Step の構成
ドメインの章で説明したように、 Step は、バッチジョブの独立したシーケンシャルフェーズをカプセル化するドメインオブジェクトであり、実際のバッチ処理を定義および制御するために必要なすべての情報を含みます。与えられた Step の内容は Job を記述する開発者の裁量にあるため、これは必然的に曖昧な記述です。Step は、開発者が望むほど単純でも複雑でもかまいません。単純な Step は、ファイルからデータベースにデータをロードし、コードをほとんどまたはまったく必要としない場合があります(使用する実装によって異なります)。次の図に示すように、より複雑な Step には、処理の一部として適用される複雑なビジネスルールがある場合があります。

チャンク指向の処理
Spring Batch は、最も一般的な実装内で「チャンク指向」の処理スタイルを使用します。チャンク指向の処理とは、データを一度に 1 つずつ読み取り、トランザクション境界内に書き出される「チャンク」を作成することです。読み取られたアイテムの数がコミット間隔と等しくなると、チャンク全体が ItemWriter によって書き出され、トランザクションがコミットされます。次のイメージはプロセスを示しています。

次の擬似コードは、同じ概念を簡略化した形式で示しています。
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read();
if (item != null) {
items.add(item);
}
}
itemWriter.write(items); オプションの ItemProcessor を使用してチャンク指向のステップを構成し、アイテムを ItemWriter に渡す前に処理することもできます。次のイメージは、ItemProcessor がステップで登録されたときのプロセスを示しています。
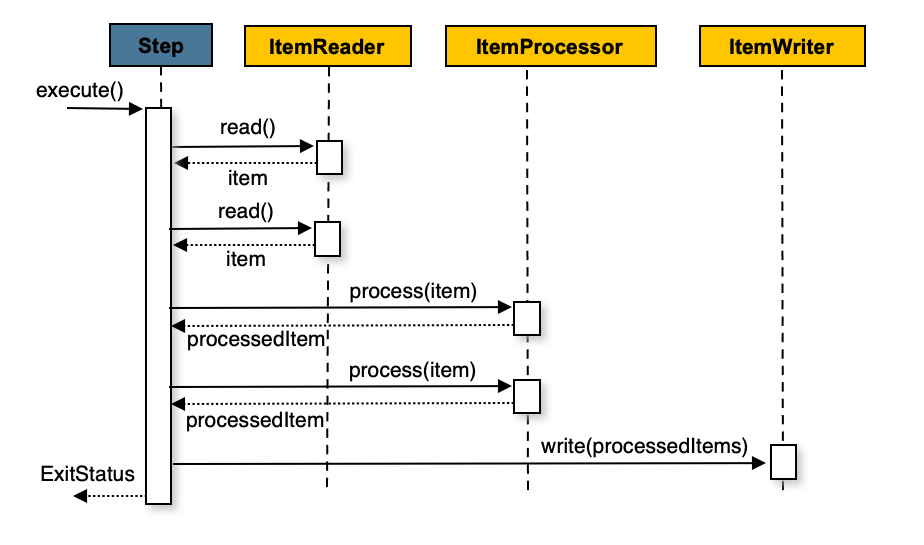
次の擬似コードは、これが簡略化された形式でどのように実装されるかを示しています。
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read();
if (item != null) {
items.add(item);
}
}
List processedItems = new Arraylist();
for(Object item: items){
Object processedItem = itemProcessor.process(item);
if (processedItem != null) {
processedItems.add(processedItem);
}
}
itemWriter.write(processedItems);アイテムプロセッサーとその使用例の詳細については、アイテム処理セクションを参照してください。
Step の構成
Step に必要な依存関係の比較的短いリストにもかかわらず、これは非常に複雑なクラスであり、多くの協力者を潜在的に含むことができます。
構成を簡単にするために、次の例に示すように、Spring Batch XML 名前空間を使用できます。
<job id="sampleJob" job-repository="jobRepository">
<step id="step1">
<tasklet transaction-manager="transactionManager">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job>Java 構成を使用する場合、次の例に示すように、Spring Batch ビルダーを使用できます。
/**
* Note the JobRepository is typically autowired in and not needed to be explicitly
* configured
*/
@Bean
public Job sampleJob(JobRepository jobRepository, Step sampleStep) {
return this.jobBuilderFactory.get("sampleJob")
.repository(jobRepository)
.start(sampleStep)
.build();
}
/**
* Note the TransactionManager is typically autowired in and not needed to be explicitly
* configured
*/
@Bean
public Step sampleStep(PlatformTransactionManager transactionManager) {
return this.stepBuilderFactory.get("sampleStep")
.transactionManager(transactionManager)
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.build();
}上記の構成には、アイテム指向のステップを作成するために必要な依存関係のみが含まれています。
reader: 処理するアイテムを提供するItemReader。writer:ItemReaderによって提供されるアイテムを処理するItemWriter。
transaction-manager: Spring のPlatformTransactionManagerは、処理中にトランザクションを開始およびコミットします。
transactionManager: Spring のPlatformTransactionManagerは、処理中にトランザクションを開始およびコミットします。
job-repository: 処理中(コミットの直前)にStepExecutionおよびExecutionContextを定期的に格納するJobRepositoryの XML 固有の名前。インライン<step/>(<job/>内で定義されたもの)の場合、これは<job/>要素の属性です。スタンドアロン<step/>の場合、これは <tasklet/> の属性として定義されます。
repository: 処理中(コミット直前)にStepExecutionおよびExecutionContextを定期的に保管するJobRepositoryの Java 固有の名前。
commit-interval: トランザクションがコミットされる前に処理されるアイテムの数の XML 固有の名前。
chunk: これがアイテムベースのステップであることを示す依存関係の Java 固有の名前と、トランザクションがコミットされる前に処理されるアイテムの数。
job-repository のデフォルトは jobRepository であり、transaction-manager のデフォルトは transactionManager であることに注意してください。また、ItemProcessor はオプションです。これは、アイテムをリーダーからライターに直接渡すことができるためです。
repository のデフォルトは jobRepository であり、transactionManager のデフォルトは transactionManager であることに注意してください(すべて @EnableBatchProcessing からインフラストラクチャを通じて提供されます)。また、ItemProcessor はオプションです。これは、アイテムをリーダーからライターに直接渡すことができるためです。
親 Step からの継承
Steps のグループが同様の構成を共有する場合、具体的な Steps がプロパティを継承できる「親」 Step を定義すると役立つ場合があります。Java のクラス継承と同様に、「子」 Step はその要素と属性を親のものと組み合わせます。子は、親の Steps のいずれもオーバーライドします。
次の例では、Step である "concreteStep1" は "parentStep" から継承されます。これは、"itemReader"、"itemProcessor"、"itemWriter"、" startLimit=5"、" allowStartIfComplete=true" でインスタンス化されます。さらに、次の例に示すように、commitInterval は "concreteStep1" の Step によってオーバーライドされるため、"5" になります。
<step id="parentStep">
<tasklet allow-start-if-complete="true">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
<step id="concreteStep1" parent="parentStep">
<tasklet start-limit="5">
<chunk processor="itemProcessor" commit-interval="5"/>
</tasklet>
</step>id 属性は、ジョブ要素内のステップで引き続き必要です。これには 2 つの理由があります。
idは、StepExecutionを永続化する際のステップ名として使用されます。同じスタンドアロンステップがジョブの複数のステップで参照されている場合、エラーが発生します。
この章で後述するように、ジョブフローを作成する場合、
next属性は、スタンドアロンステップではなく、フロー内のステップを参照する必要があります。
抽象 Step
場合によっては、完全な Step 構成ではない親 Step を定義する必要があります。たとえば、reader、writer、tasklet 属性が Step 構成から除外されている場合、初期化は失敗します。これらのプロパティなしで親を定義する必要がある場合は、abstract 属性を使用する必要があります。abstract Step は拡張されるだけで、インスタンス化されることはありません。
次の例では、Step abstractParentStep は抽象として宣言されていない場合はインスタンス化されません。Step ( "concreteStep2" ) には、"itemReader"、"itemWriter"、commit-interval=10 があります。
<step id="abstractParentStep" abstract="true">
<tasklet>
<chunk commit-interval="10"/>
</tasklet>
</step>
<step id="concreteStep2" parent="abstractParentStep">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"/>
</tasklet>
</step>リストのマージ
Steps の構成可能な要素の一部は、<listeners/> 要素などのリストです。親と子の両方の Steps が <listeners/> 要素を宣言する場合、子のリストが親のリストをオーバーライドします。子が親によって定義されたリストに追加のリスナーを追加できるようにするために、すべてのリスト要素には merge 属性があります。要素が merge="true" を指定している場合、子のリストはオーバーライドするのではなく、親のリストと結合されます。
次の例では、Step "concreteStep3" が 2 つのリスナー listenerOne と listenerTwo で作成されます。
<step id="listenersParentStep" abstract="true">
<listeners>
<listener ref="listenerOne"/>
<listeners>
</step>
<step id="concreteStep3" parent="listenersParentStep">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="5"/>
</tasklet>
<listeners merge="true">
<listener ref="listenerTwo"/>
<listeners>
</step>コミット間隔
