報 (スタックトレースなど) とは別に、元のメッセージ (エラーを引き起こしたメッセージ) を含む ErrorMessage を受け入れるように特別に設計された Consumer を追加します。注: カスタムエラーハンドラーは、フレームワークが提供するエラーハンドラー (つまり、ログ記録およびバインダーエラーハンドラー - 前のセクションを参照) と相互に排他的であり、それらが干渉しないようにします。
@Bean
public Consumer<ErrorMessage> myErrorHandler() {
return v -> {
// send SMS notification code
};
}
このようなコンシューマーをエラーハンドラーとして識別するために必要なのは、関数名 spring.cloud.stream.bindings.<binding-name>.error-handler-definition=myErrorHandler を指す error-handler-definition プロパティを提供することだけです。
例: バインド名 uppercase-in-0 の場合、プロパティは次のようになります。
spring.cloud.stream.bindings.uppercase-in-0.error-handler-definition=myErrorHandler 特別なマッピング命令を使用してバインディングをより読みやすい名前 spring.cloud.stream.function.bindings.uppercase-in-0=upper にマップすると、このプロパティは次のようになります。
spring.cloud.stream.bindings.upper.error-handler-definition=myErrorHandler. 誤ってそのようなハンドラーを Function として宣言した場合でも、その出力に対して何も行われないことを除いて、ハンドラーは機能します。ただし、そのようなハンドラーがまだ Spring Cloud Function によって提供される機能に依存していることを考えると、ハンドラーに関数合成によって対処したい複雑性がある場合は、関数合成の恩恵を受けることもできます (ただし、可能性は低いです)。 |
デフォルトのエラーハンドラー
すべての関数 Bean に対して単一のエラーハンドラーが必要な場合は、標準の spring-cloud-stream メカニズムを使用して、既定のプロパティ spring.cloud.stream.default.error-handler-definition=myErrorHandler を定義できます。
DLQ - デッドレターキュー
おそらく最も一般的なメカニズムである DLQ を使用すると、失敗したメッセージを特別な宛先である Dead LetterQueue に送信できます。
構成すると、失敗したメッセージがこの宛先に送信され、その後の再処理または監査と調整が行われます。
次の例を考えてみましょう。
@SpringBootApplication
public class SimpleStreamApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(SimpleStreamApplication.class,
"--spring.cloud.function.definition=uppercase",
"--spring.cloud.stream.bindings.uppercase-in-0.destination=uppercase",
"--spring.cloud.stream.bindings.uppercase-in-0.group=myGroup",
"--spring.cloud.stream.rabbit.bindings.uppercase-in-0.consumer.auto-bind-dlq=true"
);
}
@Bean
public Function<Person, Person> uppercase() {
return personIn -> {
throw new RuntimeException("intentional");
});
};
}
}
注意として、この例では、プロパティの uppercase-in-0 セグメントは、入力宛先バインディングの名前に対応しています。consumer セグメントは、それがコンシューマーアセットであることを示しています。
DLQ を使用する場合、DLQ 宛先の適切な命名のために、少なくとも group プロパティを提供する必要があります。ただし、この例のように、group は destination プロパティと一緒に使用されることがよくあります。 |
いくつかの標準プロパティとは別に、uppercase 宛先に対応する uppercase-in-0 バインディングの DLQ 宛先を作成および構成するようにバインダーに指示するように auto-bind-dlq を設定します(対応するプロパティを参照)。これにより、uppercase.myGroup.dlq という名前の追加の Rabbit キューが生成されます(Kafka 固有の Kafka ドキュメントを参照) DLQ プロパティ)。
構成が完了すると、失敗したすべてのメッセージがこの宛先にルーティングされ、元のメッセージが保持されて以降のアクションが実行されます。
また、次のように、エラーメッセージに元のエラーに関連する詳細情報が含まれていることがわかります。
. . . .
x-exception-stacktrace: org.springframework.messaging.MessageHandlingException: nested exception is
org.springframework.messaging.MessagingException: has an error, failedMessage=GenericMessage [payload=byte[15],
headers={amqp_receivedDeliveryMode=NON_PERSISTENT, amqp_receivedRoutingKey=input.hello, amqp_deliveryTag=1,
deliveryAttempt=3, amqp_consumerQueue=input.hello, amqp_redelivered=false, id=a15231e6-3f80-677b-5ad7-d4b1e61e486e,
amqp_consumerTag=amq.ctag-skBFapilvtZhDsn0k3ZmQg, contentType=application/json, timestamp=1522327846136}]
at org.spring...integ...han...MethodInvokingMessageProcessor.processMessage(MethodInvokingMessageProcessor.java:107)
at. . . . .
Payload: blahmax-attempts を "1" に設定することにより、DLQ への即時ディスパッチ(再試行なし)を容易にすることもできます。例:
--spring.cloud.stream.bindings.uppercase-in-0.consumer.max-attempts=1テンプレートを再試行
このセクションでは、再試行機能の構成に関連する構成プロパティについて説明します。
RetryTemplate は Spring Retry [GitHub] (英語) ライブラリの一部です。RetryTemplate のすべての機能を網羅することはこのドキュメントの範囲外ですが、RetryTemplate に特に関連する次のコンシューマープロパティについて説明します。
- maxAttempts
メッセージの処理の試行回数。
デフォルト: 3.
- backOffInitialInterval
再試行時のバックオフ初期間隔。
デフォルトは 1000 ミリ秒です。
- backOffMaxInterval
最大バックオフ間隔。
デフォルトの 10000 ミリ秒。
- backOffMultiplier
バックオフ乗数。
デフォルトの 2.0。
- defaultRetryable
retryableExceptionsにリストされていないリスナーによってスローされた例外が再試行可能かどうか。デフォルト:
true.- retryableExceptions
キーの Throwable クラス名と値のブール値のマップ。再試行される、または再試行されない例外(およびサブクラス)を指定します。
defaultRetriableも参照してください。例:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false。デフォルト: 空。
上記の設定は、カスタマイズ要件の大部分には十分ですが、特定の複雑な要件を満たさない場合があります。その場合、RetryTemplate の独自のインスタンスを提供することをお勧めします。これを行うには、アプリケーション構成で Bean として構成します。アプリケーションが提供するインスタンスは、フレームワークが提供するインスタンスをオーバーライドします。また、競合を回避するには、バインダーで使用する RetryTemplate のインスタンスを @StreamRetryTemplate として修飾する必要があります。例:
@StreamRetryTemplate
public RetryTemplate myRetryTemplate() {
return new RetryTemplate();
}
上記の例からわかるように、@StreamRetryTemplate は修飾された @Bean であるため、@Bean でアノテーションを付ける必要はありません。
RetryTemplate をより正確にする必要がある場合は、ConsumerProperties で名前で Bean を指定して、バインディングごとに特定の再試行 Bean を関連付けることができます。
spring.cloud.stream.bindings.<foo>.consumer.retry-template-name=<your-retry-template-bean-name>バインダー
Spring Cloud Stream は、外部ミドルウェアで物理的な宛先に接続する際に使用するバインダー抽象化を提供します。このセクションでは、Binder SPI の背後にある主要な概念、その主要なコンポーネント、実装固有の詳細について説明します。
プロデューサーとコンシューマー
次のイメージは、プロデューサーとコンシューマーの一般的な関連を示しています。
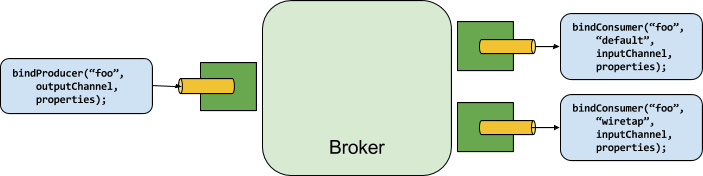
プロデューサーは、バインディングの宛先にメッセージを送信するコンポーネントです。バインド先は、そのブローカーの Binder 実装を使用して外部メッセージブローカーにバインドできます。bindProducer() メソッドを呼び出す場合、最初のパラメーターはブローカー内の宛先の名前、2 番目のパラメーターはプロデューサーがメッセージを送信するローカル宛先の場合のインスタンス、3 番目のパラメーターには以下のプロパティ(パーティションキー式など)が含まれます。そのバインディング宛先用に作成されたアダプター内で使用されます。
コンシューマーとは、バインディングの宛先からメッセージを受信するコンポーネントです。プロデューサーと同様に、コンシューマーは外部メッセージブローカーにバインドできます。bindConsumer() メソッドを呼び出す場合、最初のパラメーターは宛先名であり、2 番目のパラメーターはコンシューマーの論理グループの名前を提供します。特定の宛先のコンシューマーバインディングによって表される各グループは、プロデューサーがその宛先に送信する各メッセージのコピーを受信します(つまり、通常のパブリッシュ / サブスクライブセマンティクスに従います)。同じグループ名でバインドされた複数のコンシューマーインスタンスがある場合、メッセージはそれらのコンシューマーインスタンス間で負荷分散されるため、プロデューサーによって送信された各メッセージは、各グループ内の単一のコンシューマーインスタンスによってのみ消費されます(つまり、通常のキューイングに従います)。セマンティクス)。
バインダー SPI
Binder SPI は、外部ミドルウェアに接続するためのプラグ可能なメカニズムを提供する、多数のインターフェース、すぐに使用可能なユーティリティクラス、検出戦略で構成されています。
SPI の重要なポイントは Binder インターフェースです。これは、入力と出力を外部ミドルウェアに接続するための戦略です。次のリストは、Binder インターフェースの定義を示しています。
