ジョブの構成と実行
ドメインセクションでは、次の図をガイドとして使用して、全体的なアーキテクチャ設計について説明しました。

Job オブジェクトはステップの単純なコンテナーのように見えるかもしれませんが、開発者が認識しなければならない多くの構成オプションがあります。さらに、Job の実行方法と、その実行中のメタデータの保存方法については、多くの考慮事項があります。この章では、Job のさまざまな構成オプションと実行時の問題について説明します。
ジョブの構成
Job インターフェースには複数の実装があります。ただし、ビルダーは構成の違いを抽象化します。
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}Job (および通常はその中の Step)には JobRepository が必要です。JobRepository の構成は、BatchConfigurer を介して処理されます。
上記の例は、3 つの Step インスタンスで構成される Job を示しています。ジョブ関連のビルダーには、並列化(Split)、宣言型フロー制御(Decision)、フロー定義の外部化(Flow)に役立つ他の要素を含めることもできます。
Java を使用しても XML を使用しても、Job インターフェースの実装は複数あります。ただし、名前空間は構成の違いを抽象化します。名前、JobRepository、Step インスタンスのリストの 3 つの必須の依存関係のみがあります。
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>ここでの例では、親 Bean 定義を使用してステップを作成します。特定のステップの詳細をインラインで宣言するその他のオプションについては、ステップ構成のセクションを参照してください。XML 名前空間は、デフォルトで 'jobRepository' という ID を持つリポジトリを参照します。これは適切なデフォルトです。ただし、これを明示的にオーバーライドできます。
<job id="footballJob" job-repository="specialRepository">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s3" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job> ステップに加えて、ジョブ構成には、並列化(<split>)、宣言型フロー制御(<decision>)、フロー定義の外部化(<flow/>)に役立つ他の要素を含めることができます。
再起動性
バッチジョブを実行する際の 1 つの重要な課題は、Job を再起動したときの動作に関係します。特定の JobInstance に JobExecution がすでに存在する場合、Job の起動は「再起動」と見なされます。理想的には、すべてのジョブが中断したところから開始できるはずですが、これが不可能なシナリオもあります。このシナリオで新しい JobInstance が作成されるようにするのは、開発者の責任です。ただし、Spring Batch はいくつかのヘルプを提供します。Job を決して再起動しないで、常に新しい JobInstance の一部として実行する必要がある場合、restartable プロパティを 'false' に設定できます。
次の例は、XML で restartable フィールドを false に設定する方法を示しています。
<job id="footballJob" restartable="false">
...
</job> 次の例は、Java で restartable フィールドを false に設定する方法を示しています。
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.preventRestart()
...
.build();
} 別の言い方をすれば、restartable を false に設定すると、「この Job は再起動をサポートしません」という意味になります。再起動できない Job を再起動すると、JobRestartException がスローされます。
Job job = new SimpleJob();
job.setRestartable(false);
JobParameters jobParameters = new JobParameters();
JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters);
jobRepository.saveOrUpdate(firstExecution);
try {
jobRepository.createJobExecution(job, jobParameters);
fail();
}
catch (JobRestartException e) {
// expected
} この JUnit コードのスニペットは、再起動不可能なジョブに対して初めて JobExecution を作成しようとしても問題が発生しないことを示しています。ただし、2 回目の試行では JobRestartException がスローされます。
ジョブ実行のインターセプト
ジョブの実行中に、カスタムコードが実行されるように、ライフサイクルのさまざまなイベントを通知することが役立つ場合があります。SimpleJob は、適切なタイミングで JobListener を呼び出すことでこれを可能にします。
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}JobListeners を SimpleJob に追加するには、ジョブにリスナーを設定します。
次の例は、リスナー要素を XML ジョブ定義に追加する方法を示しています。
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
<listeners>
<listener ref="sampleListener"/>
</listeners>
</job>次の例は、Java ジョブ定義にリスナーメソッドを追加する方法を示しています。
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.listener(sampleListener())
...