前述のように、ステップはアイテムを読み書きし、提供された PlatformTransactionManager を使用して定期的にコミットします。commit-interval が 1 の場合、個々のアイテムを書き込んだ後にコミットされます。トランザクションの開始とコミットにはコストがかかるため、これは多くの状況で理想的とは言えません。理想的には、各トランザクションでできるだけ多くのアイテムを処理することが望ましいです。これは、処理されるデータの型とステップが相互作用するリソースに完全に依存します。このため、コミット内で処理されるアイテムの数を構成できます。
次の例は、tasklet の XML で定義されている commit-interval 値が 10 である step を示しています。
<job id="sampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job> 次の例は、tasklet の commit-interval 値が Java で定義されている 10 である step を示しています。
@Bean
public Job sampleJob() {
return this.jobBuilderFactory.get("sampleJob")
.start(step1())
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.build();
} 上記の例では、各トランザクション内で 10 個のアイテムが処理されます。処理の開始時に、トランザクションが開始されます。また、read が ItemReader で呼び出されるたびに、カウンターが増分されます。10 に達すると、集約されたアイテムのリストが ItemWriter に渡され、トランザクションがコミットされます。
再起動のための Step の構成
"ジョブの構成と実行" セクションでは、Job の再起動について説明しました。再起動は手順に多数の影響を与えるため、特定の構成が必要になる場合があります。
開始制限の設定
Step を開始できる回数を制御する必要があるシナリオは多数あります。例: 特定の Step は、1 度だけ実行されるように構成する必要がある場合があります。これは、実行する前に手動で修正する必要があるリソースを無効にするためです。ステップごとに要件が異なる可能性があるため、これはステップレベルで設定可能です。一度しか実行できない Step は、無限に実行できる Step と同じ Job の一部として存在できます。
次のコードフラグメントは、XML での開始制限設定の例を示しています。
<step id="step1">
<tasklet start-limit="1">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>次のコードフラグメントは、Java での開始制限設定の例を示しています。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.startLimit(1)
.build();
} 前の例で示したステップは、1 回だけ実行できます。再度実行しようとすると、StartLimitExceededException がスローされます。start-limit のデフォルト値は Integer.MAX_VALUE であることに注意してください。
完了した Step の再起動
再起動可能なジョブの場合、最初に成功したかどうかに関係なく、常に実行する必要がある 1 つ以上のステップが存在する場合があります。例としては、検証ステップや、処理前にリソースをクリーンアップする Step があります。再開されたジョブの通常の処理中、ステータスが "COMPLETED" のステップは、すでに正常に完了しているため、スキップされます。allow-start-if-complete を "true" に設定すると、これが上書きされるため、ステップは常に実行されます。
次のコードは、再起動可能なジョブを XML で定義する方法を示しています。
<step id="step1">
<tasklet allow-start-if-complete="true">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>次のコードフラグメントは、Java で再起動可能なジョブを定義する方法を示しています。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.allowStartIfComplete(true)
.build();
}Step 再起動の構成例
次の XML の例は、再起動可能なステップを持つようにジョブを構成する方法を示しています。
<job id="footballJob" restartable="true">
<step id="playerload" next="gameLoad">
<tasklet>
<chunk reader="playerFileItemReader" writer="playerWriter"
commit-interval="10" />
</tasklet>
</step>
<step id="gameLoad" next="playerSummarization">
<tasklet allow-start-if-complete="true">
<chunk reader="gameFileItemReader" writer="gameWriter"
commit-interval="10"/>
</tasklet>
</step>
<step id="playerSummarization">
<tasklet start-limit="2">
<chunk reader="playerSummarizationSource" writer="summaryWriter"
commit-interval="10"/>
</tasklet>
</step>
</job>次の Java の例は、再起動可能なステップを持つようにジョブを構成する方法を示しています。
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}
@Bean
public Step playerLoad() {
return this.stepBuilderFactory.get("playerLoad")
.<String, String>chunk(10)
.reader(playerFileItemReader())
.writer(playerWriter())
.build();
}
@Bean
public Step gameLoad() {
return this.stepBuilderFactory.get("gameLoad")
.allowStartIfComplete(true)
.<String, String>chunk(10)
.reader(gameFileItemReader())
.writer(gameWriter())
.build();
}
@Bean
public Step playerSummarization() {
return this.stepBuilderFactory.get("playerSummarization")
.startLimit(2)
.<String, String>chunk(10)
.reader(playerSummarizationSource())
.writer(summaryWriter())
.build();
} 上記の構成例は、フットボールの試合に関する情報を読み込んで要約するジョブ用です。playerLoad、gameLoad、playerSummarization の 3 つのステップが含まれています。playerLoad ステップはフラットファイルからプレーヤー情報をロードしますが、gameLoad ステップはゲームでも同じことを行います。最後のステップである playerSummarization は、提供されたゲームに基づいて、各プレーヤーの統計を要約します。playerLoad によってロードされるファイルは、一度だけロードする必要があると想定されていますが、gameLoad は、特定のディレクトリ内で見つかったすべてのゲームをロードし、データベースに正常にロードされた後で削除できます。その結果、playerLoad ステップには追加の構成が含まれていません。何度でも開始でき、完了した場合はスキップされます。ただし、gameLoad ステップは、最後の実行以降に追加のファイルが追加された場合に備えて、毎回実行する必要があります。常に開始するために、"allow-start-if-complete" が "true" に設定されています。(要約ステップで新しいゲームを適切に見つけることができるように、ゲームがロードされるデータベーステーブルにはプロセスインジケーターがあると想定されています)。ジョブで最も重要な要約ステップは、開始制限が 2 になるように構成されています。これは、ステップが継続的に失敗した場合に、ジョブの実行を制御するオペレーターに新しい終了コードが返されるため便利です。手動による介入が行われるまで、再開しないでください。
このジョブはこのドキュメントの例を提供するものであり、サンプルプロジェクトで見つかった |
このセクションの残りの部分では、footballJob の例の 3 つの実行のそれぞれで何が起こるかを説明します。
実行 1:
playerLoadが正常に実行および完了し、400 人のプレイヤーが "PLAYERS" テーブルに追加されます。gameLoadは 11 ファイルのゲームデータを実行および処理し、その内容を "GAMES" テーブルにロードします。playerSummarizationは処理を開始し、5 分後に失敗します。
実行 2:
playerLoadはすでに正常に完了しており、allow-start-if-completeは 'false' (デフォルト)であるため、実行されません。gameLoadが再度実行され、別の 2 つのファイルを処理し、それらのコンテンツを "GAMES" テーブルにもロードします(まだ処理されていないことを示すプロセスインジケーターを使用)。playerSummarizationは残りのすべてのゲームデータの処理(プロセスインジケーターを使用したフィルター処理)を開始し、30 分後に再び失敗します。
実行 3:
playerLoadはすでに正常に完了しており、allow-start-if-completeは 'false' (デフォルト)であるため、実行されません。gameLoadが再度実行され、別の 2 つのファイルを処理し、それらのコンテンツを "GAMES" テーブルにもロードします(まだ処理されていないことを示すプロセスインジケーターを使用)。これは
playerSummarizationの 3 回目の実行であり、その制限は 2 のみであるため、playerSummarizationは開始されず、ジョブは直ちに強制終了されます。制限を上げるか、Jobを新しいJobInstanceとして実行する必要があります。
スキップロジックの構成
処理中に発生したエラーが Step の失敗につながるべきではなく、代わりにスキップする必要があるシナリオが数多くあります。これは通常、データ自体とその意味を理解している人が下さなければならない決定です。たとえば、財務データは、送金されることになり、完全に正確である必要があるため、スキップできない場合があります。一方、ベンダーのリストをロードすると、スキップが許可される場合があります。ベンダーが正しくフォーマットされていないか、必要な情報が欠落していたためにベンダーがロードされない場合、おそらく課題はありません。通常、これらの不良レコードも記録されます。これについては、後でリスナーについて説明するときに説明します。
次の XML の例は、スキップ制限の使用例を示しています。
<step id="step1">
<tasklet>
<chunk reader="flatFileItemReader" writer="itemWriter"
commit-interval="10" skip-limit="10">
<skippable-exception-classes>
<include class="org.springframework.batch.item.file.FlatFileParseException"/>
</skippable-exception-classes>
</chunk>
</tasklet>
</step>次の Java の例は、スキップ制限の使用例を示しています。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(flatFileItemReader())