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String bindingName, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String bindingName, T outboundBindTarget, P producerProperties);
}
インターフェースはパラメーター化されており、いくつかの拡張ポイントを提供します。
入力および出力バインドターゲット。
拡張されたコンシューマープロパティとプロデューサープロパティ。特定のバインダー実装で、型安全な方法でサポートできる補足プロパティを追加できます。
一般的なバインダーの実装は、次のもので構成されます。
Binderインターフェースを実装するクラス。ミドルウェア接続インフラストラクチャとともに型
Binderの Bean を作成する Spring@Configurationクラス。次の例に示すように、1 つ以上のバインダー定義を含むクラスパスで見つかった
META-INF/spring.bindersファイル。kafka:\ org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration
前に記述されていたように、バインダーの抽象化もフレームワークの拡張ポイントの 1 つです。上記のリストで適切なバインダーが見つからない場合は、Spring Cloud Stream の上に独自のバインダーを実装できます。Spring Cloud Stream バインダーを最初から作成する方法 (英語) で、コミュニティメンバーのドキュメントを詳細に投稿します。例として、カスタムバインダーを実装するために必要な一連の手順を示します。手順は、Implementing Custom Binders セクションでも強調表示されています。 |
バインダー検出
Spring Cloud Stream は、Binder SPI の実装に依存して、ユーザーコードをメッセージブローカーに接続(バインド)するタスクを実行します。各バインダー実装は通常、1 つの型のメッセージングシステムに接続します。
クラスパス検出
デフォルトでは、Spring Cloud Stream は Spring Boot の自動構成に依存してバインディングプロセスを構成します。クラスパスで単一のバインダー実装が見つかった場合、Spring Cloud Stream はそれを自動的に使用します。例: RabbitMQ にのみバインドすることを目的とした Spring Cloud Stream プロジェクトは、次の依存関係を追加できます。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>他のバインダー依存関係の特定の Maven 座標については、そのバインダー実装のドキュメントを参照してください。
クラスパス上の複数のバインダー
クラスパスに複数のバインダーが存在する場合、アプリケーションは、各宛先バインディングに使用されるバインダーを指定する必要があります。次の例に示すように、各バインダー構成には、単純なプロパティファイルである META-INF/spring.binders ファイルが含まれています。
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration 提供されている他のバインダー実装(Kafka など)にも同様のファイルが存在し、カスタムバインダー実装も提供することが期待されています。キーはバインダー実装の識別名を表しますが、値は構成クラスのコンマ区切りのリストであり、それぞれに型 org.springframework.cloud.stream.binder.Binder の Bean 定義が 1 つだけ含まれています。
バインダーの選択は、spring.cloud.stream.defaultBinder プロパティ(たとえば、spring.cloud.stream.defaultBinder=rabbit)を使用してグローバルに実行することも、各バインディングでバインダーを構成することによって個別に実行することもできます。たとえば、Kafka から読み取り、RabbitMQ に書き込むプロセッサーアプリケーション(読み取りと書き込みにそれぞれ input と output という名前のバインディングを持つ)は、次の構成を指定できます。
spring.cloud.stream.bindings.input.binder=kafka
spring.cloud.stream.bindings.output.binder=rabbit複数のシステムへの接続
デフォルトでは、バインダーはアプリケーションの Spring Boot 自動構成を共有するため、クラスパスで見つかった各バインダーのインスタンスが 1 つ作成されます。アプリケーションが同じ型の複数のブローカーに接続する必要がある場合は、それぞれが異なる環境設定を持つ複数のバインダー構成を指定できます。
明示的なバインダー構成をオンにすると、デフォルトのバインダー構成プロセスが完全に無効になります。その場合、使用中のすべてのバインダーを構成に含める必要があります。Spring Cloud Stream を透過的に使用する予定のフレームワークは、名前で参照できるバインダー構成を作成する場合がありますが、デフォルトのバインダー構成には影響しません。そうするために、バインダー構成では、defaultCandidate フラグを false に設定することができます(たとえば、spring.cloud.stream.binders.<configurationName>.defaultCandidate=false)。これは、デフォルトのバインダー構成プロセスとは独立して存在する構成を示します。 |
次の例は、2 つの RabbitMQ ブローカーインスタンスに接続するプロセッサーアプリケーションの一般的な構成を示しています。
spring:
cloud:
stream:
bindings:
input:
destination: thing1
binder: rabbit1
output:
destination: thing2
binder: rabbit2
binders:
rabbit1:
type: rabbit
environment:
spring:
rabbitmq:
host: <host1>
rabbit2:
type: rabbit
environment:
spring:
rabbitmq:
host: <host2> 特定のバインダーの environment プロパティは、特定のバインダーの構成を追加するのに役立つこの spring.main.sources を含む、任意の Spring Boot プロパティにも使用できます。自動構成された Bean をオーバーライドします。 |
次に例を示します ;
environment:
spring:
main:
sources: com.acme.config.MyCustomBinderConfiguration 特定のバインダー環境の特定のプロファイルをアクティブ化するには、spring.profiles.active プロパティを使用する必要があります。
environment:
spring:
profiles:
active: myBinderProfileマルチバインダーアプリケーションでのバインダーのカスタマイズ
アプリケーションに複数のバインダーが含まれていて、バインダーをカスタマイズしたい場合は、BinderCustomizer 実装を提供することでそれを実現できます。単一のバインダーを使用するアプリケーションの場合、バインダーコンテキストはカスタマイズ Bean に直接アクセスできるため、この特別なカスタマイザーは必要ありません。ただし、これはマルチバインダーシナリオには当てはまりません。これは、さまざまなバインダーがさまざまなアプリケーションコンテキストに存在するためです。BinderCustomizer インターフェースの実装を提供することにより、バインダーは異なるアプリケーションコンテキストに存在しますが、カスタマイズを受け取ります。Spring Cloud Stream は、アプリケーションがバインダーの使用を開始する前にカスタマイズが行われることを保証します。ユーザーはバインダーの種類を確認してから、必要なカスタマイズを適用する必要があります。
BinderCustomizer Bean を提供する例を次に示します。
@Bean
public BinderCustomizer binderCustomizer() {
return (binder, binderName) -> {
if (binder instanceof KafkaMessageChannelBinder kafkaMessageChannelBinder) {
kafkaMessageChannelBinder.setRebalanceListener(...);
}
else if (binder instanceof KStreamBinder) {
...
}
else if (binder instanceof RabbitMessageChannelBinder) {
...
}
};
}
同じ型のバインダーのインスタンスが複数ある場合は、バインダー名を使用してカスタマイズをフィルター処理できることに注意してください。
結合の視覚化と制御
Spring Cloud Stream は、アクチュエーターエンドポイントを介したバインディングの視覚化と制御、およびプログラムによる方法をサポートしています。
プログラム的な方法
バージョン 3.1 以降、Bean として登録されている org.springframework.cloud.stream.binding.BindingsLifecycleController を公開しており、注入されると、個々のバインディングのライフサイクルを制御するために使用できます。
ex: テストケースの 1 つのフラグメントを調べます。ご覧のとおり、Spring アプリケーションコンテキストから BindingsLifecycleController を取得し、個々のメソッドを実行して echo-in-0 バインディングのライフサイクルを制御します。
BindingsLifecycleController bindingsController = context.getBean(BindingsLifecycleController.class);
Binding binding = bindingsController.queryState("echo-in-0");
assertThat(binding.isRunning()).isTrue();
bindingsController.changeState("echo-in-0", State.STOPPED);
//Alternative way of changing state. For convenience we expose start/stop and pause/resume operations.
//bindingsController.stop("echo-in-0")
assertThat(binding.isRunning()).isFalse();
アクチュエーター
アクチュエーターと Web はオプションであるため、最初に Web 依存関係の 1 つを追加し、アクチュエーター依存関係を手動で追加する必要があります。次の例は、Web フレームワークの依存関係を追加する方法を示しています。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>次の例は、WebFlux フレームワークの依存関係を追加する方法を示しています。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>次のように、アクチュエーターの依存関係を追加できます。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Cloud Foundry で Spring Cloud Stream 2.0 アプリを実行するには、クラスパスに spring-boot-starter-web と spring-boot-starter-actuator を追加する必要があります。そうしないと、ヘルスチェックの失敗によりアプリケーションが起動しません。 |
また、次のプロパティを設定して、bindings アクチュエーターのエンドポイントを有効にする必要があります: --management.endpoints.web.exposure.include=bindings。
これらの前提条件が満たされたら。アプリケーションの起動時に、ログに次の情報が表示されます。
: Mapped "{[/actuator/bindings/{name}],methods=[POST]. . .