.build();
}Job の成功または失敗に関係なく、afterJob メソッドが呼び出されることに注意してください。成功または失敗を判断する必要がある場合は、次のように JobExecution から取得できます。
public void afterJob(JobExecution jobExecution){
if (jobExecution.getStatus() == BatchStatus.COMPLETED ) {
//job success
}
else if (jobExecution.getStatus() == BatchStatus.FAILED) {
//job failure
}
}このインターフェースに対応するアノテーションは次のとおりです。
@BeforeJob@AfterJob
親ジョブからの継承
ジョブのグループが類似しているが同一ではない構成を共有している場合、具体的なジョブがプロパティを継承できる「親」 Job を定義すると役立つ場合があります。Java のクラス継承と同様に、「子」 Job はその要素と属性を親のものと組み合わせます。
次の例では、"baseJob" はリスナーのリストのみを定義する抽象的な Job 定義です。Job "job1" は、"baseJob" からリスナーのリストを継承し、それを独自のリスナーのリストとマージして、2 つのリスナーと 1 つの Step"step1" を持つ Job を生成する具体的な定義です。
<job id="baseJob" abstract="true">
<listeners>
<listener ref="listenerOne"/>
<listeners>
</job>
<job id="job1" parent="baseJob">
<step id="step1" parent="standaloneStep"/>
<listeners merge="true">
<listener ref="listenerTwo"/>
<listeners>
</job>詳細については、親ステップからの継承のセクションを参照してください。
JobParametersValidator
XML 名前空間で宣言されたジョブまたは AbstractJob のサブクラスを使用するジョブは、オプションで、実行時にジョブパラメーターのバリデーターを宣言できます。これは、たとえば、すべての必須パラメーターでジョブが開始されることをアサートする必要がある場合に役立ちます。DefaultJobParametersValidator を使用して、単純な必須パラメーターとオプションパラメーターの組み合わせを制約することができます。より複雑な制約については、インターフェースを自分で実装できます。
次の例に示すように、バリデーターの構成は、ジョブの子要素を介して XML 名前空間を介してサポートされます。
<job id="job1" parent="baseJob3">
<step id="step1" parent="standaloneStep"/>
<validator ref="parametersValidator"/>
</job>バリデーターは、参照として(前に示したように)、または Bean 名前空間のネストされた Bean 定義として指定できます。
バリデーターの構成は、次の例に示すように、java ビルダーを介してサポートされます。
@Bean
public Job job1() {
return this.jobBuilderFactory.get("job1")
.validator(parametersValidator())
...
.build();
}Java 構成
Spring 3 は、XML ではなく java を介してアプリケーションを構成する機能をもたらしました。Spring Batch 2.2.0 以降、バッチジョブは同じ java 構成を使用して構成できます。java ベースの構成には、@EnableBatchProcessing アノテーションと 2 つのビルダーの 2 つのコンポーネントがあります。
@EnableBatchProcessing は、Spring ファミリーの他の @Enable * アノテーションと同様に機能します。この場合、@EnableBatchProcessing はバッチジョブを構築するための基本構成を提供します。この基本構成内で、StepScope のインスタンスが、オートワイヤーに使用できるようになったいくつかの Bean に加えて作成されます。
JobRepository: Bean の名前 "jobRepository"JobLauncher: Bean の名前 "jobLauncher"JobRegistry: Bean の名前 "jobRegistry"PlatformTransactionManager: Bean の名前 "transactionManager"JobBuilderFactory: Bean の名前 "jobBuilders"StepBuilderFactory: Bean の名前 "stepBuilders"
この構成のコアインターフェースは BatchConfigurer です。デフォルトの実装では、上記の Bean が提供され、提供されるコンテキスト内で Bean として DataSource が必要です。このデータソースは JobRepository によって使用されます。BatchConfigurer インターフェースのカスタム実装を作成することにより、これらの Bean のいずれかをカスタマイズできます。通常、DefaultBatchConfigurer (BatchConfigurer が見つからない場合に提供されます)を継承し、必要な getter をオーバーライドするだけで十分です。ただし、独自の実装が必要になる場合があります。次の例は、カスタムトランザクションマネージャーを提供する方法を示しています。
@Bean
public BatchConfigurer batchConfigurer(DataSource dataSource) {
return new DefaultBatchConfigurer(dataSource) {
@Override
public PlatformTransactionManager getTransactionManager() {
return new MyTransactionManager();
}
};
}
|
基本構成が整ったら、ユーザーは提供されたビルダーファクトリを使用してジョブを構成できます。次の例は、JobBuilderFactory および StepBuilderFactory で構成された 2 ステップのジョブを示しています。
@Configuration
@EnableBatchProcessing
@Import(DataSourceConfiguration.class)
public class AppConfig {
@Autowired
private JobBuilderFactory jobs;
@Autowired
private StepBuilderFactory steps;
@Bean
public Job job(@Qualifier("step1") Step step1, @Qualifier("step2") Step step2) {
return jobs.get("myJob").start(step1).next(step2).build();
}
@Bean
protected Step step1(ItemReader<Person> reader,
ItemProcessor<Person, Person> processor,
ItemWriter<Person> writer) {
return steps.get("step1")
.<Person, Person> chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
protected Step step2(Tasklet tasklet) {
return steps.get("step2")
.tasklet(tasklet)
.build();
}
}JobRepository の構成
@EnableBatchProcessing を使用する場合、JobRepository はすぐに使用できます。このセクションでは、独自の構成について説明します。
前に説明したように、JobRepository は、JobExecution や StepExecution などの Spring Batch 内のさまざまな永続ドメインオブジェクトの基本的な CRUD 操作に使用されます。これは、JobLauncher、Job、Step などの多くの主要なフレームワーク機能に必要です。
バッチ名前空間は、JobRepository 実装とそのコラボレーターの実装の詳細の多くを抽象化します。ただし、次の例に示すように、まだいくつかの構成オプションを使用できます。
<job-repository id="jobRepository"
data-source="dataSource"
transaction-manager="transactionManager"
isolation-level-for-create="SERIALIZABLE"
table-prefix="BATCH_"
max-varchar-length="1000"/>id を除いて、上記の構成オプションは必要ありません。設定されていない場合は、上記のデフォルトが使用されます。これらは認識のために上に表示されています。max-varchar-length のデフォルトは 2500 です。これは、サンプルスキーマスクリプトの長い VARCHAR 列の長さです。
java 構成を使用する場合、JobRepository が提供されます。DataSource が提供されている場合は JDBC ベースのものが提供され、提供されていない場合は Map ベースのものが提供されます。ただし、BatchConfigurer インターフェースの実装を通じて JobRepository の構成をカスタマイズできます。
...