.writer(itemWriter())
.faultTolerant()
.skipLimit(10)
.skip(FlatFileParseException.class)
.build();
} 前の例では、FlatFileItemReader が使用されています。いずれかの時点で FlatFileParseException がスローされると、アイテムはスキップされ、合計スキップ制限 10 に対してカウントされます。宣言された例外(およびそのサブクラス)は、チャンク処理(読み取り、処理、書き込み)の任意の段階でスローされる可能性があります)ただし、ステップ実行内での読み取り、処理、書き込みのスキップについては個別のカウントが行われますが、制限はすべてのスキップに適用されます。スキップ制限に達すると、次に検出された例外が原因でステップが失敗します。つまり、10 回目ではなく 11 回目のスキップが例外をトリガーします。
前の例の 1 つの問題は、FlatFileParseException 以外のその他の例外が原因で Job が失敗することです。特定のシナリオでは、これが正しい動作である場合があります。ただし、他のシナリオでは、どの例外が失敗の原因であるかを特定し、他のすべてをスキップする方が簡単な場合があります。
次の XML の例は、特定の例外を除く例を示しています。
<step id="step1">
<tasklet>
<chunk reader="flatFileItemReader" writer="itemWriter"
commit-interval="10" skip-limit="10">
<skippable-exception-classes>
<include class="java.lang.Exception"/>
<exclude class="java.io.FileNotFoundException"/>
</skippable-exception-classes>
</chunk>
</tasklet>
</step>次の Java の例は、特定の例外を除外する例を示しています。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(flatFileItemReader())
.writer(itemWriter())
.faultTolerant()
.skipLimit(10)
.skip(Exception.class)
.noSkip(FileNotFoundException.class)
.build();
}java.lang.Exception をスキップ可能な例外クラスとして識別することにより、構成はすべての Exceptions がスキップ可能であることを示します。ただし、java.io.FileNotFoundException を「除外」することにより、構成はスキップ可能な例外クラスのリストを、FileNotFoundException を除くすべての Exceptions に絞り込みます。除外された例外クラスは、検出されると致命的です(つまり、スキップされません)。
例外が発生した場合、スキップ可能性はクラス階層内の最も近いスーパークラスによって決定されます。未分類の例外はすべて「致命的」として扱われます。
<include/> および <exclude/> エレメントの順序は重要ではありません。
skip および noSkip メソッド呼び出しの順序は重要ではありません。
再試行ロジックの構成
ほとんどの場合、例外によってスキップまたは Step 障害のいずれかが発生します。ただし、すべての例外が確定的であるとは限りません。読み取り中に FlatFileParseException が検出されると、そのレコードに対して常にスローされます。ItemReader をリセットしても効果はありません。ただし、DeadlockLoserDataAccessException などの他の例外の場合、現在のプロセスが、別のプロセスがロックを保持しているレコードを更新しようとしたことを示します。待機して再試行すると、成功する可能性があります。
XML では、再試行は次のように構成する必要があります。
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"
commit-interval="2" retry-limit="3">
<retryable-exception-classes>
<include class="org.springframework.dao.DeadlockLoserDataAccessException"/>
</retryable-exception-classes>
</chunk>
</tasklet>
</step>Java では、再試行は次のように構成する必要があります。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.retryLimit(3)
.retry(DeadlockLoserDataAccessException.class)
.build();
}Step は、個々のアイテムを再試行できる回数の制限と、「再試行可能な」例外のリストを許可します。どのように再試行作品の詳細はで見つけることができ、再試行。
ロールバックの制御
デフォルトでは、再試行またはスキップに関係なく、ItemWriter からスローされた例外により、Step によって制御されるトランザクションがロールバックされます。前述のようにスキップが構成されている場合、ItemReader からスローされた例外によってロールバックが発生することはありません。ただし、トランザクションを無効にするアクションが実行されていないため、ItemWriter からスローされた例外がロールバックを引き起こすべきでない多くのシナリオがあります。このため、Step は、ロールバックを引き起こしてはならない例外のリストを使用して構成できます。
XML では、次のようにロールバックを制御できます。
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
<no-rollback-exception-classes>
<include class="org.springframework.batch.item.validator.ValidationException"/>
</no-rollback-exception-classes>
</tasklet>
</step>Java では、次のようにロールバックを制御できます。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.noRollback(ValidationException.class)
.build();
}トランザクションリーダー
ItemReader の基本契約は、フォワードのみであるというものです。ステップはリーダー入力をバッファーに入れるため、ロールバックの場合、アイテムをリーダーから再度読み取る必要はありません。ただし、JMS キューなどのトランザクションリソースの上にリーダーが構築される特定のシナリオがあります。この場合、キューはロールバックされるトランザクションに関連付けられているため、キューからプルされたメッセージは元に戻されます。このため、アイテムをバッファリングしないようにステップを構成できます。
次の例は、XML のアイテムをバッファリングしないリーダーを作成する方法を示しています。
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"
is-reader-transactional-queue="true"/>
</tasklet>
</step>次の例は、Java でアイテムをバッファリングしないリーダーを作成する方法を示しています。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.readerIsTransactionalQueue()
.build();
}トランザクション属性
トランザクション属性を使用して、isolation、propagation、timeout 設定を制御できます。トランザクション属性の設定の詳細については、Spring コアドキュメントを参照してください。
次の例では、isolation、propagation、timeout トランザクション属性を XML で設定します。
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
<transaction-attributes isolation="DEFAULT"
propagation="REQUIRED"
timeout="30"/>
</tasklet>
</step> 次の例では、Java で isolation、propagation、timeout トランザクション属性を設定します。
@Bean
public Step step1() {
DefaultTransactionAttribute attribute = new DefaultTransactionAttribute();
attribute.setPropagationBehavior(Propagation.REQUIRED.value());
attribute.setIsolationLevel(Isolation.DEFAULT.value());
attribute.setTimeout(30);
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.transactionAttribute(attribute)
.build();
}ItemStream を Step に登録する
このステップでは、ライフサイクルの必要な時点で ItemStream コールバックを処理する必要があります(ItemStream インターフェースの詳細については、ItemStream を参照してください)。ItemStream インターフェースは実行間の永続的な状態について必要な情報を取得する場所であるため、これはステップが失敗して再起動する必要がある場合に不可欠です。
ItemReader、ItemProcessor、ItemWriter 自体が ItemStream インターフェースを実装している場合、これらは自動的に登録されます。その他のストリームは個別に登録する必要があります。これは、デリゲートなどの間接的な依存関係がリーダーとライターに挿入される場合によくあります。ストリームは、'stream' 要素を介して step に登録できます。
次の例は、stream を step に XML で登録する方法を示しています。
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="compositeWriter" commit-interval="2">
<streams>
<stream ref="fileItemWriter1"/>
<stream ref="fileItemWriter2"/>
</streams>
</chunk>
</tasklet>
</step>
<beans:bean id="compositeWriter"
class="org.springframework.batch.item.support.CompositeItemWriter">
<beans:property name="delegates">
<beans:list>
<beans:ref bean="fileItemWriter1" />
<beans:ref bean="fileItemWriter2" />
</beans:list>
</beans:property>
</beans:bean> 次の例は、Java で step に stream を登録する方法を示しています。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(compositeItemWriter())
.stream(fileItemWriter1())
.stream(fileItemWriter2())
.build();
}
/**
* In Spring Batch 4, the CompositeItemWriter implements ItemStream so this isn't
* necessary, but used for an example.