: Mapped "{[/actuator/bindings],methods=[GET]. . .
: Mapped "{[/actuator/bindings/{name}],methods=[GET]. . . 現在のバインディングを視覚化するには、次の URL にアクセスします: http://<host>:<port>/actuator/bindings (英語)
別の方法として、単一のバインディングを表示するには、次のような URL のいずれかにアクセスします。http://<host>:<port>/actuator/bindings/<bindingName> (英語) ;
次の例に示すように、JSON として state 引数を指定しながら、同じ URL に投稿することで、個々のバインディングを停止、開始、一時停止、再開することもできます。
curl -d '{"state":"STOPPED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"STARTED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"PAUSED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"RESUMED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingNamePAUSED および RESUMED は、対応するバインダーとその基礎となるテクノロジーがサポートしている場合にのみ機能します。それ以外の場合は、ログに警告メッセージが表示されます。現在、Kafka および [Solace]( https://github.com/SolaceProducts/solace-spring-cloud/tree/master/solace-spring-cloud-starters/solace-spring-cloud-stream-starter#consumer-bindings-pauseresume (英語) ) バインダーのみが PAUSED および RESUMED 状態をサポートしています。 |
バインダー構成プロパティ
バインダー構成をカスタマイズする場合は、次のプロパティを使用できます。org.springframework.cloud.stream.config.BinderProperties を介して公開されたこれらのプロパティ
プレフィックスとして spring.cloud.stream.binders.<configurationName> を付ける必要があります。
- 型
バインダー型。これは通常、クラスパスにあるバインダーの 1 つ、特に
META-INF/spring.bindersファイルのキーを参照します。デフォルトでは、構成名と同じ値になります。
- inheritEnvironment
構成がアプリケーション自体の環境を継承するかどうか。
デフォルト:
true.- 環境
バインダーの環境をカスタマイズするために使用できる一連のプロパティのルート。このプロパティが設定されている場合、バインダーが作成されているコンテキストは、アプリケーションコンテキストの子ではありません。この設定により、バインダーコンポーネントとアプリケーションコンポーネントを完全に分離できます。
デフォルト:
empty.- defaultCandidate
バインダー構成がデフォルトのバインダーと見なされる候補であるか、明示的に参照されている場合にのみ使用できるか。この設定により、デフォルトの処理を妨げることなくバインダー構成を追加できます。
デフォルト:
true.
カスタムバインダーの実装
カスタム Binder を実装するには、次のことを行うだけです。
必要な依存関係を追加します
ProvisioningProvider 実装を提供する
MessageProducer 実装を提供する
MessageHandler 実装を提供する
バインダーの実装を提供する
バインダー構成を作成する
META-INF/spring.binders でバインダーを定義します
必要な依存関係を追加します
spring-cloud-stream 依存関係をプロジェクトに追加します(例: Maven の場合):
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
<version>${spring.cloud.stream.version}</version>
</dependency>ProvisioningProvider 実装を提供する
ProvisioningProvider は、コンシューマーとプロデューサーの宛先のプロビジョニングを担当し、物理的な宛先参照の application.yml または application.properties ファイルに含まれる論理的な宛先を変換する必要があります。
入出力バインディング構成を介して提供される宛先を単純にトリミングする ProvisioningProvider 実装の例を以下に示します。
public class FileMessageBinderProvisioner implements ProvisioningProvider<ConsumerProperties, ProducerProperties> {
@Override
public ProducerDestination provisionProducerDestination(
final String name,
final ProducerProperties properties) {
return new FileMessageDestination(name);
}
@Override
public ConsumerDestination provisionConsumerDestination(
final String name,
final String group,
final ConsumerProperties properties) {
return new FileMessageDestination(name);
}
private class FileMessageDestination implements ProducerDestination, ConsumerDestination {
private final String destination;
private FileMessageDestination(final String destination) {
this.destination = destination;
}
@Override
public String getName() {
return destination.trim();
}
@Override
public String getNameForPartition(int partition) {
throw new UnsupportedOperationException("Partitioning is not implemented for file messaging.");
}
}
}
MessageProducer 実装を提供する
MessageProducer は、イベントを消費し、そのようなイベントを消費するように構成されたクライアントアプリケーションへのメッセージとして処理する責任があります。
これは、MessageProducerSupport 抽象化を継承して、トリミングされた宛先名に一致し、プロジェクトパスにあるファイルをポーリングすると同時に、読み取りメッセージをアーカイブし、結果として生じる同一のメッセージを破棄する MessageProducer 実装の例です。
public class FileMessageProducer extends MessageProducerSupport {
public static final String ARCHIVE = "archive.txt";
private final ConsumerDestination destination;
private String previousPayload;
public FileMessageProducer(ConsumerDestination destination) {
this.destination = destination;
}
@Override
public void doStart() {
receive();
}
private void receive() {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
executorService.scheduleWithFixedDelay(() -> {
String payload = getPayload();
if(payload != null) {
Message<String> receivedMessage = MessageBuilder.withPayload(payload).build();
archiveMessage(payload);
sendMessage(receivedMessage);
}
}, 0, 50, MILLISECONDS);
}
private String getPayload() {
try {
List<String> allLines = Files.readAllLines(Paths.get(destination.getName()));
String currentPayload = allLines.get(allLines.size() - 1);
if(!currentPayload.equals(previousPayload)) {
previousPayload = currentPayload;
return currentPayload;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return null;
}
private void archiveMessage(String payload) {
try {
Files.write(Paths.get(ARCHIVE), (payload + "\n").getBytes(), CREATE, APPEND);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
| カスタムバインダーを実装する場合、既存の MessageProducer 実装を常に使用できるため、この手順は厳密には必須ではありません。 |
MessageHandler 実装を提供する
MessageHandler は、イベントを生成するために必要なロジックを提供します。
MessageHandler の実装例を次に示します。
public class FileMessageHandler implements MessageHandler{
@Override
public void handleMessage(Message<?> message) throws MessagingException {
//write message to file
}
}
| カスタムバインダーを実装する場合、既存の MessageHandler 実装を常に使用できるため、この手順は厳密には必須ではありません。 |
バインダーの実装を提供する
これで、Binder 抽象化の独自の実装を提供できるようになりました。これは、次の方法で簡単に実行できます。
AbstractMessageChannelBinderクラスの拡張ProvisioningProvider を AbstractMessageChannelBinder のジェネリクス引数として指定する
createProducerMessageHandlerおよびcreateConsumerEndpointメソッドのオーバーライド
例:
public class FileMessageBinder extends AbstractMessageChannelBinder<ConsumerProperties, ProducerProperties, FileMessageBinderProvisioner> {
public FileMessageBinder(
String[] headersToEmbed,
FileMessageBinderProvisioner provisioningProvider) {
super(headersToEmbed, provisioningProvider);
}
@Override
protected MessageHandler createProducerMessageHandler(
final ProducerDestination destination,
final ProducerProperties producerProperties,
final MessageChannel errorChannel) throws Exception {
return message -> {
String fileName = destination.getName();
String payload = new String((byte[])message.getPayload()) + "\n";
try {
Files.write(Paths.get(fileName), payload.getBytes(), CREATE, APPEND);
} catch (IOException e) {
throw new RuntimeException(e);
}
};
}
@Override
protected MessageProducer createConsumerEndpoint(
final ConsumerDestination destination,
final String group,
final ConsumerProperties properties) throws Exception {
return new FileMessageProducer(destination);
}
}
バインダー構成を作成する