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setIsolationLevelForCreate("ISOLATION_SERIALIZABLE");
factory.setTablePrefix("BATCH_");
factory.setMaxVarCharLength(1000);
return factory.getObject();
}
...dataSource と transactionManager を除き、上記の構成オプションはどれも必須ではありません。設定されていない場合は、上記のデフォルトが使用されます。これらは、認識のために上記に示されています。最大 varchar 長はデフォルトで 2500 に設定されており、これはサンプルスキーマスクリプトの長い VARCHAR 列の長さです。
JobRepository のトランザクション構成
名前空間または提供された FactoryBean が使用されている場合、トランザクションに関するアドバイスがリポジトリの周囲に自動的に作成されます。これは、障害後の再起動に必要な状態を含むバッチメタデータが正しく保持されるようにするためです。リポジトリメソッドがトランザクションでない場合、フレームワークの動作は適切に定義されません。create* メソッド属性の分離レベルは、ジョブが起動されたときに、2 つのプロセスが同じジョブを同時に起動しようとした場合、1 つだけが成功するように個別に指定されます。このメソッドのデフォルトの分離レベルは SERIALIZABLE で、非常に積極的です。READ_COMMITTED も同様に機能します。2 つのプロセスがこのように衝突する可能性が低い場合、READ_UNCOMMITTED は問題ありません。ただし、create* メソッドの呼び出しは非常に短いため、データベースプラットフォームがサポートしている限り、SERIALIZED が問題を引き起こす可能性は低いです。ただし、これは上書きできます。
次の例は、XML の分離レベルをオーバーライドする方法を示しています。
<job-repository id="jobRepository"
isolation-level-for-create="REPEATABLE_READ" />次の例は、Java で分離レベルをオーバーライドする方法を示しています。
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ");
return factory.getObject();
}名前空間またはファクトリ Bean を使用しない場合は、AOP を使用してリポジトリのトランザクション動作を構成することも不可欠です。
次の例は、XML でリポジトリのトランザクション動作を構成する方法を示しています。
<aop:config>
<aop:advisor
pointcut="execution(* org.springframework.batch.core..*Repository+.*(..))"/>
<advice-ref="txAdvice" />
</aop:config>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" />
</tx:attributes>
</tx:advice>上記のフラグメントは、ほとんど変更を加えることなく、ほぼそのまま使用できます。また、適切な名前空間宣言を含め、spring-tx と spring-aop(または Spring 全体)がクラスパス上にあることを確認することも忘れないでください。
次の例は、Java でリポジトリのトランザクション動作を構成する方法を示しています。
@Bean
public TransactionProxyFactoryBean baseProxy() {
TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean();
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED");
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
transactionProxyFactoryBean.setTarget(jobRepository());
transactionProxyFactoryBean.setTransactionManager(transactionManager());
return transactionProxyFactoryBean;
}テーブルプレフィックスの変更
JobRepository の別の変更可能なプロパティは、メタデータテーブルのテーブルプレフィックスです。デフォルトでは、すべて BATCH_ で始まります。BATCH_JOB_EXECUTION と BATCH_STEP_EXECUTION は 2 つの例です。ただし、このプレフィックスを変更する潜在的な理由があります。スキーマ名をテーブル名の前に付加する必要がある場合、または同じスキーマ内で複数のメタデータテーブルセットが必要な場合は、テーブルプレフィックスを変更する必要があります。
次の例は、XML でテーブルプレフィックスを変更する方法を示しています。
<job-repository id="jobRepository"
table-prefix="SYSTEM.TEST_" />次の例は、Java でテーブルプレフィックスを変更する方法を示しています。
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setTablePrefix("SYSTEM.TEST_");
return factory.getObject();
} 前述の変更を前提として、メタデータテーブルへのすべてのクエリには SYSTEM.TEST_ のプレフィックスが付きます。BATCH_JOB_EXECUTION は SYSTEM と呼ばれます。TEST_JOB_EXECUTION。
テーブルプレフィックスのみが設定可能です。テーブル名と列名は違います。 |
インメモリリポジトリ
ドメインオブジェクトをデータベースに永続化したくないシナリオがあります。1 つの理由は速度かもしれません。各コミットポイントでドメインオブジェクトを保存するには、余分な時間がかかります。もう 1 つの理由は、特定のジョブのステータスを保持する必要がないことです。このため、Spring バッチは、ジョブリポジトリのメモリ内 Map バージョンを提供します。
次の例は、XML に MapJobRepositoryFactoryBean が含まれていることを示しています。
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager"/>