*/
@Bean
public CompositeItemWriter compositeItemWriter() {
List<ItemWriter> writers = new ArrayList<>(2);
writers.add(fileItemWriter1());
writers.add(fileItemWriter2());
CompositeItemWriter itemWriter = new CompositeItemWriter();
itemWriter.setDelegates(writers);
return itemWriter;
} 上記の例では、CompositeItemWriter は ItemStream ではありませんが、両方のデリゲートはそうです。フレームワークがデリゲートライターを適切に処理するには、両方のデリゲートライターをストリームとして明示的に登録する必要があります。ItemReader は、Step の直接的なプロパティであるため、ストリームとして明示的に登録する必要はありません。これでステップは再開可能になり、障害が発生してもリーダーとライターの状態は正しく保持されます。
Step 実行のインターセプト
Job の場合と同様に、Step の実行中には、ユーザーが何らかの機能を実行する必要のある多くのイベントがあります。例: フッターを必要とするフラットファイルに書き出すには、Step が完了したときに ItemWriter に通知して、フッターを書き込めるようにする必要があります。これは、多くの Step スコープリスナーの 1 つで実現できます。
StepListener の拡張機能の 1 つを実装するクラス(ただし、そのインターフェース自体は空であるため)は、listeners 要素を介してステップに適用できます。listeners 要素は、ステップ、タスクレット、チャンク宣言内で有効です。リスナーは、その機能が適用されるレベルで宣言するか、マルチ機能(StepExecutionListener や ItemReadListener など)の場合は、適用される最も細かいレベルで宣言することをお勧めします。
次の例は、XML のチャンクレベルで適用されるリスナーを示しています。
<step id="step1">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="10"/>
<listeners>
<listener ref="chunkListener"/>
</listeners>
</tasklet>
</step>次の例は、Java のチャンクレベルで適用されるリスナーを示しています。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(reader())
.writer(writer())
.listener(chunkListener())
.build();
} 名前空間 <step> エレメントまたは *StepFactoryBean ファクトリの 1 つを使用する場合、StepListener インターフェースの 1 つを実装する ItemReader、ItemWriter、ItemProcessor は、Step に自動的に登録されます。これは、Step に直接注入されたコンポーネントにのみ適用されます。リスナーが別のコンポーネント内にネストされている場合は、明示的に登録する必要があります(前述の ItemStream を Step に登録するで説明)。
StepListener インターフェースに加えて、同じ関心事に対処するためのアノテーションが提供されています。プレーンな古い Java オブジェクトには、これらのアノテーションを持つメソッドがあり、対応する StepListener 型に変換されます。ItemReader または ItemWriter または Tasklet などのチャンクコンポーネントのカスタム実装にアノテーションを付けることも一般的です。アノテーションは、<listener/> 要素の XML パーサーによって分析され、ビルダーの listener メソッドに登録されます。そのため、XML 名前空間またはビルダーを使用して、リスナーをステップに登録するだけです。
StepExecutionListener
StepExecutionListener は、Step 実行の最も一般的なリスナーを表します。次の例に示すように、Step が正常に終了したか失敗したかに関係なく、Step が開始される前と終了した後に通知を許可します。
public interface StepExecutionListener extends StepListener {
void beforeStep(StepExecution stepExecution);
ExitStatus afterStep(StepExecution stepExecution);
}ExitStatus は、リスナーが Step の完了時に返される終了コードを変更できるようにするための、afterStep の戻り型です。
このインターフェースに対応するアノテーションは次のとおりです。
@BeforeStep@AfterStep
ChunkListener
チャンクは、トランザクションのスコープ内で処理されるアイテムとして定義されます。各コミット間隔でトランザクションをコミットすると、「チャンク」がコミットされます。ChunkListener を使用して、次のインターフェース定義に示すように、チャンクの処理を開始する前、またはチャンクが正常に完了した後にロジックを実行できます。
public interface ChunkListener extends StepListener {
void beforeChunk(ChunkContext context);
void afterChunk(ChunkContext context);
void afterChunkError(ChunkContext context);
}beforeChunk メソッドは、トランザクションが開始された後、ItemReader で read が呼び出される前に呼び出されます。逆に、afterChunk はチャンクがコミットされた後に呼び出されます (ロールバックがある場合は呼び出されません)。
このインターフェースに対応するアノテーションは次のとおりです。
@BeforeChunk@AfterChunk@AfterChunkError
チャンク宣言がない場合、ChunkListener を適用できます。TaskletStep は ChunkListener の呼び出しを担当するため、アイテム指向ではないタスクレットにも適用されます(タスクレットの前後に呼び出されます)。
ItemReadListener
前にスキップロジックについて説明したときに、スキップされたレコードをログに記録して、後で処理できるようにすることが有益であると述べました。読み取りエラーの場合、これは、次のインターフェース定義に示すように、ItemReaderListener で実行できます。
public interface ItemReadListener<T> extends StepListener {
void beforeRead();
void afterRead(T item);
void onReadError(Exception ex);
}beforeRead メソッドは、各呼び出しの前に ItemReader を読み取るために呼び出されます。afterRead メソッドは、読み取りの呼び出しが成功するたびに呼び出され、読み取られたアイテムを渡します。読み取り中にエラーが発生した場合、onReadError メソッドが呼び出されます。発生した例外はログに記録できるように提供されます。
このインターフェースに対応するアノテーションは次のとおりです。
@BeforeRead@AfterRead@OnReadError
ItemProcessListener
ItemReadListener の場合と同様に、次のインターフェース定義に示すように、アイテムの処理を「聞く」ことができます。
public interface ItemProcessListener<T, S> extends StepListener {
void beforeProcess(T item);
void afterProcess(T item, S result);
void onProcessError(T item, Exception e);
}beforeProcess メソッドは、ItemProcessor の process の前に呼び出され、処理されるアイテムに渡されます。afterProcess メソッドは、アイテムが正常に処理された後に呼び出されます。処理中にエラーが発生した場合、onProcessError メソッドが呼び出されます。発生した例外と処理が試行されたアイテムが提供されるため、ログに記録できます。
このインターフェースに対応するアノテーションは次のとおりです。
@BeforeProcess@AfterProcess@OnProcessError
ItemWriteListener
次のインターフェース定義に示すように、アイテムの書き込みは ItemWriteListener を使用して「リスニング」できます。
public interface ItemWriteListener<S> extends StepListener {
void beforeWrite(List<? extends S> items);
void afterWrite(List<? extends S> items);
void onWriteError(Exception exception, List<? extends S> items);
}beforeWrite メソッドは、ItemWriter の write の前に呼び出され、書き込まれたアイテムのリストを渡します。afterWrite メソッドは、アイテムが正常に書き込まれた後に呼び出されます。書き込み中にエラーが発生した場合、onWriteError メソッドが呼び出されます。発生した例外と書き込みが試行されたアイテムが提供されるため、ログに記録できます。
このインターフェースに対応するアノテーションは次のとおりです。
@BeforeWrite@AfterWrite@OnWriteError
SkipListener
ItemReadListener、ItemProcessListener、ItemWriteListener はすべて、エラーを通知するためのメカニズムを提供しますが、レコードが実際にスキップされたことを通知するものはありません。たとえば、onWriteError は、アイテムが再試行されて成功した場合でも呼び出されます。このため、次のインターフェース定義に示すように、スキップされたアイテムを追跡するための個別のインターフェースがあります。
public interface SkipListener<T,S> extends StepListener {
void onSkipInRead(Throwable t);
void onSkipInProcess(T item, Throwable t);
void onSkipInWrite(S item, Throwable t);
}onSkipInRead は、読み取り中にアイテムがスキップされるたびに呼び出されます。ロールバックにより、同じアイテムが複数回スキップされて登録される可能性があることに注意してください。onSkipInWrite は、書き込み中にアイテムがスキップされると呼び出されます。項目は正常に読み取られた(スキップされなかった)ため、引数として項目自体も提供されます。
このインターフェースに対応するアノテーションは次のとおりです。
@OnSkipInRead@OnSkipInWrite@OnSkipInProcess
SkipListeners とトランザクション
SkipListener の最も一般的な使用例の 1 つは、スキップされたアイテムをログアウトすることです。これにより、別のバッチプロセスまたはヒューマンプロセスを使用して、スキップにつながる課題を評価および修正できます。元のトランザクションがロールバックされる場合が多いため、Spring Batch は 2 つの保証を行います。