バインダー実装(および必要になる可能性のある他のすべての Bean)の Bean を初期化するために、Spring 構成を作成することが厳密に必要です。
@Configuration
public class FileMessageBinderConfiguration {
@Bean
@ConditionalOnMissingBean
public FileMessageBinderProvisioner fileMessageBinderProvisioner() {
return new FileMessageBinderProvisioner();
}
@Bean
@ConditionalOnMissingBean
public FileMessageBinder fileMessageBinder(FileMessageBinderProvisioner fileMessageBinderProvisioner) {
return new FileMessageBinder(null, fileMessageBinderProvisioner);
}
}
META-INF/spring.binders でバインダーを定義します
最後に、クラスパスの META-INF/spring.binders ファイルでバインダーを定義し、バインダーの名前とバインダー構成クラスの完全修飾名の両方を指定する必要があります。
myFileBinder:\
com.example.springcloudstreamcustombinder.config.FileMessageBinderConfiguration構成オプション
Spring Cloud Stream は、一般的な構成オプションと、バインディングおよびバインダーの構成をサポートします。一部のバインダーでは、追加のバインディングプロパティでミドルウェア固有の機能をサポートできます。
構成オプションは、Spring Boot でサポートされている任意のメカニズムを介して Spring Cloud Stream アプリケーションに提供できます。これには、アプリケーション引数、環境変数、YAML または .properties ファイルが含まれます。
バインディングサービスのプロパティ
これらのプロパティは、org.springframework.cloud.stream.config.BindingServiceProperties を介して公開されます
- spring.cloud.stream.instanceCount
アプリケーションのデプロイされたインスタンスの数。プロデューサー側でパーティション分割するように設定する必要があります。RabbitMQ を使用する場合はコンシューマー側で設定し、
autoRebalanceEnabled=falseの場合は Kafka で設定する必要があります。デフォルト:
1.- spring.cloud.stream.instanceIndex
アプリケーションのインスタンスインデックス:
0からinstanceCount - 1までの番号。RabbitMQ およびautoRebalanceEnabled=falseの場合は Kafka を使用したパーティショニングに使用されます。アプリケーションのインスタンスインデックスに一致するように Cloud Foundry に自動的に設定されます。- spring.cloud.stream.dynamicDestinations
動的にバインドできる宛先のリスト(たとえば、動的ルーティングシナリオの場合)。設定されている場合、リストされている宛先のみをバインドできます。
デフォルト: 空(宛先をバインドする)。
- spring.cloud.stream.defaultBinder
複数のバインダーが構成されている場合に使用するデフォルトのバインダー。クラスパス上の複数のバインダーを参照してください。
デフォルト: 空。
- spring.cloud.stream.overrideCloudConnectors
このプロパティは、
cloudプロファイルがアクティブであり、Spring Cloud Connectors がアプリケーションに提供されている場合にのみ適用されます。プロパティがfalse(デフォルト)の場合、バインダーは適切なバインドされたサービス(たとえば、RabbitMQ バインダー用に Cloud Foundry でバインドされた RabbitMQ サービス)を検出し、接続の作成に使用します(通常は Spring Cloud Connectors を介して)。trueに設定すると、このプロパティは、バインドされたサービスを完全に無視し、Spring Boot プロパティに依存するようにバインダーに指示します(たとえば、RabbitMQ バインダーの環境で提供されるspring.rabbitmq.*プロパティに依存します)。このプロパティの一般的な使用箇所は、複数のシステムに接続するときに、カスタマイズされた環境にネストすることです。デフォルト:
false.- spring.cloud.stream.bindingRetryInterval
たとえば、バインダーが遅延バインディングをサポートしておらず、ブローカー (Apache Kafka など) がダウンしている場合に、バインディング作成を再試行する間隔 (秒単位)。このような状態を致命的として扱い、アプリケーションの起動を妨げるには、これを 0 に設定します。
デフォルト:
30
バインディングプロパティ
バインディングプロパティは、spring.cloud.stream.bindings.<bindingName>.<property>=<value> の形式を使用して提供されます。<bindingName> は、構成されているバインディングの名前を表します。
例: 次の機能の場合
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
入力用の uppercase-in-0 と出力用の uppercase-out-0 という名前の 2 つのバインディングがあります。詳細については、バインディングとバインディング名を参照してください。
繰り返しを避けるために、Spring Cloud Stream は、共通のバインディングプロパティの spring.cloud.stream.default.<property>=<value> および spring.cloud.stream.default.<producer|consumer>.<property>=<value> の形式で、すべてのバインディングの値の設定をサポートしています。
拡張バインディングプロパティの繰り返しを回避する場合は、この形式(spring.cloud.stream.<binder-type>.default.<producer|consumer>.<property>=<value>)を使用する必要があります。
一般的なバインディングプロパティ
これらのプロパティは、org.springframework.cloud.stream.config.BindingProperties を介して公開されます
次のバインディングプロパティは、入力バインディングと出力バインディングの両方で使用でき、接頭辞 spring.cloud.stream.bindings.<bindingName>. (たとえば、spring.cloud.stream.bindings.uppercase-in-0.destination=ticktock)を付ける必要があります。
デフォルト値は、spring.cloud.stream.default プレフィックス(たとえば、spring.cloud.stream.default.contentType=application/json)を使用して設定できます。
- 宛先
バインドされたミドルウェアのバインディングのターゲット宛先(たとえば、RabbitMQ 交換または Kafka トピック)。バインディングがコンシューマーバインディング(入力)を表す場合、複数の宛先にバインドでき、宛先名はコンマ区切りの
String値として指定できます。そうでない場合は、代わりに実際のバインディング名が使用されます。このプロパティのデフォルト値は上書きできません。- グループ
バインディングのコンシューマーグループ。受信バインディングにのみ適用されます。コンシューマーグループを参照してください。
デフォルト:
null(匿名のコンシューマーを示します)。- contentType
このバインディングのコンテンツ型。
Content Type Negotiationを参照してください。デフォルト:
application/json.- バインダー
このバインディングで使用されるバインダー。詳細については、
Multiple Binders on the Classpathを参照してください。デフォルト:
null(存在する場合はデフォルトのバインダーが使用されます)。
コンシューマープロパティ
これらのプロパティは、org.springframework.cloud.stream.binder.ConsumerProperties を介して公開されます
次のバインディングプロパティは、入力バインディングでのみ使用でき、接頭辞 spring.cloud.stream.bindings.<bindingName>.consumer. (たとえば、spring.cloud.stream.bindings.input.consumer.concurrency=3)を付ける必要があります。
デフォルト値は、spring.cloud.stream.default.consumer プレフィックス(たとえば、spring.cloud.stream.default.consumer.headerMode=none)を使用して設定できます。
- autoStartup
このコンシューマーを自動的に開始する必要があるかどうかを通知します
デフォルト:
true.- 並行性
受信コンシューマーの並行性。
デフォルト:
1.- パーティション化
コンシューマーがパーティション化されたプロデューサーからデータを受信するかどうか。
デフォルト:
false.- headerMode
noneに設定すると、入力時のヘッダー解析が無効になります。メッセージヘッダーをネイティブにサポートせず、ヘッダーの埋め込みを必要とするメッセージングミドルウェアにのみ有効です。このオプションは、ネイティブヘッダーがサポートされていないときに、Spring 以外のクラウドストリームアプリケーションからデータを消費する場合に役立ちます。headersに設定すると、ミドルウェアのネイティブヘッダーメカニズムを使用します。embeddedHeadersに設定すると、メッセージペイロードにヘッダーが埋め込まれます。デフォルト: バインダーの実装によって異なります。
- maxAttempts
処理が失敗した場合、メッセージの処理の試行回数(最初の試行を含む)。再試行を無効にするには、
1に設定します。デフォルト:
3.- backOffInitialInterval
再試行時のバックオフ初期間隔。
デフォルト:
1000.- backOffMaxInterval
最大バックオフ間隔。
デフォルト:
10000.- backOffMultiplier
バックオフ乗数。
デフォルト:
2.0.- defaultRetryable
retryableExceptionsにリストされていないリスナーによってスローされた例外が再試行可能かどうか。デフォルト:
true.- instanceCount
ゼロ以上の値に設定すると、このコンシューマーのインスタンス数をカスタマイズできます(
spring.cloud.stream.instanceCountと異なる場合)。負の値に設定すると、デフォルトでspring.cloud.stream.instanceCountになります。詳細については、Instance Index and Instance Countを参照してください。デフォルト:
-1.- instanceIndex
ゼロ以上の値に設定すると、このコンシューマーのインスタンスインデックスをカスタマイズできます(
spring.cloud.stream.instanceIndexと異なる場合)。負の値に設定すると、デフォルトでspring.cloud.stream.instanceIndexになります。instanceIndexListが提供されている場合は無視されます。詳細については、Instance Index and Instance Countを参照してください。デフォルト:
-1.- instanceIndexList
ネイティブパーティショニングをサポートしないバインダー(RabbitMQ など)で使用されます。アプリケーションインスタンスが複数のパーティションから消費できるようにします。
デフォルト: 空。
- retryableExceptions
キーの Throwable クラス名と値のブール値のマップ。再試行される、または再試行されない例外(およびサブクラス)を指定します。
defaultRetriableも参照してください。例:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false。デフォルト: 空。
- useNativeDecoding
trueに設定すると、受信メッセージはクライアントライブラリによって直接逆直列化されます。クライアントライブラリは、それに応じて構成する必要があります(たとえば、適切な Kafka プロデューサー値デシリアライザーを設定します)。この構成が使用されている場合、受信メッセージのマーシャリング解除は、バインディングのcontentTypeに基づいていません。ネイティブデコードを使用する場合、送信メッセージを直列化するために適切なエンコーダー(たとえば、Kafka プロデューサー値シリアライザー)を使用するのはプロデューサーの責任です。また、ネイティブのエンコードとデコードが使用されている場合、headerMode=embeddedHeadersプロパティは無視され、ヘッダーはメッセージに埋め込まれません。プロデューサープロパティuseNativeEncodingを参照してください。デフォルト:
false.- マルチプレックス
true に設定すると、基になるバインダーは同じ入力バインディングで宛先をネイティブに多重化します。
デフォルト:
false.