</bean> 次の例は、Java に MapJobRepositoryFactoryBean が含まれていることを示しています。
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
MapJobRepositoryFactoryBean factory = new MapJobRepositoryFactoryBean();
factory.setTransactionManager(transactionManager);
return factory.getObject();
} インメモリリポジトリは揮発性であるため、JVM インスタンス間で再起動できないことに注意してください。また、同じパラメーターを持つ 2 つのジョブインスタンスが同時に起動されることを保証することはできません。また、マルチスレッドジョブ、ローカルにパーティション分割された Step での使用には適していません。これらの機能が必要な場合は、データベースバージョンのリポジトリを使用してください。
ただし、リポジトリ内にロールバックセマンティクスがあり、ビジネスロジックがまだトランザクションである可能性があるため(RDBMS アクセスなど)、トランザクションマネージャーを定義する必要があります。テストの目的で、多くの人が ResourcelessTransactionManager が役立つと感じています。
リポジトリ内の非標準データベース型
サポートされているプラットフォームのリストにないデータベースプラットフォームを使用している場合、SQL バリアントが十分に近い場合は、サポートされている型の 1 つを使用できる可能性があります。これを行うには、名前空間ショートカットの代わりに生の JobRepositoryFactoryBean を使用し、それを使用してデータベース型を最も近いものに設定します。
次の例は、JobRepositoryFactoryBean を使用してデータベース型を XML で最も一致するものに設定する方法を示しています。
<bean id="jobRepository" class="org...JobRepositoryFactoryBean">
<property name="databaseType" value="db2"/>
<property name="dataSource" ref="dataSource"/>
</bean> 次の例は、JobRepositoryFactoryBean を使用してデータベース型を Java で最も近いものに設定する方法を示しています。
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setDatabaseType("db2");
factory.setTransactionManager(transactionManager);
return factory.getObject();
}(指定されていない場合、JobRepositoryFactoryBean は DataSource からデータベース型を自動検出しようとします)プラットフォーム間の主な違いは主に主キーをインクリメントする戦略によって説明されるため、incrementerFactory もオーバーライドする必要があります。(Spring Framework の標準実装の 1 つを使用)。
それでも機能しない場合、または RDBMS を使用していない場合、唯一のオプションは、SimpleJobRepository が依存するさまざまな Dao インターフェースを実装し、通常の Spring の方法で手動で接続することです。
JobLauncher の構成
@EnableBatchProcessing を使用する場合、JobRegistry はすぐに使用できます。このセクションでは、独自の構成について説明します。
JobLauncher インターフェースの最も基本的な実装は SimpleJobLauncher です。実行を取得するために必要な唯一の依存関係は JobRepository です。
次の例は、XML の SimpleJobLauncher を示しています。
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean> 次の例は、Java での SimpleJobLauncher を示しています。
...
// This would reside in your BatchConfigurer implementation
@Override
protected JobLauncher createJobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
...JobExecution が取得されると、次の図に示すように、Job の execute メソッドに渡され、最終的に JobExecution が呼び出し元に返されます。

シーケンスは単純で、スケジューラーから起動するとうまく機能します。ただし、HTTP リクエストから起動しようとすると問題が発生します。このシナリオでは、SimpleJobLauncher がすぐに呼び出し元に戻るように、起動を非同期で実行する必要があります。これは、バッチなどの長時間実行されるプロセスに必要な時間、HTTP リクエストを開いたままにしておくことは適切ではないためです。次のイメージは、シーケンスの例を示しています。

TaskExecutor を構成することにより、このシナリオを可能にするように SimpleJobLauncher を構成できます。
次の XML の例は、すぐに戻るように構成された SimpleJobLauncher を示しています。
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
</property>
</bean> 次の Java の例は、すぐに戻るように構成された SimpleJobLauncher を示しています。
@Bean
public JobLauncher jobLauncher() {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository());
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}spring TaskExecutor インターフェースの任意の実装を使用して、ジョブの非同期実行方法を制御できます。
ジョブを実行する