適切な skip メソッド(エラーがいつ発生したかによる)は、アイテムごとに 1 回だけ呼び出されます。
SkipListenerは、トランザクションがコミットされる直前に常に呼び出されます。これは、リスナーによって呼び出されるトランザクションリソースがItemWriter内の障害によってロールバックされないようにするためです。
TaskletStep
チャンク指向の処理は、Step で処理する唯一の方法ではありません。Step が単純なストアドプロシージャコールで構成されている場合はどうなるでしょうか? 呼び出しを ItemReader として実装し、プロシージャの終了後に null を返すことができます。ただし、何もしない ItemWriter が必要になるため、そうするのは少し不自然です。Spring Batch は、このシナリオの TaskletStep を提供します。
Tasklet は、execute という 1 つのメソッドを持つ単純なインターフェースです。execute は、RepeatStatus.FINISHED を返すか、例外をスローして失敗を通知するまで、TaskletStep によって繰り返し呼び出されます。Tasklet への各呼び出しは、トランザクションにラップされます。Tasklet 実装者は、ストアドプロシージャ、スクリプト、単純な SQL 更新ステートメントを呼び出す場合があります。
XML で TaskletStep を作成するには、<tasklet/> 要素の 'ref' 属性が、Tasklet オブジェクトを定義する Bean を参照する必要があります。<tasklet/> 内で <chunk/> 要素を使用しないでください。次の例は、単純なタスクレットを示しています。
<step id="step1">
<tasklet ref="myTasklet"/>
</step>Java で TaskletStep を作成するには、ビルダーの tasklet メソッドに渡される Bean が Tasklet インターフェースを実装する必要があります。TaskletStep をビルドするときは、chunk の呼び出しを行わないでください。次の例は、単純なタスクレットを示しています。
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.tasklet(myTasklet())
.build();
}
|
TaskletAdapter
ItemReader および ItemWriter インターフェース用の他のアダプターと同様に、Tasklet インターフェースには、既存のクラス TaskletAdapter にそれ自体を適応させることができる実装が含まれています。これが役立つ可能性のある例は、一連のレコードのフラグを更新するために使用される既存の DAO です。TaskletAdapter を使用して、Tasklet インターフェースのアダプターを作成せずにこのクラスを呼び出すことができます。
次の例は、TaskletAdapter を XML で定義する方法を示しています。
<bean id="myTasklet" class="o.s.b.core.step.tasklet.MethodInvokingTaskletAdapter">
<property name="targetObject">
<bean class="org.mycompany.FooDao"/>
</property>
<property name="targetMethod" value="updateFoo" />
</bean> 次の例は、Java で TaskletAdapter を定義する方法を示しています。
@Bean
public MethodInvokingTaskletAdapter myTasklet() {
MethodInvokingTaskletAdapter adapter = new MethodInvokingTaskletAdapter();
adapter.setTargetObject(fooDao());
adapter.setTargetMethod("updateFoo");
return adapter;
}Tasklet の実装例
多くのバッチジョブには、さまざまなリソースをセットアップするためにメイン処理を開始する前、またはそれらのリソースをクリーンアップするための処理が完了した後に実行する必要があるステップが含まれています。ファイルを頻繁に処理するジョブの場合、特定のファイルを別の場所に正常にアップロードした後、特定のファイルをローカルで削除する必要がしばしばあります。次の例(Spring Batch サンプルプロジェクト [GitHub] (英語) から取得)は、まさにそのような責任を持つ Tasklet 実装です。
public class FileDeletingTasklet implements Tasklet, InitializingBean {
private Resource directory;
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
File dir = directory.getFile();
Assert.state(dir.isDirectory());
File[] files = dir.listFiles();
for (int i = 0; i < files.length; i++) {
boolean deleted = files[i].delete();
if (!deleted) {
throw new UnexpectedJobExecutionException("Could not delete file " +
files[i].getPath());
}
}
return RepeatStatus.FINISHED;
}
public void setDirectoryResource(Resource directory) {
this.directory = directory;
}
public void afterPropertiesSet() throws Exception {
Assert.notNull(directory, "directory must be set");
}
} 上記の tasklet 実装は、指定されたディレクトリ内のすべてのファイルを削除します。execute メソッドは 1 回だけ呼び出されることに注意してください。あとは step から tasklet を参照するだけです。
次の例は、step から tasklet を XML で参照する方法を示しています。
<job id="taskletJob">
<step id="deleteFilesInDir">
<tasklet ref="fileDeletingTasklet"/>
</step>
</job>
<beans:bean id="fileDeletingTasklet"
class="org.springframework.batch.sample.tasklet.FileDeletingTasklet">
<beans:property name="directoryResource">
<beans:bean id="directory"
class="org.springframework.core.io.FileSystemResource">
<beans:constructor-arg value="target/test-outputs/test-dir" />
</beans:bean>
</beans:property>
</beans:bean> 次の例は、Java で step から tasklet を参照する方法を示しています。
@Bean
public Job taskletJob() {
return this.jobBuilderFactory.get("taskletJob")
.start(deleteFilesInDir())
.build();
}
@Bean
public Step deleteFilesInDir() {
return this.stepBuilderFactory.get("deleteFilesInDir")
.tasklet(fileDeletingTasklet())
.build();
}
@Bean
public FileDeletingTasklet fileDeletingTasklet() {
FileDeletingTasklet tasklet = new FileDeletingTasklet();
tasklet.setDirectoryResource(new FileSystemResource("target/test-outputs/test-dir"));
return tasklet;
}ステップフローの制御
所有するジョブ内でステップをグループ化する機能を使用すると、ジョブが 1 つのステップから別のステップに「流れる」方法を制御できるようにする必要があります。Step の失敗は、必ずしも Job が失敗することを意味しません。さらに、次に実行する Step を決定する「成功」の型が複数存在する場合があります。Steps のグループの構成方法によっては、特定のステップがまったく処理されないこともあります。
シーケンシャルフロー
最も単純なフローシナリオは、次の図に示すように、すべてのステップが順番に実行されるジョブです。

これは、step の「次」を使用することで実現できます。
次の例は、XML で next 属性を使用する方法を示しています。
<job id="job">
<step id="stepA" parent="s1" next="stepB" />
<step id="stepB" parent="s2" next="stepC"/>
<step id="stepC" parent="s3" />
</job> 次の例は、Java で next() メソッドを使用する方法を示しています。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(stepA())
.next(stepB())
.next(stepC())
.build();
} 上記のシナリオでは、最初にリストされる Step であるため、「ステップ A」が最初に実行されます。「ステップ A」が正常に完了すると、「ステップ B」が実行されます。ただし、「ステップ A」が失敗すると、Job 全体が失敗し、「ステップ B」は実行されません。
Spring Batch XML 名前空間では、構成にリストされている最初のステップは、常に |
条件付きフロー
上記の例では、2 つの可能性しかありません。
stepは成功し、次のstepを実行する必要があります。stepは失敗したため、jobは失敗するはずです。
多くの場合、これで十分です。しかし、step の障害が障害を引き起こすのではなく、異なる step をトリガーするシナリオについてはどうでしょうか? 次の図は、このようなフローを示しています。

より複雑なシナリオを処理するために、Spring Batch XML 名前空間では、遷移要素をステップ要素内で定義できます。そのような遷移の 1 つが next 要素です。next 属性と同様に、next 要素は Job に次に実行する Step を指示します。ただし、属性とは異なり、特定の Step で任意の数の next 要素を使用でき、失敗した場合のデフォルトの動作はありません。つまり、遷移要素を使用する場合、Step 遷移のすべての動作を明示的に定義する必要があります。また、1 つのステップに next 属性と transition 要素の両方を含めることはできません。
next 要素は、次の例に示すように、照合するパターンと次に実行するステップを指定します。
<job id="job">
<step id="stepA" parent="s1">
<next on="*" to="stepB" />
<next on="FAILED" to="stepC" />
</step>
<step id="stepB" parent="s2" next="stepC" />