高度なコンシューマー構成
メッセージ駆動型コンシューマーの基になるメッセージリスナーコンテナーの高度な構成については、単一の ListenerContainerCustomizer Bean をアプリケーションコンテキストに追加します。上記のプロパティが適用された後に呼び出され、追加のプロパティを設定するために使用できます。同様に、ポーリングされたコンシューマーの場合は、MessageSourceCustomizer Bean を追加します。
以下は、RabbitMQ バインダーの例です。
@Bean
public ListenerContainerCustomizer<AbstractMessageListenerContainer> containerCustomizer() {
return (container, dest, group) -> container.setAdviceChain(advice1, advice2);
}
@Bean
public MessageSourceCustomizer<AmqpMessageSource> sourceCustomizer() {
return (source, dest, group) -> source.setPropertiesConverter(customPropertiesConverter);
}
プロデューサーのプロパティ
これらのプロパティは、org.springframework.cloud.stream.binder.ProducerProperties を介して公開されます
次のバインディングプロパティは、出力バインディングでのみ使用でき、接頭辞 spring.cloud.stream.bindings.<bindingName>.producer. (たとえば、spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=headers.id)を付ける必要があります。
デフォルト値は、プレフィックス spring.cloud.stream.default.producer (たとえば、spring.cloud.stream.default.producer.partitionKeyExpression=headers.id)を使用して設定できます。
- autoStartup
このコンシューマーを自動的に開始する必要があるかどうかを通知します
デフォルト:
true.- partitionKeyExpression
送信データを分割する方法を決定する SpEL 式。設定されている場合、このバインディングの送信データはパーティション化されます。
partitionCountを有効にするには、1 より大きい値に設定する必要があります。Partitioning Supportを参照してください。デフォルト: null。
- partitionKeyExtractorName
PartitionKeyExtractorStrategyを実装する Bean の名前。パーティション ID を計算するために使用されるキーを抽出するために使用されます ( "partitionSelector*" を参照)。"partitionKeyExpression" とは相互に排他的です。デフォルト: null。
- partitionSelectorName
PartitionSelectorStrategyを実装する Bean の名前。パーティションキーに基づいてパーティション ID を決定するために使用されます ( "partitionKeyExtractor*" を参照)。"partitionSelectorExpression" とは相互に排他的です。デフォルト: null。
- partitionSelectorExpression
パーティション選択をカスタマイズするための SpEL 式。どちらも設定されていない場合、パーティションは
hashCode(key) % partitionCountとして選択されます。ここで、keyはいずれかのpartitionKeyExpressionを介して計算されます。デフォルト:
null.- partitionCount
パーティショニングが有効になっている場合の、データのターゲットパーティションの数。プロデューサーがパーティション化されている場合は、1 より大きい値に設定する必要があります。Kafka では、ヒントとして解釈されます。代わりに、これとターゲットトピックのパーティション数の大きい方が使用されます。
デフォルト:
1.- requiredGroups
メッセージが作成された後に開始された場合でも、プロデューサーがメッセージ配信を保証する必要があるグループのコンマ区切りのリスト(たとえば、RabbitMQ で永続キューを事前に作成することによって)。
- headerMode
noneに設定すると、出力へのヘッダーの埋め込みが無効になります。これは、メッセージヘッダーをネイティブにサポートせず、ヘッダーの埋め込みを必要とするメッセージングミドルウェアにのみ有効です。このオプションは、ネイティブヘッダーがサポートされていない場合に、Spring 以外のクラウドストリームアプリケーションのデータを生成するときに役立ちます。headersに設定すると、ミドルウェアのネイティブヘッダーメカニズムを使用します。embeddedHeadersに設定すると、メッセージペイロードにヘッダーが埋め込まれます。デフォルト: バインダーの実装によって異なります。
- useNativeEncoding
trueに設定すると、送信メッセージはクライアントライブラリによって直接直列化されます。クライアントライブラリは、それに応じて構成する必要があります(たとえば、適切な Kafka プロデューサー値シリアライザーの設定)。この構成が使用されている場合、送信メッセージのマーシャリングはバインディングのcontentTypeに基づいていません。ネイティブエンコーディングを使用する場合、適切なデコーダー(たとえば、Kafka コンシューマー値デシリアライザー)を使用して受信メッセージをデシリアライズするのは、コンシューマーの責任です。また、ネイティブのエンコードとデコードが使用されている場合、headerMode=embeddedHeadersプロパティは無視され、ヘッダーはメッセージに埋め込まれません。コンシューマープロパティuseNativeDecodingを参照してください。デフォルト:
false.- errorChannelEnabled
true に設定すると、バインダーが非同期の送信結果をサポートしている場合、送信の失敗は宛先のエラーチャネルに送信されます。詳細については、エラー処理を参照してください。
デフォルト: false。
高度なプロデューサー構成
場合によっては、プロデューサープロパティでは、バインダーでプロデュース MessageHandler を適切に構成するのに十分ではない場合や、そのようなプロデュース MessageHandler を構成するときにプログラムによるアプローチを好む場合があります。理由に関係なく、spring-cloud-stream はそれを実現するために ProducerMessageHandlerCustomizer を提供します。
@FunctionalInterface
public interface ProducerMessageHandlerCustomizer<H extends MessageHandler> {
/**
* Configure a {@link MessageHandler} that is being created by the binder for the
* provided destination name.
* @param handler the {@link MessageHandler} from the binder.
* @param destinationName the bound destination name.
*/
void configure(H handler, String destinationName);
}
ご覧のとおり、必要に応じて構成できる MessageHandler を生成する実際のインスタンスにアクセスできます。必要なのは、この戦略の実装を提供し、それを @Bean として構成することだけです。
コンテンツ型の交渉
データ変換は、メッセージ駆動型マイクロサービスアーキテクチャのコア機能の 1 つです。Spring Cloud Stream では、このようなデータは Spring Message として表されるため、メッセージは宛先に到達する前に目的の形状またはサイズに変換する必要がある場合があります。これは 2 つの理由で必要です:
受信メッセージの内容を、アプリケーションが提供するハンドラーの署名と一致するように変換します。
送信メッセージの内容をワイヤー形式に変換します。
ワイヤーフォーマットは通常 byte[] (Kafka および Rabbit バインダーに当てはまります)ですが、バインダーの実装によって制御されます。
Spring Cloud Stream では、メッセージ変換は org.springframework.messaging.converter.MessageConverter を使用して実行されます。
| 以下の詳細の補足として、次のブログ投稿 (英語) も読むことをお勧めします。 |
力学
コンテンツ型のネゴシエーションの背後にあるメカニズムと必要性をよりよく理解するために、例として次のメッセージハンドラーを使用して、非常に単純なユースケースを見ていきます。
public Function<Person, String> personFunction {..}
| 簡単にするために、これがアプリケーション内の唯一のハンドラー関数であると想定します(内部パイプラインがないと想定します)。 |
前の例に示されているハンドラーは、引数として Person オブジェクトを予期し、出力として String 型を生成します。フレームワークが受信 Message を引数としてこのハンドラーに渡すことに成功するには、Message 型のペイロードをワイヤー形式から Person 型に何らかの方法で変換する必要があります。つまり、フレームワークは適切な MessageConverter を見つけて適用する必要があります。これを実現するには、フレームワークにユーザーからの指示が必要です。これらの命令の 1 つは、ハンドラーメソッド自体のシグニチャー(Person 型)によってすでに提供されています。理論的には、それで十分なはずです(場合によってはそれで十分です)。ただし、ほとんどのユースケースでは、適切な MessageConverter を選択するために、フレームワークに追加の情報が必要です。その欠落している部分は contentType です。
Spring Cloud Stream は、contentType を(優先順に)定義するための 3 つのメカニズムを提供します。
HEADER :
contentTypeは、メッセージ自体を介して通信できます。contentTypeヘッダーを提供することにより、適切なMessageConverterを見つけて適用するために使用するコンテンツ型を宣言します。BINDING :
contentTypeは、spring.cloud.stream.bindings.input.content-typeプロパティを設定することにより、宛先バインディングごとに設定できます。プロパティ名の inputセグメントは、宛先の実際の名前(この場合は「入力」)に対応します。このアプローチでは、バインディングごとに、適切なMessageConverterを見つけて適用するために使用するコンテンツ型を宣言できます。DEFAULT :
contentTypeがMessageヘッダーまたはバインディングに存在しない場合、デフォルトのapplication/jsonコンテンツ型を使用して、適切なMessageConverterを見つけて適用します。
前述のように、上記のリストは、同点の場合の優先順位も示しています。例: ヘッダーで提供されるコンテンツ型は、他のどのコンテンツ型よりも優先されます。同じことがバインディングごとに設定されたコンテンツ型にも当てはまります。これにより、基本的にデフォルトのコンテンツ型を上書きできます。ただし、実用的なデフォルトも提供します(これはコミュニティのフィードバックから決定されました)。
application/json をデフォルトにする別の理由は、プロデューサーとコンシューマーが異なる JVM で実行されるだけでなく、異なる非 JVM プラットフォームでも実行できる分散マイクロサービスアーキテクチャによって駆動される相互運用性要件に起因します。
非 void ハンドラーメソッドが返されるときに、戻り値がすでに Message である場合、その Message がペイロードになります。ただし、戻り値が Message でない場合、新しい Message は、入力 Message からヘッダーを継承し、SpringIntegrationProperties.messageHandlerNotPropagatedHeaders によって定義またはフィルタリングされたヘッダーを差し引いたものをペイロードとして、戻り値を使用して作成されます。デフォルトでは、そこに設定されているヘッダーは contentType の 1 つだけです。これは、新しい Message に contentType ヘッダーが設定されていないため、contentType を確実に進化させることができることを意味します。ハンドラーメソッドから Message を返すことをいつでもオプトアウトできます。ここで、任意のヘッダーを挿入できます。
内部パイプラインがある場合、Message は、同じ変換プロセスを経て次のハンドラーに送信されます。ただし、内部パイプラインがない場合、パイプラインの最後に到達した場合、Message は出力先に送り返されます。
コンテンツ型と引数型