少なくとも、バッチジョブの起動には、起動する Job と JobLauncher の 2 つのことが必要です。両方を同じコンテキストまたは異なるコンテキストに含めることができます。例: コマンドラインからジョブを起動する場合、新しい JVM は各ジョブに対してインスタンス化されるため、すべてのジョブには独自の JobLauncher があります。ただし、HttpRequest のスコープ内の Web コンテナー内から実行する場合、通常、非同期ジョブ起動用に構成された JobLauncher が 1 つあり、複数のリクエストが起動してジョブを起動します。
コマンドラインからジョブを実行する
エンタープライズスケジューラからジョブを実行するユーザーの場合、コマンドラインがプライマリインターフェースです。これは、ほとんどのスケジューラー(NativeJob を使用する場合を除き、Quartz を除く)は、主にシェルスクリプトで開始されるオペレーティングシステムプロセスで直接動作するためです。Perl、Ruby などのシェルスクリプト、あるいは ant や maven などの「ビルドツール」など、Java プロセスを起動する方法は多数あります。ただし、ほとんどの人はシェルスクリプトに精通しているため、この例ではシェルスクリプトに焦点を当てます。
CommandLineJobRunner
ジョブを起動するスクリプトは Java 仮想マシンを開始する必要があるため、プライマリエントリポイントとして機能するメインメソッドを持つクラスが必要です。Spring Batch は、まさにこの目的に役立つ実装を提供します: CommandLineJobRunner。これはアプリケーションをブートストラップする 1 つのメソッドにすぎないことに注意することが重要です。ただし、Java プロセスを起動する方法は数多くあり、このクラスを決定的なものと見なすべきではありません。CommandLineJobRunner は 4 つのタスクを実行します。
適切な
ApplicationContextをロードしますコマンドライン引数を
JobParametersに解析します引数に基づいて適切なジョブを見つける
アプリケーションコンテキストで提供される
JobLauncherを使用して、ジョブを起動します。
これらのタスクはすべて、渡された引数のみを使用して実行されます。以下は必須の引数です。
jobPath |
|
jobName | 実行するジョブの名前。 |
これらの引数は、最初にパス、次に名前を指定して渡す必要があります。これらの後のすべての引数はジョブパラメーターと見なされ、JobParameters オブジェクトに変換され、"name = value" の形式である必要があります。
次の例は、XML で定義されたジョブにジョブパラメーターとして渡された日付を示しています。
<bash$ java CommandLineJobRunner endOfDayJob.xml endOfDay schedule.date(date)=2007/05/05次の例は、Java で定義されたジョブにジョブパラメーターとして渡された日付を示しています。
<bash$ java CommandLineJobRunner io.spring.EndOfDayJobConfiguration endOfDay schedule.date(date)=2007/05/05 デフォルトでは、 次の例では、 この動作は、カスタム |
ほとんどの場合、マニフェストを使用して jar でメインクラスを宣言する必要がありますが、簡単にするために、クラスは直接使用されました。この例では、domainLanguageOfBatch の同じ "EndOfDay" の例を使用しています。最初の引数は "endOfDayJob.xml" です。これは、Job を含む Spring ApplicationContext です。2 番目の引数 'endOfDay' は、ジョブ名を表します。最後の引数 'schedule.date(date)= 2007/05/05' は、JobParameters オブジェクトに変換されます。
次の例は、XML での endOfDay の構成例を示しています。
<job id="endOfDay">
<step id="step1" parent="simpleStep" />
</job>
<!-- Launcher details removed for clarity -->
<beans:bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher" /> ほとんどの場合、マニフェストを使用して jar でメインクラスを宣言する必要がありますが、簡単にするために、クラスは直接使用されました。この例では、domainLanguageOfBatch の同じ "EndOfDay" の例を使用しています。最初の引数は "io.spring.EndOfDayJobConfiguration" です。これは、ジョブを含む構成クラスの完全修飾クラス名です。2 番目の引数 'endOfDay' は、ジョブ名を表します。最後の引数 'schedule.date(date)= 2007/05/05' は JobParameters オブジェクトに変換されます。java 構成の例は次のとおりです。
次の例は、Java での endOfDay の構成例を示しています。
@Configuration
@EnableBatchProcessing
public class EndOfDayJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job endOfDay() {
return this.jobBuilderFactory.get("endOfDay")
.start(step1())
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.tasklet((contribution, chunkContext) -> null)
.build();
}
} 上記の例は、一般に Spring Batch でバッチジョブを実行するための要件が他にもたくさんあるため、非常に単純化されていますが、CommandLineJobRunner の 2 つの主要な要件である Job と JobLauncher を示すのに役立ちます。
ExitCodes