<step id="stepC" parent="s3" />
</job>Java API は、フローとステップが失敗したときに何をするかを指定できる一連の流れるようなメソッドを提供します。次の例は、stepA が成功するかどうかに応じて、1 つのステップ(stepA)を指定してから、2 つの異なるステップ(stepB および stepC)のいずれかに進む方法を示しています。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(stepA())
.on("*").to(stepB())
.from(stepA()).on("FAILED").to(stepC())
.end()
.build();
}XML 構成を使用する場合、遷移要素の on 属性は、単純なパターンマッチングスキームを使用して、Step の実行から生じる ExitStatus を照合します。
java 構成を使用する場合、on() メソッドは、単純なパターンマッチングスキームを使用して、Step の実行結果である ExitStatus と一致します。
パターンでは 2 つの特殊文字のみが許可されます。
"*" はゼロ個以上の文字に一致します
"?" 正確に 1 文字に一致します
例: "c * t" は "cat" および "count" に一致しますが、「c ? t」は "cat" に一致しますが、"count" には一致しません。
Step の遷移要素の数に制限はありませんが、Step の実行により ExitStatus が要素でカバーされない場合、フレームワークは例外をスローし、Job は失敗します。フレームワークは、最も具体的なものから最も具体的なものへの遷移を自動的に順序付けます。これは、上記の例で順序が "stepA" と入れ替わった場合でも、"FAILED" の ExitStatus は "stepC" に移動することを意味します。
バッチステータスと終了ステータス
条件付きフロー用に Job を構成する場合、BatchStatus と ExitStatus の違いを理解することが重要です。BatchStatus は、JobExecution と StepExecution の両方のプロパティである列挙であり、Job または Step のステータスを記録するためにフレームワークによって使用されます。次の値のいずれかです: COMPLETED、STARTING、STARTED、STOPPING、STOPPED、FAILED、ABANDONED または UNKNOWN。それらのほとんどは自明です。COMPLETED は、ステップまたはジョブが正常に完了したときに設定されるステータスであり、FAILED は失敗したときに設定される、などです。
次の例には、XML 構成を使用する場合の 'next' 要素が含まれています。
<next on="FAILED" to="stepB" />次の例には、Java 構成を使用する場合の 'on' 要素が含まれています。
...
.from(stepA()).on("FAILED").to(stepB())
... 一見すると、"on" は所属する Step の BatchStatus を参照しているように見えます。ただし、実際には Step の ExitStatus を参照します。名前が示すように、ExitStatus は Step の実行完了後のステータスを表します。
より具体的には、XML 構成を使用する場合、前述の XML 構成例に示されている 'next' 要素は ExitStatus の終了コードを参照します。
Java 構成を使用する場合、前述の Java 構成例に示されている "on()" メソッドは ExitStatus の終了コードを参照します。
英語で言うと: 「終了コードが FAILED の場合、stepB に進みます」。デフォルトでは、終了コードは Step の BatchStatus と常に同じであるため、上記のエントリが機能します。ただし、終了コードを変更する必要がある場合はどうなるでしょうか? 良い例は、サンプルプロジェクト内のサンプルジョブをスキップすることから得られます。
次の例は、XML で別の終了コードを操作する方法を示しています。
<step id="step1" parent="s1">
<end on="FAILED" />
<next on="COMPLETED WITH SKIPS" to="errorPrint1" />
<next on="*" to="step2" />
</step>次の例は、Java で別の終了コードを操作する方法を示しています。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1()).on("FAILED").end()
.from(step1()).on("COMPLETED WITH SKIPS").to(errorPrint1())
.from(step1()).on("*").to(step2())
.end()
.build();
}step1 には 3 つの可能性があります。
Stepが失敗しました。その場合、ジョブは失敗するはずです。Stepは正常に完了しました。Stepは正常に完了しましたが、終了コードは "COMPLETED WITH SKIPS" です。この場合、エラーを処理するために別のステップを実行する必要があります。
上記の構成は機能します。ただし、次の例に示すように、レコードをスキップした実行の条件に基づいて、終了コードを変更する必要があります。
public class SkipCheckingListener extends StepExecutionListenerSupport {
public ExitStatus afterStep(StepExecution stepExecution) {
String exitCode = stepExecution.getExitStatus().getExitCode();
if (!exitCode.equals(ExitStatus.FAILED.getExitCode()) &&
stepExecution.getSkipCount() > 0) {
return new ExitStatus("COMPLETED WITH SKIPS");
}
else {
return null;
}
}
} 上記のコードは、最初に Step が成功したことを確認し、次に StepExecution のスキップカウントが 0 より大きいかどうかを確認する StepExecutionListener です。両方の条件が満たされた場合、COMPLETED WITH SKIPS の終了コードを持つ新しい ExitStatus が返されます。
停止の構成
BatchStatus および ExitStatus の議論の後、BatchStatus と ExitStatus が Job のためにどう決定されるか不思議に思うかもしれません。Step のこれらのステータスは、実行されるコードによって決定されますが、Job のステータスは構成に基づいて決定されます。
これまでのところ、説明したすべてのジョブ構成には、遷移のない最終的な Step が少なくとも 1 つあります。
次の XML の例では、step が実行された後、Job が終了します。
<step id="stepC" parent="s3"/> 次の Java の例では、step が実行された後、Job が終了します。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.build();
}Step に遷移が定義されていない場合、Job のステータスは次のように定義されます。
StepがExitStatusFAILED で終了する場合、JobのBatchStatusとExitStatusは両方ともFAILEDです。それ以外の場合、
JobのBatchStatusとExitStatusは両方ともCOMPLETEDです。
バッチジョブを終了するこの方法は、単純な順次ステップジョブなどの一部のバッチジョブには十分ですが、カスタム定義のジョブ停止シナリオが必要になる場合があります。この目的のために、Spring Batch は、(前に説明した next 要素に加えて) Job を停止するための 3 つの遷移要素を提供します。これらの停止要素はそれぞれ、特定の BatchStatus で Job を停止します。停止遷移要素は、Job の Steps の BatchStatus または ExitStatus のいずれにも影響しないことに注意することが重要です。これらの要素は、Job の最終ステータスのみに影響します。例: ジョブ内のすべてのステップのステータスが FAILED であるが、ジョブのステータスが COMPLETED である可能性があります。
ステップで終了
ステップ終了を構成すると、Job が COMPLETED の BatchStatus で停止するように指示されます。ステータス COMPLETED で終了した Job は再起動できません(フレームワークは JobInstanceAlreadyCompleteException をスローします)。
XML 構成を使用する場合、'end' 要素がこのタスクに使用されます。end 要素は、Job の ExitStatus をカスタマイズするために使用できるオプションの 'exit-code' 属性も許可します。'exit-code' 属性が指定されていない場合、ExitStatus は BatchStatus と一致するようにデフォルトで COMPLETED になります。
Java 構成を使用する場合、このタスクには 'end' メソッドが使用されます。end メソッドでは、オプションの 'exitStatus' パラメーターも使用できます。これを使用して、Job の ExitStatus をカスタマイズできます。'exitStatus' 値が指定されていない場合、ExitStatus はデフォルトで BatchStatus と一致するように COMPLETED になります。
次のシナリオを検討してください: step2 に障害が発生した場合、Job は COMPLETED の BatchStatus で停止し、COMPLETED の ExitStatus および step3 は実行されません。それ以外の場合、実行は step3 に移動します。step2 に障害が発生した場合、Job は再起動できないことに注意してください(ステータスが COMPLETED であるため)。
次の例は、XML のシナリオを示しています。
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<end on="FAILED"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">次の例は、Java でのシナリオを示しています。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.next(step2())
.on("FAILED").end()
.from(step2()).on("*").to(step3())
.end()
.build();
}ステップの失敗
特定のポイントで失敗するようにステップを構成すると、Job が FAILED の BatchStatus で停止するように指示されます。終了とは異なり、Job の障害は Job の再起動を妨げません。
XML 構成を使用する場合、'fail' 要素では、Job の ExitStatus をカスタマイズするために使用できるオプションの 'exit-code' 属性も使用できます。'exit-code' 属性が指定されていない場合、ExitStatus はデフォルトで FAILED になり、BatchStatus と一致します。
step2 が失敗した場合、Job は FAILED の BatchStatus で停止し、EARLY TERMINATION の ExitStatus で停止し、step3 は実行されないという次のシナリオを検討してください。それ以外の場合、実行は step3 に移動します。さらに、step2 に障害が発生し、Job が再起動されると、step2 で実行が再開されます。