前述のように、フレームワークが適切な MessageConverter を選択するには、引数の型と、オプションでコンテンツ型の情報が必要です。適切な MessageConverter を選択するロジックは、引数リゾルバー (HandlerMethodArgumentResolvers) にあります。引数リゾルバーは、ユーザー定義のハンドラーメソッドの呼び出しの直前 (フレームワークが実際の引数の型を認識しているとき) にトリガーされます。引数の型が現在のペイロードの型と一致しない場合、フレームワークは、事前構成された MessageConverters のスタックに委譲して、そのいずれかがペイロードを変換できるかどうかを確認します。ご覧のとおり、MessageConverter の Object fromMessage(Message<?> message, Class<?> targetClass); 操作は、引数の 1 つとして targetClass を受け取ります。また、フレームワークは、提供された Message に常に contentType ヘッダーが含まれるようにします。contentType ヘッダーがまだ存在しない場合は、バインディングごとの contentType ヘッダーまたは既定の contentType ヘッダーのいずれかを挿入します。contentType 引数型の組み合わせは、フレームワークがメッセージをターゲット型に変換できるかどうかを判断するメカニズムです。適切な MessageConverter が見つからない場合は例外がスローされますが、カスタム MessageConverter (User-defined Message Converters を参照) を追加することでこれを処理できます。
しかし、ペイロード型がハンドラーメソッドによって宣言されたターゲット型と一致する場合はどうなるでしょうか? この場合、変換するものはなく、ペイロードは変更されずに渡されます。これは非常に単純で論理的に聞こえますが、Message<?> または Object を引数として取るハンドラーメソッドを覚えておいてください。ターゲット型を Object (Java ではすべて instanceof)であると宣言することにより、変換プロセスは本質的に失われます。
Message が contentType のみに基づいて他の型に変換されることを期待しないでください。contentType はターゲット型を補完することを忘れないでください。必要に応じて、MessageConverter が考慮に入れる場合と考慮しない場合があるヒントを提供できます。 |
メッセージコンバーター
MessageConverters は、次の 2 つのメソッドを定義します。
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<?> toMessage(Object payload, @Nullable MessageHeaders headers);
特に Spring Cloud Stream のコンテキストでは、これらのメソッドの契約とその使用箇所を理解することが重要です。
fromMessage メソッドは、入力された Message を引数の型に変換します。Message のペイロードは任意の型でよく、複数の型をサポートするかどうかは MessageConverter の実際の実装次第です。例: ある JSON コンバーターはペイロードの型を byte[], String, その他としてサポートするかもしれません。これは、アプリケーションが内部パイプライン (入力 → handler1 → handler2 → ... → 出力) を持ち、上流のハンドラーの出力が Message であり、最初のワイヤーフォーマットでない可能性がある場合に重要です。
ただし、toMessage メソッドにはより厳密な契約があり、常に Message をワイヤ形式 byte[] に変換する必要があります。
すべての目的と目的で(特に、独自のコンバーターを実装する場合)、2 つのメソッドは次のシグネチャーを持っていると見なします。
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<byte[]> toMessage(Object payload, @Nullable MessageHeaders headers);
提供された MessageConverters
前述のように、フレームワークは、最も一般的なユースケースを処理するための MessageConverters のスタックをすでに提供しています。次のリストは、提供された MessageConverters を優先順に説明しています(最初に機能する MessageConverter が使用されます)。
JsonMessageConverter: 名前が示すように、contentTypeがapplication/json(DEFAULT) の場合に、Messageのペイロードと POJO の間の変換をサポートします。ByteArrayMessageConverter:contentTypeがapplication/octet-streamの場合に、Messageのペイロードをbyte[]からbyte[]に変換することをサポートします。これは本質的にパススルーであり、主に下位互換性のために存在します。ObjectStringMessageConverter:contentTypeがtext/plainの場合、任意の型のStringへの変換をサポートします。オブジェクトのtoString()メソッドを呼び出すか、ペイロードがbyte[]の場合は、新しいString(byte[])を呼び出します。
適切なコンバーターが見つからない場合、フレームワークは例外をスローします。その場合は、コードと構成をチェックして、何も見逃していないことを確認する必要があります(つまり、バインディングまたはヘッダーを使用して contentType を提供したことを確認してください)。ただし、ほとんどの場合、いくつかのまれなケース(おそらく、カスタム contentType など)が見つかり、提供されている MessageConverters の現在のスタックは変換方法を認識していません。その場合は、カスタム MessageConverter を追加できます。ユーザー定義のメッセージコンバーターを参照してください。
ユーザー定義のメッセージコンバーター
Spring Cloud Stream は、追加の MessageConverter を定義および登録するメカニズムを公開します。これを使用するには、org.springframework.messaging.converter.MessageConverter を実装し、@Bean として構成します。その後、MessageConverter の既存のスタックに追加されます。
カスタム MessageConverter 実装が既存のスタックの先頭に追加されることを理解することが重要です。その結果、カスタム MessageConverter 実装は既存の実装よりも優先され、既存のコンバーターをオーバーライドしたり、追加したりすることができます。 |
次の例は、application/bar と呼ばれる新しいコンテンツ型をサポートするメッセージコンバーター Bean を作成する方法を示しています。
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter customMessageConverter() {
return new MyCustomMessageConverter();
}
}
public class MyCustomMessageConverter extends AbstractMessageConverter {
public MyCustomMessageConverter() {
super(new MimeType("application", "bar"));
}
@Override
protected boolean supports(Class<?> clazz) {
return (Bar.class.equals(clazz));
}
@Override
protected Object convertFromInternal(Message<?> message, Class<?> targetClass, Object conversionHint) {
Object payload = message.getPayload();
return (payload instanceof Bar ? payload : new Bar((byte[]) payload));
}
}
アプリケーション間通信
Spring Cloud Stream は、アプリケーション間の通信を可能にします。次のトピックで説明するように、アプリケーション間の通信は、いくつかの関心事にまたがる複雑な課題です。
複数のアプリケーションインスタンスを接続する
Spring Cloud Stream を使用すると、個々の Spring Boot アプリケーションをメッセージングシステムに簡単に接続できますが、Spring Cloud Stream の一般的なシナリオは、マイクロサービスアプリケーションが相互にデータを送信するマルチアプリケーションパイプラインの作成です。このシナリオは、「隣接する」アプリケーションの入力先と出力先を相互に関連付けることで実現できます。
設計がタイムソースアプリケーションにデータをログシンクアプリケーションに送信することを要求するとします。両方のアプリケーション内のバインディングには、ticktock という名前の共通の宛先を使用できます。
Time Source(output という名前のバインディングを持つ)は、次のプロパティを設定します。
spring.cloud.stream.bindings.output.destination=ticktock
Log Sink(input という名前のバインディングを持つ)は、次のプロパティを設定します。
spring.cloud.stream.bindings.input.destination=ticktock
インスタンスインデックスとインスタンス数
Spring Cloud Stream アプリケーションをスケールアップすると、各インスタンスは、同じアプリケーションの他のインスタンスがいくつ存在するか、およびそれ自体のインスタンスインデックスが何であるかに関する情報を受け取ることができます。Spring Cloud Stream は、spring.cloud.stream.instanceCount および spring.cloud.stream.instanceIndex プロパティを介してこれを行います。例: HDFS シンクアプリケーションのインスタンスが 3 つある場合、3 つのインスタンスすべてで spring.cloud.stream.instanceCount が 3 に設定され、個々のアプリケーションで spring.cloud.stream.instanceIndex がそれぞれ 0、1、2 に設定されます。
Spring Cloud Stream アプリケーションが Spring Cloud Data Flow を介してデプロイされると、これらのプロパティは自動的に構成されます。Spring Cloud Stream アプリケーションを個別に起動する場合は、これらのプロパティを正しく設定する必要があります。デフォルトでは、spring.cloud.stream.instanceCount は 1 であり、spring.cloud.stream.instanceIndex は 0 です。
スケールアップされたシナリオでは、これら 2 つのプロパティの正しい構成は、一般にパーティショニング動作(以下を参照)に対処するために重要であり、データを確保するために、特定のバインダー(Kafka バインダーなど)では常に 2 つのプロパティが必要です。複数のコンシューマーインスタンスに正しく分割されます。
パーティショニング
Spring Cloud Stream でのパーティショニングは、次の 2 つのタスクで構成されます。
パーティション化のための出力バインディングの構成
partitionKeyExpression または partitionKeyExtractorName プロパティの 1 つだけと、partitionCount プロパティを設定することにより、パーティション化されたデータを送信するように出力バインディングを構成できます。
例: 以下は、有効で一般的な構成です。
spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=headers.id spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
その設定例に基づいて、次のロジックを使用してデータがターゲットパーティションに送信されます。
パーティションキーの値は、partitionKeyExpression に基づいてパーティション化された出力バインディングに送信されるメッセージごとに計算されます。partitionKeyExpression は、パーティショニングキーを抽出するために送信メッセージ(前の例ではメッセージヘッダーからの id の値)に対して評価される SpEL 式です。
SpEL 式がニーズに十分でない場合は、代わりに org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy の実装を提供し、それを Bean として構成することによって(@Bean アノテーションを使用して)パーティションキー値を計算できます。アプリケーションコンテキストで使用可能な型 org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy の Bean が複数ある場合は、次の例に示すように、partitionKeyExtractorName プロパティで名前を指定することにより、さらにフィルタリングできます。
--spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExtractorName=customPartitionKeyExtractor
--spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
. . .