コマンドラインからバッチジョブを起動する場合、エンタープライズスケジューラがよく使用されます。ほとんどのスケジューラはかなり馬鹿げており、プロセスレベルでのみ動作します。これは、呼び出しているシェルスクリプトなどのオペレーティングシステムプロセスについてのみ知っていることを意味します。このシナリオでは、ジョブの成功または失敗についてスケジューラに通信する唯一の方法は、リターンコードを使用することです。リターンコードは、実行の結果を示すプロセスによってスケジューラに返される番号です。最も単純な場合: 0 は成功、1 は失敗です。ただし、より複雑なシナリオが存在する可能性があります。ジョブ A がジョブ B を 4 キックオフで返し、ジョブ C が 5 キックを返す場合、この型の動作はスケジューラレベルで設定されますが、Spring Batch は、特定のバッチジョブの「終了コード」の数値表現を返す方法を提供します。Spring Batch では、これは ExitStatus 内にカプセル化されます。これについては、第 5 章で詳しく説明します。終了コードについて説明するために、知っておくべき唯一の重要なことは、ExitStatus にフレームワークによって設定される終了コードプロパティがあることです(または開発者)および JobLauncher から返される JobExecution の一部として返されます。CommandLineJobRunner は、ExitCodeMapper インターフェースを使用して、このストリング値を数値に変換します。
public interface ExitCodeMapper {
public int intValue(String exitCode);
}ExitCodeMapper の基本的な契約は、文字列の終了コードが与えられると、数値表現が返されるということです。ジョブランナーが使用するデフォルトの実装は、SimpleJvmExitCodeMapper であり、完了時に 0、汎用エラーに 1、提供されたコンテキストで Job が見つからないなどのジョブランナーエラーに 2 を返します。上記の 3 つの値よりも複雑なものが必要な場合は、ExitCodeMapper インターフェースのカスタム実装を提供する必要があります。CommandLineJobRunner は ApplicationContext を作成するクラスであるため、「一緒に接続」することはできないため、上書きする必要がある値はすべてオートワイヤーする必要があります。これは、ExitCodeMapper の実装が BeanFactory 内で見つかった場合、コンテキストが作成された後にランナーに注入されることを意味します。独自の ExitCodeMapper を提供するために行う必要があるのは、実装をルートレベル Bean として宣言し、ランナーによってロードされる ApplicationContext の一部であることを確認することです。
Web コンテナー内からのジョブの実行
従来、バッチジョブなどのオフライン処理は、上記のようにコマンドラインから起動されていました。ただし、HttpRequest からの起動がより良いオプションである場合が多くあります。このような多くのユースケースには、レポート、アドホックジョブの実行、Web アプリケーションのサポートが含まれます。定義上、バッチジョブは長時間実行されるため、最も重要な問題は、ジョブを非同期で起動することです。
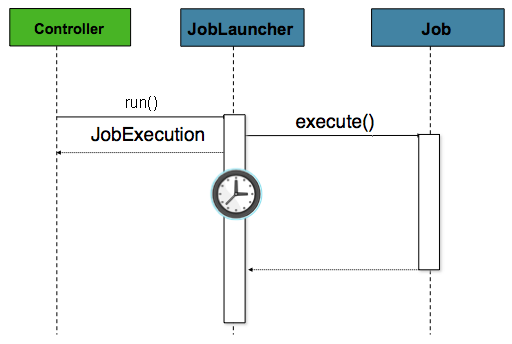
この場合のコントローラーは Spring MVC コントローラーです。Spring MVC の詳細については、https://docs.spring.io/spring/docs/current/spring-framework-reference/web.html#mvc を参照してください。コントローラーは、非同期で起動するように設定された JobLauncher を使用して Job を起動します。これは、すぐに JobExecution を返します。Job はまだ実行されている可能性がありますが、この非ブロック動作により、コントローラーはすぐに戻ることができます。これは、HttpRequest を処理するときに必要です。例を次に示します。
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}高度なメタデータの使用
これまで、JobLauncher と JobRepository の両方のインターフェースについて説明してきました。これらは一緒になって、ジョブの単純な起動と、バッチドメインオブジェクトの基本的な CRUD 操作を表します。

JobLauncher は JobRepository を使用して新しい JobExecution オブジェクトを作成し、実行します。Job と Step の実装は、後で、ジョブの実行中に同じ実行の基本的な更新に同じ JobRepository を使用します。単純なシナリオでは基本的な操作で十分ですが、数百のバッチジョブと複雑なスケジューリング要件がある大規模なバッチ環境では、メタデータへのより高度なアクセスが必要です。
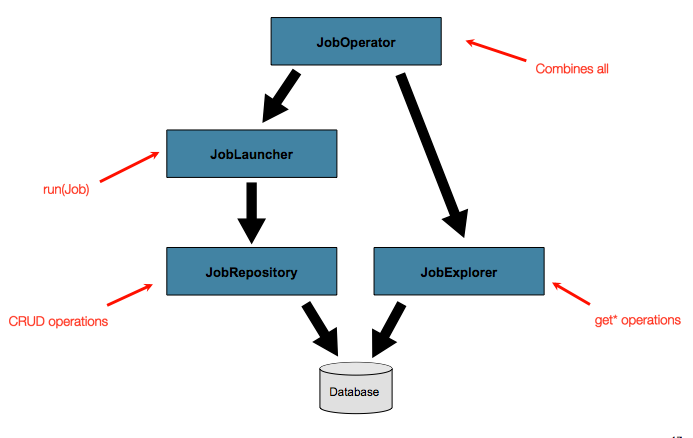
以下で説明する JobExplorer および JobOperator インターフェースは、メタデータを照会および制御するための追加機能を追加します。
リポジトリのクエリ
高度な機能を使用する前の最も基本的なニーズは、既存の実行についてリポジトリをクエリする機能です。この機能は、JobExplorer インターフェースによって提供されます。
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
} 上記のメソッドシグネチャーから明らかなように、JobExplorer は JobRepository の読み取り専用バージョンであり、JobRepository と同様に、ファクトリ Bean を使用して簡単に構成できます。
次の例は、XML で JobExplorer を構成する方法を示しています。
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" /> 次の例は、Java で JobExplorer を構成する方法を示しています。
...
// This would reside in your BatchConfigurer implementation
@Override
public JobExplorer getJobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
return factoryBean.getObject();
}
... この章の前半、JobRepository のテーブルプレフィックスは、さまざまなバージョンまたはスキーマを許可するように変更できることに注意しました。JobExplorer は同じテーブルで機能するため、プレフィックスを設定する機能も必要です。
次の例は、XML で JobExplorer のテーブルプレフィックスを設定する方法を示しています。
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:tablePrefix="SYSTEM."/> 次の例は、Java で JobExplorer のテーブルプレフィックスを設定する方法を示しています。
...