次の例は、XML のシナリオを示しています。
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<fail on="FAILED" exit-code="EARLY TERMINATION"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">次の例は、Java でのシナリオを示しています。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.next(step2()).on("FAILED").fail()
.from(step2()).on("*").to(step3())
.end()
.build();
}特定のステップでジョブを停止する
特定のステップで停止するようにジョブを構成すると、Job は STOPPED の BatchStatus で停止するように指示されます。Job を停止すると、処理が一時的に中断する可能性があるため、オペレーターは Job を再始動する前に何らかのアクションを取ることができます。
XML 構成を使用する場合、'stop' 要素には、ジョブの再開時に実行を開始するステップを指定する 'restart' 属性が必要です。
Java 構成を使用する場合、stopAndRestart メソッドには、ジョブの再開時に実行を開始するステップを指定する 'restart' 属性が必要です。
次のシナリオを検討してください: step1 が COMPLETE で終了した場合、ジョブは停止します。再起動すると、step2 で実行が開始されます。
次のリストは、XML でのシナリオを示しています。
<step id="step1" parent="s1">
<stop on="COMPLETED" restart="step2"/>
</step>
<step id="step2" parent="s2"/>次の例は、Java でのシナリオを示しています。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1()).on("COMPLETED").stopAndRestart(step2())
.end()
.build();
}プログラムによるフローの決定
状況によっては、次に実行するステップを決定するために、ExitStatus よりも多くの情報が必要になる場合があります。この場合、次の例に示すように、JobExecutionDecider を使用して決定を支援できます。
public class MyDecider implements JobExecutionDecider {
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
String status;
if (someCondition()) {
status = "FAILED";
}
else {
status = "COMPLETED";
}
return new FlowExecutionStatus(status);
}
} 次のサンプルジョブ構成では、decision は、使用する決定者とすべての遷移を指定します。
<job id="job">
<step id="step1" parent="s1" next="decision" />
<decision id="decision" decider="decider">
<next on="FAILED" to="step2" />
<next on="COMPLETED" to="step3" />
</decision>
<step id="step2" parent="s2" next="step3"/>
<step id="step3" parent="s3" />
</job>
<beans:bean id="decider" class="com.MyDecider"/> 次の例では、Java 構成を使用する場合、JobExecutionDecider を実装する Bean が next 呼び出しに直接渡されます。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.next(decider()).on("FAILED").to(step2())
.from(decider()).on("COMPLETED").to(step3())
.end()
.build();
}フローの分割
これまでに説明したすべてのシナリオには、Job が関与しており、その手順は一度に 1 つずつ線形に実行されます。この典型的なスタイルに加えて、Spring Batch では、並列フローでジョブを構成することもできます。
XML 名前空間を使用すると、'split' 要素を使用できます。次の例に示すように、'split' 要素には 1 つ以上の「フロー」要素が含まれており、個別のフロー全体を定義できます。'split' 要素には、'next' 属性または 'next'、'end'、または 'fail' 要素など、前述の遷移要素のいずれかを含めることもできます。
<split id="split1" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>Java ベースの構成では、提供された Builder を使用して分割を構成できます。次の例に示すように、'split' 要素には 1 つ以上の「フロー」要素が含まれており、個別のフロー全体を定義できます。'split' 要素には、'next' 属性または 'next'、'end'、または 'fail' 要素など、前述の遷移要素のいずれかを含めることもできます。
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
}
@Bean
public Job job(Flow flow1, Flow flow2) {
return this.jobBuilderFactory.get("job")
.start(flow1)
.split(new SimpleAsyncTaskExecutor())
.add(flow2)
.next(step4())
.end()
.build();
}フロー定義とジョブ間の依存関係の外部化
ジョブのフローの一部は、個別の Bean 定義として外部化してから、再利用できます。これを行うには 2 つの方法があります。1 つ目は、他の場所で定義されているフローへの参照としてフローを宣言することです。
次の例は、XML の他の場所で定義されたフローへの参照としてフローを宣言する方法を示しています。
<job id="job">
<flow id="job1.flow1" parent="flow1" next="step3"/>
<step id="step3" parent="s3"/>
</job>
<flow id="flow1">
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>次の例は、Java の他の場所で定義されたフローへの参照としてフローを宣言する方法を示しています。
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(flow1())
.next(step3())
.end()
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}前の例に示したように外部フローを定義することの効果は、外部フローからのステップを、インラインで宣言されているかのようにジョブに挿入することです。このようにして、多くのジョブが同じテンプレートフローを参照し、そのようなテンプレートを異なる論理フローに構成できます。これは、個々のフローの統合テストを分離する良い方法でもあります。
外部化されたフローの他の形式は、JobStep を使用することです。JobStep は FlowStep に似ていますが、実際には、指定されたフロー内のステップに対して個別のジョブ実行を作成して起動します。
次の例では、XML での JobStep の例を示しています。
<job id="jobStepJob" restartable="true">
<step id="jobStepJob.step1">
<job ref="job" job-launcher="jobLauncher"
job-parameters-extractor="jobParametersExtractor"/>
</step>
</job>
<job id="job" restartable="true">...</job>
<bean id="jobParametersExtractor" class="org.spr...DefaultJobParametersExtractor">
<property name="keys" value="input.file"/>
</bean> 次の例は、Java での JobStep の例を示しています。
@Bean
public Job jobStepJob() {
return this.jobBuilderFactory.get("jobStepJob")
.start(jobStepJobStep1(null))
.build();
}
@Bean
public Step jobStepJobStep1(JobLauncher jobLauncher) {
return this.stepBuilderFactory.get("jobStepJobStep1")
.job(job())
.launcher(jobLauncher)
.parametersExtractor(jobParametersExtractor())
.build();
}
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.build();
}
@Bean
public DefaultJobParametersExtractor jobParametersExtractor() {
DefaultJobParametersExtractor extractor = new DefaultJobParametersExtractor();
extractor.setKeys(new String[]{"input.file"});
return extractor;
} ジョブパラメーター抽出プログラムは、Step の ExecutionContext を、実行される Job の JobParameters に変換する方法を決定する戦略です。JobStep は、ジョブとステップの監視とレポートのためのより詳細なオプションが必要な場合に便利です。JobStep を使用することも、「ジョブ間の依存関係をどのように作成すればよいですか?」という質問に対する良い答えです。大きなシステムを小さなモジュールに分割し、ジョブのフローを制御するのに適した方法です。
Job および Step 属性の遅延バインディング
前に示した XML とフラットファイルの例はどちらも、Spring Resource 抽象化を使用してファイルを取得します。これは、Resource に java.io.File を返す getFile メソッドがあるために機能します。XML リソースとフラットファイルリソースはどちらも、標準の Spring 構造を使用して構成できます。
次の例は、XML での遅延バインディングを示しています。
<bean id="flatFileItemReader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource"
value="file://outputs/file.txt" />
</bean>次の例は、Java での遅延バインディングを示しています。
@Bean
public FlatFileItemReader flatFileItemReader() {
FlatFileItemReader<Foo> reader = new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource("file://outputs/file.txt"))
...