@Bean
public CustomPartitionKeyExtractorClass customPartitionKeyExtractor() {
return new CustomPartitionKeyExtractorClass();
} 以前のバージョンの Spring Cloud Stream では、spring.cloud.stream.bindings.output.producer.partitionKeyExtractorClass プロパティを設定することにより、org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy の実装を指定できました。バージョン 3.0 以降、このプロパティは削除されています。 |
メッセージキーが計算されると、パーティション選択プロセスは、ターゲットパーティションを 0 と partitionCount - 1 の間の値として決定します。ほとんどのシナリオに適用できるデフォルトの計算は、次の式に基づいています: key.hashCode() % partitionCount。これは、(partitionSelectorExpression プロパティを介して)「キー」に対して評価される SpEL 式を設定するか、(@Bean アノテーションを使用して)Bean として org.springframework.cloud.stream.binder.PartitionSelectorStrategy の実装を構成することにより、バインディングでカスタマイズできます。次の例に示すように、PartitionKeyExtractorStrategy と同様に、この型の Bean がアプリケーションコンテキストで複数使用できる場合は、spring.cloud.stream.bindings.output.producer.partitionSelectorName プロパティを使用してさらにフィルタリングできます。
--spring.cloud.stream.bindings.func-out-0.producer.partitionSelectorName=customPartitionSelector
. . .
@Bean
public CustomPartitionSelectorClass customPartitionSelector() {
return new CustomPartitionSelectorClass();
} 以前のバージョンの Spring Cloud Stream では、spring.cloud.stream.bindings.output.producer.partitionSelectorClass プロパティを設定することにより、org.springframework.cloud.stream.binder.PartitionSelectorStrategy の実装を指定できました。バージョン 3.0 以降、このプロパティは削除されています。 |
パーティショニング用の入力バインディングの構成
次の例に示すように、入力バインディング(バインディング名 uppercase-in-0)は、その partitioned プロパティ、およびアプリケーション自体の instanceIndex プロパティと instanceCount プロパティを設定することにより、パーティション化されたデータを受信するように構成されます。
spring.cloud.stream.bindings.uppercase-in-0.consumer.partitioned=true spring.cloud.stream.instanceIndex=3 spring.cloud.stream.instanceCount=5
instanceCount 値は、データを分割する必要があるアプリケーションインスタンスの総数を表します。instanceIndex は、0 と instanceCount - 1 の間の値で、複数のインスタンス間で一意の値である必要があります。インスタンスインデックスは、各アプリケーションインスタンスがデータを受信する一意のパーティションを識別できます。これは、ネイティブにパーティショニングをサポートしないテクノロジーを使用するバインダーに必要です。例: RabbitMQ では、各パーティションにキューがあり、キュー名にはインスタンスインデックスが含まれています。Kafka では、autoRebalanceEnabled が true (デフォルト)の場合、Kafka がインスタンス間でのパーティションの分散を処理し、これらのプロパティは必要ありません。autoRebalanceEnabled が false に設定されている場合、instanceCount と instanceIndex は、インスタンスがサブスクライブするパーティションを決定するためにバインダーによって使用されます(少なくともインスタンスと同じ数のパーティションが必要です)。バインダーは、Kafka の代わりにパーティションを割り当てます。これは、特定のパーティションのメッセージを常に同じインスタンスに送信する場合に役立つことがあります。バインダー構成で必要な場合は、すべてのデータが消費され、アプリケーションインスタンスが相互に排他的なデータセットを受け取るようにするために、両方の値を正しく設定することが重要です。
パーティション化されたデータ処理に複数のインスタンスを使用するシナリオは、スタンドアロンの場合のセットアップが複雑になる可能性がありますが、Spring Cloud Dataflow は、入力値と出力値の両方を正しく入力し、ランタイムインフラストラクチャに依存して提供できるようにすることで、プロセスを大幅に簡素化できます。インスタンスインデックスとインスタンスカウントに関する情報。
テスト
Spring Cloud Stream は、メッセージングシステムに接続せずにマイクロサービスアプリケーションをテストするためのサポートを提供します。
Spring Integration テストバインダー
Spring Cloud Stream には、実際のバインダー実装やメッセージブローカーを必要とせずに、さまざまなアプリケーションコンポーネントをテストするために使用できるテストバインダーが付属しています。
このテストバインダーは、単体テストと統合テスト間のブリッジとして機能し、JVM 内メッセージブローカーとして Spring Integration フレームワークに基づいており、本質的に両方の長所を提供します。つまり、ネットワークのない実際のバインダーです。
バインダー構成のテスト
Spring Integration テストバインダーを有効にするには、それを依存関係として追加するだけです。
必須依存関係を追加
以下は、必要な Maven POM エントリの例です。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-test-binder</artifactId>
<scope>test</scope>
</dependency>または build.gradle.kts の場合
testImplementation("org.springframework.cloud:spring-cloud-stream-test-binder")
バインダーの使用箇所をテストする
これで、マイクロサービスを簡単な単体テストとしてテストできます
@SpringBootTest
public class SampleStreamTests {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Test
public void testEmptyConfiguration() {
this.input.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(output.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
@SpringBootApplication
@Import(TestChannelBinderConfiguration.class)
public static class SampleConfiguration {
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
}
また、より詳細な制御が必要な場合、同じテストスイートで複数の構成をテストする場合は、次の操作も実行できます。
@EnableAutoConfiguration
public static class MyTestConfiguration {
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
. . .