// This would reside in your BatchConfigurer implementation
@Override
public JobExplorer getJobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
factoryBean.setTablePrefix("SYSTEM.");
return factoryBean.getObject();
}
...JobRegistry
JobRegistry (およびその親インターフェース JobLocator)は必須ではありませんが、コンテキストで使用可能なジョブを追跡する場合に役立ちます。また、ジョブが他の場所(子コンテキストなど)で作成されている場合に、アプリケーションコンテキストで一元的にジョブを収集する場合にも役立ちます。カスタム JobRegistry 実装を使用して、登録されているジョブの名前やその他のプロパティを操作することもできます。フレームワークによって提供される実装は 1 つだけであり、これはジョブ名からジョブインスタンスへの単純なマップに基づいています。
次の例は、XML で定義されたジョブに JobRegistry を含める方法を示しています。
<bean id="jobRegistry" class="org.springframework.batch.core.configuration.support.MapJobRegistry" /> 次の例は、Java で定義されたジョブに JobRegistry を含める方法を示しています。
@EnableBatchProcessing を使用する場合、JobRegistry はすぐに使用できます。独自に設定する場合:
...
// This is already provided via the @EnableBatchProcessing but can be customized via
// overriding the getter in the SimpleBatchConfiguration
@Override
@Bean
public JobRegistry jobRegistry() throws Exception {
return new MapJobRegistry();
}
...JobRegistry を自動的に読み込むには、Bean ポストプロセッサーを使用する方法と、レジストラライフサイクルコンポーネントを使用する方法の 2 つがあります。これらの 2 つのメカニズムについては、次のセクションで説明します。
JobRegistryBeanPostProcessor
これは、作成時にすべてのジョブを登録できる Bean ポストプロセッサーです。
次の例は、XML で定義されたジョブに JobRegistryBeanPostProcessor を含める方法を示しています。
<bean id="jobRegistryBeanPostProcessor" class="org.spr...JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean> 次の例は、Java で定義されたジョブに JobRegistryBeanPostProcessor を含める方法を示しています。
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor() {
JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor();
postProcessor.setJobRegistry(jobRegistry());
return postProcessor;
}厳密には必要ではありませんが、この例のポストプロセッサーには id が与えられているため、子コンテキストに(たとえば、親 Bean 定義として)含めることができ、そこで作成されたすべてのジョブも自動的に登録されます。
AutomaticJobRegistrar
これは、子コンテキストを作成し、作成時にそれらのコンテキストからジョブを登録するライフサイクルコンポーネントです。これを行う利点の 1 つは、子コンテキストのジョブ名がレジストリ内でグローバルに一意である必要がある一方で、それらの依存関係に「自然な」名前を付けることができることです。たとえば、それぞれが 1 つのジョブのみを持ち、すべてが「リーダー」などの同じ Bean 名を持つ ItemReader の異なる定義を持つ XML 構成ファイルのセットを作成できます。これらすべてのファイルが同じコンテキストにインポートされた場合、リーダー定義は互いに衝突してオーバーライドしますが、自動レジストラを使用すると、これは回避されます。これにより、アプリケーションの個別のモジュールから提供されたジョブを簡単に統合できます。
次の例は、XML で定義されたジョブに AutomaticJobRegistrar を含める方法を示しています。
<bean class="org.spr...AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.spr...ClasspathXmlApplicationContextsFactoryBean">
<property name="resources" value="classpath*:/config/job*.xml" />
</bean>
</property>
<property name="jobLoader">
<bean class="org.spr...DefaultJobLoader">
<property name="jobRegistry" ref="jobRegistry" />
</bean>
</property>
</bean> 次の例は、Java で定義されたジョブに AutomaticJobRegistrar を含める方法を示しています。
@Bean
public AutomaticJobRegistrar registrar() {
AutomaticJobRegistrar registrar = new AutomaticJobRegistrar();
registrar.setJobLoader(jobLoader());
registrar.setApplicationContextFactories(applicationContextFactories());
registrar.afterPropertiesSet();
return registrar;
} レジストラには 2 つの必須プロパティがあります。1 つは ApplicationContextFactory の配列(ここでは便利なファクトリ Bean から作成されます)、もう 1 つは JobLoader です。JobLoader は、子コンテキストのライフサイクルを管理し、JobRegistry にジョブを登録します。
ApplicationContextFactory は、子コンテキストの作成を担当し、最も一般的な使用箇所は、上記のように ClassPathXmlApplicationContextFactory を使用することです。このファクトリの機能の 1 つは、デフォルトで設定の一部を親コンテキストから子にコピーすることです。たとえば、PropertyPlaceholderConfigurer または AOP の構成を親と同じにする必要がある場合、子で再定義する必要はありません。
AutomaticJobRegistrar は、必要に応じて JobRegistryBeanPostProcessor と組み合わせて使用できます(DefaultJobLoader も使用されている場合)。たとえば、メインの親コンテキストと子の場所にジョブが定義されている場合、これが望ましい場合があります。
JobOperator
前述のように、JobRepository はメタデータに対して CRUD 操作を提供し、JobExplorer はメタデータに対して読み取り専用操作を提供します。ただし、これらの操作は、バッチオペレータによって一般的に行われるように、ジョブの停止、再起動、集計などの一般的な監視タスクを実行するために一緒に使用すると最も役立ちます。Spring Batch は、JobOperator インターフェースを介して以下の型の操作を提供します。
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
} 上記の操作は、JobLauncher、JobRepository、JobExplorer、JobRegistry などのさまざまなインターフェースからのメソッドを表しています。このため、提供されている JobOperator の実装である SimpleJobOperator には、多くの依存関係があります。
次の例は、XML での SimpleJobOperator の一般的な Bean 定義を示しています。
<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean> 次の例は、Java での SimpleJobOperator の一般的な Bean 定義を示しています。
/**
* All injected dependencies for this bean are provided by the @EnableBatchProcessing
* infrastructure out of the box.