} 上記の Resource は、指定されたファイルシステムの場所からファイルをロードします。絶対位置は二重スラッシュ(//)で始まる必要があることに注意してください。ほとんどの Spring アプリケーションでは、これらのリソースの名前はコンパイル時にわかっているため、このソリューションで十分です。ただし、バッチシナリオでは、ファイル名をジョブのパラメーターとして実行時に決定する必要がある場合があります。これは、"-D" パラメーターを使用してシステムプロパティを読み取ることで解決できます。
次の例は、XML のプロパティからファイル名を読み取る方法を示しています。
<bean id="flatFileItemReader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="${input.file.name}" />
</bean>以下に、Java のプロパティからファイル名を読み取る方法を示します。
@Bean
public FlatFileItemReader flatFileItemReader(@Value("${input.file.name}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
} このソリューションが機能するために必要なのは、システム引数(-Dinput.file.name="file://outputs/file.txt" など)だけです。
ここでは PropertyPlaceholderConfigurer を使用できますが、Spring の ResourceEditor はすでにシステムプロパティのフィルター処理とプレースホルダー置換を行うため、システムプロパティが常に設定されている場合は必要ありません。 |
多くの場合、バッチ設定では、システムプロパティを使用するのではなく、ジョブの JobParameters でファイル名をパラメーター化し、その方法でアクセスすることをお勧めします。これを実現するために、Spring Batch では、さまざまな Job および Step 属性の遅延バインディングが可能です。
次の例は、XML でファイル名をパラメーター化する方法を示しています。
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters['input.file.name']}" />
</bean>次の例は、Java でファイル名をパラメーター化する方法を示しています。
@StepScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters['input.file.name']}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}JobExecution レベルと StepExecution レベルの ExecutionContext はどちらも同じ方法でアクセスできます。
次の例は、XML で ExecutionContext にアクセスする方法を示しています。
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobExecutionContext['input.file.name']}" />
</bean><bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{stepExecutionContext['input.file.name']}" />
</bean> 次の例は、Java で ExecutionContext にアクセスする方法を示しています。
@StepScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobExecutionContext['input.file.name']}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}@StepScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{stepExecutionContext['input.file.name']}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
} 遅延バインディングを使用する Bean は、scope="step" で宣言する必要があります。詳細については、ステップスコープを参照してください。 |
Spring 3.0(またはそれ以上)を使用している場合、ステップスコープの Bean の式は、多くの興味深い機能を備えた強力な汎用言語である Spring 式言語になっています。下位互換性を提供するために、Spring Batch が古いバージョンの Spring の存在を検出した場合、それほど強力ではなく、解析ルールがわずかに異なるネイティブ式言語を使用します。主な違いは、上記の例のマップキーを Spring 2.5 で引用する必要がないことですが、Spring 3.0 では引用符は必須です。 |
ステップスコープ
前に示した遅延バインディングの例はすべて、Bean 定義で宣言された「ステップ」のスコープを持っています。
次の例は、XML でステップスコープにバインドする例を示しています。
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters[input.file.name]}" />
</bean>次の例は、Java のステップスコープへのバインドの例を示しています。
@StepScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters[input.file.name]}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
} 遅延バインディングを使用するには、Step のスコープを使用する必要があります。これは、Step が開始されるまで Bean を実際にインスタンス化して、属性を検出できないためです。デフォルトでは Spring コンテナーの一部ではないため、batch ネームスペースを使用するか、StepScope に明示的に Bean 定義を含めるか、@EnableBatchProcessing アノテーションを使用して、スコープを明示的に追加する必要があります。これらの方法の 1 つのみを使用してください。次の例では、batch 名前空間を使用しています。
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
<batch:job .../>
...
</beans>次の例には、Bean 定義が明示的に含まれています。
<bean class="org.springframework.batch.core.scope.StepScope" />業務範囲
Spring Batch 3.0 で導入された Job スコープは、構成において Step スコープに似ていますが、Job コンテキストのスコープであるため、実行中のジョブごとにそのような Bean のインスタンスは 1 つだけです。さらに、#{..} プレースホルダーを使用して JobContext からアクセス可能な参照の遅延バインディングのサポートが提供されます。この機能を使用すると、Bean プロパティを、ジョブまたはジョブ実行コンテキストおよびジョブパラメーターから取得できます。
次の例は、XML でジョブスコープにバインドする例を示しています。
<bean id="..." class="..." scope="job">
<property name="name" value="#{jobParameters[input]}" />
</bean><bean id="..." class="..." scope="job">
<property name="name" value="#{jobExecutionContext['input.name']}.txt" />
</bean>次の例は、Java でのジョブスコープへのバインドの例を示しています。
@JobScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters[input]}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}@JobScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobExecutionContext['input.name']}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
} デフォルトでは Spring コンテナーの一部ではないため、batch 名前空間を使用して、Bean 定義を明示的に JobScope に含めるか、@EnableBatchProcessing アノテーションを使用して(ただし、すべてではない)、スコープを明示的に追加する必要があります。次の例では、batch 名前空間を使用しています。
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
<batch:job .../>
...
</beans> 次の例には、JobScope を明示的に定義する Bean が含まれています。
<bean class="org.springframework.batch.core.scope.JobScope" />マルチスレッドまたはパーティション化されたステップでジョブスコープの Bean を使用することには、いくつかの実際的な制限があります。Spring Batch は、これらのユースケースで生成されたスレッドを制御しないため、このような Bean を使用するようにスレッドを正しく設定することはできません。マルチスレッドまたはパーティション化されたステップでジョブスコープの Bean を使用することはお勧めしません。 |