@Test
public void sampleTest() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
MyTestConfiguration.class))
.run("--spring.cloud.function.definition=uppercase")) {
InputDestination source = context.getBean(InputDestination.class);
OutputDestination target = context.getBean(OutputDestination.class);
source.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(target.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
}
複数のバインディングや複数の入力と出力がある場合、または単に送受信する宛先の名前を明示したい場合は、InputDestination と OutputDestination の send() メソッドと receive() メソッドをオーバーライドして、提供できるようにします。入力および出力先の名前。
次のサンプルについて考えてみます。
@EnableAutoConfiguration
public static class SampleFunctionConfiguration {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Bean
public Function<String, String> reverse() {
return value -> new StringBuilder(value).reverse().toString();
}
}
そして実際のテスト
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleFunctionConfiguration.class))
.run("--spring.cloud.function.definition=uppercase;reverse")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "uppercase-in-0");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "uppercase-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
destination などの追加のマッピングプロパティがある場合は、それらの名前を使用する必要があります。例: uppercase 関数の入力と出力を myInput および myOutput バインディング名に明示的にマップする前述のテストの別のバージョンを検討してください。
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleFunctionConfiguration.class))
.run(
"--spring.cloud.function.definition=uppercase;reverse",
"--spring.cloud.stream.bindings.uppercase-in-0.destination=myInput",
"--spring.cloud.stream.bindings.uppercase-out-0.destination=myOutput"
)) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "myInput");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "myOutput");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
テストバインダーと PollableMessageSource
Spring Integration Test Binder を使用すると、PollableMessageSource を使用するときにテストを作成することもできます(詳細については、ポーリングされたコンシューマーの使用を参照してください)。
ただし、理解する必要がある重要なことは、ポーリングはイベント駆動型ではなく、PollableMessageSource は、メッセージ(単数)を生成(ポーリング)する操作を公開する戦略であるということです。ポーリングする頻度、使用するスレッドの数、ポーリング元(メッセージキューまたはファイルシステム)は完全にあなた次第です。言い換えると、ポーラーやスレッド、または実際のメッセージのソースを構成するのはユーザーの責任です。幸いなことに、Spring には、それを正確に構成するための抽象化がたくさんあります。
例を見てみましょう:
@Test
public void samplePollingTest() {
ApplicationContext context = new SpringApplicationBuilder(SamplePolledConfiguration.class)
.web(WebApplicationType.NONE)
.run("--spring.jmx.enabled=false", "--spring.cloud.stream.pollable-source=myDestination");
OutputDestination destination = context.getBean(OutputDestination.class);
System.out.println("Message 1: " + new String(destination.receive().getPayload()));
System.out.println("Message 2: " + new String(destination.receive().getPayload()));
System.out.println("Message 3: " + new String(destination.receive().getPayload()));
}
@Import(TestChannelBinderConfiguration.class)
@EnableAutoConfiguration
public static class SamplePolledConfiguration {
@Bean
public ApplicationRunner poller(PollableMessageSource polledMessageSource, StreamBridge output, TaskExecutor taskScheduler) {
return args -> {
taskScheduler.execute(() -> {
for (int i = 0; i < 3; i++) {
try {
if (!polledMessageSource.poll(m -> {
String newPayload = ((String) m.getPayload()).toUpperCase();
output.send("myOutput", newPayload);
})) {
Thread.sleep(2000);
}
}
catch (Exception e) {
// handle failure
}
}
});
};
}
}
上記の (非常に初歩的な) 例は、2 秒間隔で 3 つのメッセージを生成し、Source の出力先に送信します。このメッセージは、このバインダーが OutputDestination に送信し、そこで取得します (アサーションの場合)。現在、次のように出力されます。
Message 1: POLLED DATA
Message 2: POLLED DATA
Message 3: POLLED DATA ご覧のとおり、データは同じです。これは、このバインダーが実際の MessageSource のデフォルトの実装(poll() 操作を使用してメッセージがポーリングされるソース)を定義しているためです。ほとんどのテストシナリオには十分ですが、独自の MessageSource を定義したい場合があります。これを行うには、テスト構成で型 MessageSource の Bean を構成し、メッセージソーシングの独自の実装を提供します。
次に例を示します。
@Bean
public MessageSource<?> source() {
return () -> new GenericMessage<>("My Own Data " + UUID.randomUUID());
}
次の出力をレンダリングします。
Message 1: MY OWN DATA 1C180A91-E79F-494F-ABF4-BA3F993710DA
Message 2: MY OWN DATA D8F3A477-5547-41B4-9434-E69DA7616FEE
Message 3: MY OWN DATA 20BF2E64-7FF4-4CB6-A823-4053D30B5C74 この Bean messageSource には、無関係な理由で Spring Boot によって提供される同じ名前(異なる型)の Bean と競合するため、名前を付けないでください。 |
テスト用のテストバインダーと通常のミドルウェアバインダーの混合に関する特別な注意事項
Spring Integration ベースのテストバインダーは、Kafka や RabbitMQ バインダーなどの実際のミドルウェアベースのバインダーを使用せずにアプリケーションをテストするために提供されています。上のセクションで説明したように、テストバインダーは、メモリ内の Spring Integration チャネルに依存して、アプリケーションの動作を迅速に検証できます。テストクラスパス上にテストバインダーが存在する場合、Spring Cloud Stream は、通信にバインダーが必要な場合はどこでも、すべてのテスト目的でこのバインダーを使用しようとします。つまり、同じモジュール内にテスト目的でテストバインダーと通常のミドルウェアバインダーの両方を混在させることはできません。テストバインダーを使用してアプリケーションをテストした後、実際のミドルウェアバインダーを使用してさらに統合テストを継続したい場合は、実際のバインダーを使用するテストを別のモジュールに追加して、それらのテストが適切な接続を確立できるようにすることをお勧めします。テストバインダーによって提供されるメモリ内チャネルに依存するのではなく、実際のミドルウェアを使用します。
ヘルス指標
Spring Cloud Stream は、バインダーのヘルスインジケーターを提供します。binders という名前で登録されており、management.health.binders.enabled プロパティを設定することで有効または無効にできます。
ヘルスチェックを有効にするには、まず、依存関係を含めて "Web" と「アクチュエーター」の両方を有効にする必要があります。( 結合の視覚化と制御を参照してください)
management.health.binders.enabled がアプリケーションによって明示的に設定されていない場合、management.health.defaults.enabled は true として照合され、バインダーヘルスインジケーターが有効になります。ヘルスインジケータを完全に無効にする場合は、management.health.binders.enabled を false に設定する必要があります。
Spring Boot アクチュエーターヘルスエンドポイントを使用して、ヘルスインジケータ(/actuator/health)にアクセスできます。デフォルトでは、上記のエンドポイントに到達したときにのみ、最上位のアプリケーションステータスを受け取ります。バインダー固有のヘルスインジケーターから完全な詳細を受け取るには、アプリケーションに値 ALWAYS のプロパティ management.endpoint.health.show-details を含める必要があります。
ヘルスインジケーターはバインダー固有であり、特定のバインダーの実装は必ずしもヘルスインジケーターを提供するとは限りません。
すぐに使用できるすべてのヘルスインジケーターを完全に無効にし、代わりに独自のヘルスインジケーターを提供する場合は、プロパティ management.health.binders.enabled を false に設定してから、アプリケーションで独自の HealthIndicator Bean を提供します。この場合、Spring Boot のヘルスインジケーターインフラストラクチャは引き続きこれらのカスタム Bean を取得します。バインダーヘルスインジケーターを無効にしていない場合でも、すぐに使用できるヘルスチェックに加えて独自の HealthIndicator Bean を提供することで、ヘルスチェックを強化できます。
同じアプリケーションに複数のバインダーがある場合、アプリケーションが management.health.binders.enabled を false に設定してオフにしない限り、ヘルスインジケーターはデフォルトで有効になっています。この場合、ユーザーがバインダーのサブセットのヘルスチェックを無効にする場合は、マルチバインダー構成の環境で management.health.binders.enabled を false に設定することによって行う必要があります。環境固有のプロパティを提供する方法の詳細については、複数のシステムへの接続を参照してください。
クラスパスに複数のバインダーが存在するが、それらのすべてがアプリケーションで使用されているわけではない場合、これはヘルスインジケーターのコンテキストでいくつかの課題を引き起こす可能性があります。ヘルスチェックの実行方法に関して、実装固有の詳細がある場合があります。例: バインダーによって登録された宛先がない場合、Kafka バインダーはステータスを DOWN として決定する場合があります。
具体的な状況を見てみましょう。クラスパスに Kafka と Kafka Streams バインダーの両方が存在するが、アプリケーションコードでは Kafka Streams バインダーのみを使用する、つまり Kafka Streams バインダーを使用するバインディングのみを提供するとします。Kafka バインダーは使用されておらず、宛先が登録されているかどうかを確認するための特定のチェックがあるため、バインダーのヘルスチェックは失敗します。トップレベルのアプリケーションヘルスチェックステータスは DOWN として報告されます。この状況では、kafka バインダーを使用していないため、アプリケーションから依存関係を削除するだけで済みます。
サンプル
Spring Cloud Stream サンプルについては、GitHub の spring-cloud-stream-samples (英語) リポジトリを参照してください。
CloudFoundry へのストリームアプリケーションのデプロイ
CloudFoundry では、サービスは通常、VCAP_SERVICES (英語) と呼ばれる特別な環境変数を介して公開されます。
バインダー接続を構成するときは、データフロー Cloud Foundry サーバー (英語) のドキュメントに従って、環境変数の値を使用できます。
バインダーの実装
以下は、利用可能なバインダー実装のリストです
前に記述されていたように、バインダーの抽象化もフレームワークの拡張ポイントの 1 つです。上記のリストで適切なバインダーが見つからない場合は、Spring Cloud Stream の上に独自のバインダーを実装できます。Spring Cloud Stream バインダーを最初から作成する方法 (英語) で、コミュニティメンバーのドキュメントを詳細に投稿します。例として、カスタムバインダーを実装するために必要な一連の手順を示します。手順は、Implementing Custom Binders セクションでも強調表示されています。