*/
@Bean
public SimpleJobOperator jobOperator(JobExplorer jobExplorer,
JobRepository jobRepository,
JobRegistry jobRegistry) {
SimpleJobOperator jobOperator = new SimpleJobOperator();
jobOperator.setJobExplorer(jobExplorer);
jobOperator.setJobRepository(jobRepository);
jobOperator.setJobRegistry(jobRegistry);
jobOperator.setJobLauncher(jobLauncher);
return jobOperator;
}ジョブリポジトリでテーブルプレフィックスを設定する場合は、Job Explorer でも忘れずに設定してください。 |
JobParametersIncrementer
JobOperator のメソッドのほとんどは自明であり、より詳細な説明はインターフェースの javadoc にあります。ただし、startNextInstance メソッドは注目に値します。このメソッドは、ジョブの新しいインスタンスを常に開始します。これは、JobExecution に重大な課題があり、ジョブを最初からやり直す必要がある場合に非常に役立ちます。ただし、パラメーターが以前のパラメーターセットと異なる場合に新しい JobInstance をトリガーする新しい JobParameters オブジェクトを必要とする JobLauncher とは異なり、startNextInstance メソッドは Job に結び付けられた JobParametersIncrementer を使用して Job を新しいインスタンスに強制します。
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}JobParametersIncrementer の規約では、JobParameters オブジェクトが与えられると、それに含まれる必要な値をインクリメントすることにより、「次の」JobParameters オブジェクトを返します。この戦略は、フレームワークが JobParameters のどの変更がそれを「次の」インスタンスにするのかを知る方法がないため便利です。例: JobParameters の唯一の値が日付であり、次のインスタンスを作成する必要がある場合、その値を 1 日増やす必要がありますか? または 1 週間(たとえば、ジョブが毎週の場合)? 以下に示すように、ジョブの識別に役立つ数値についても同じことが言えます。
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
} この例では、"run.id" というキーを持つ値を使用して、JobInstances を区別しています。渡された JobParameters が null の場合、Job は以前に実行されたことがないため、その初期状態を返すことができると想定できます。ただし、そうでない場合は、古い値が取得され、1 ずつ増分されて返されます。
XML で定義されたジョブの場合、次のように、増分子を名前空間の 'incrementer' 属性を介して Job に関連付けることができます。
<job id="footballJob" incrementer="sampleIncrementer">
...
</job>Java で定義されたジョブの場合、インクリメント機能は、次のように、ビルダーで提供される incrementer メソッドを介して「ジョブ」に関連付けることができます。
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.incrementer(sampleIncrementer())
...
.build();
}ジョブの停止
JobOperator の最も一般的な使用例の 1 つは、ジョブを正常に停止することです。
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next()); 特に即時実行を強制する方法がないため、特にビジネスサービスなど、フレームワークが制御できない開発者コードで実行されている場合は、シャットダウンは即時ではありません。ただし、制御がフレームワークに戻されるとすぐに、現在の StepExecution のステータスを BatchStatus.STOPPED に設定し、保存してから、終了する前に JobExecution に対して同じことを行います。
ジョブの中止
FAILED であるジョブの実行を再開できます(Job が再開可能な場合)。ステータスが ABANDONED のジョブ実行は、フレームワークによって再起動されません。ABANDONED ステータスは、ステップ実行でも使用され、再開されたジョブ実行でスキップ可能としてマークされます。ジョブが実行中で、前回の失敗したジョブ実行で ABANDONED とマークされたステップに遭遇すると、次のステップに進みます(ジョブフロー定義とステップ実行終了ステータスによって決定されます)。
プロセスが停止した場合("kill -9" またはサーバー障害)、ジョブはもちろん実行されていませんが、プロセスが停止する前にだれもそれを通知しなかったため、JobRepository は知る方法がありません。実行が失敗したか、中止されたと見なされるべきであることを知っていることを手動で伝える必要があります(ステータスを FAILED または ABANDONED に変更します)。これはビジネス上の決定であり、自動化する方法はありません。ステータスを FAILED に変更するのは、再起動できない場合、または再起動データが有効であることがわかっている場合のみです。Spring Batch Admin JobService には、ジョブの実行を中止するユーティリティがあります。