このセクションでは、Spring Cloud Sleuth の詳細について詳しく説明します。ここでは、使用およびカスタマイズする可能性のある主要な機能について学習できます。まだ読んでいない場合は、"getting-started.html" と "using.html" のセクションを読んで、基本をしっかりと理解することをお勧めします。
1. コンテキストの伝播
トレースは、ヘッダー伝播を使用してサービスからサービスに接続します。デフォルトの形式は B3 [GitHub] (英語) です。データ形式と同様に、トレース ID とスパン ID が B3 と互換性がある場合は、代替ヘッダー形式を構成することもできます。最も注目すべきは、これはトレース ID とスパン ID が UUID ではなく小文字の 16 進数であることを意味します。トレース識別子に加えて、他のプロパティ(バゲッジ)もリクエストと一緒に渡すことができます。リモートバゲッジは事前定義する必要がありますが、それ以外の場合は柔軟性があります。
提供されているデフォルトを使用するには、spring.sleuth.propagation.type プロパティを設定できます。値はリストにすることができます。その場合、より多くのトレースヘッダーを伝播します。
Brave の場合、AWS、B3、W3C 伝搬型をサポートします。
カスタムコンテキスト伝播を提供する方法の詳細については、この「セクションの作成方法」を参照してください。
2. サンプリング
Spring Cloud Sleuth は、サンプリングの決定をトレーサーの実装にプッシュします。ただし、実行時にサンプリングの決定を変更できる場合があります。
そのようなケースの 1 つは、特定のクライアントスパンのレポートをスキップすることです。これを実現するために、スキップするパスパターンを使用して spring.sleuth.web.client.skip-pattern を設定できます。もう 1 つのオプションは、独自のカスタム org.springframework.cloud.sleuth.SamplerFunction<`org.springframework.cloud.sleuth.http.HttpRequest> 実装を提供し、特定の HttpRequest をサンプリングしないタイミングを定義することです。
3. バゲッジ
分散トレースは、トレースを接続するサービス内およびサービス間でフィールドを伝播することで機能します。特に、traceId と spanId がそうです。これらのフィールドを保持するコンテキストは、多くのサービスがアクセスされるかどうかに関係なく、一貫性を保つ必要がある他のフィールドをオプションでプッシュできます。これらの追加フィールドの簡単な名前は "Baggage" です。
Sleuth を使用すると、使用されるヘッダー名など、トレースコンテキストに存在できるバゲッジを定義できます。
次の例は、Spring Cloud Sleuth の API を使用してバゲッジの値を設定する方法を示しています。
try (Tracer.SpanInScope ws = this.tracer.withSpan(initialSpan)) {
BaggageInScope businessProcess = this.tracer.createBaggage(BUSINESS_PROCESS).set("ALM");
BaggageInScope countryCode = this.tracer.createBaggage(COUNTRY_CODE).set("FO");
try {
| 現在、バゲッジの数やサイズに制限はありません。多すぎると、システムのスループットが低下したり、RPC の遅延が増加したりする可能性があることに注意してください。極端な場合、バゲッジが多すぎると、トランスポートレベルのメッセージまたはヘッダーの容量を超えて、アプリケーションがクラッシュする可能性があります。 |
プロパティを使用して、名前マッピングなどの特別な構成を持たないフィールドを定義できます。
spring.sleuth.baggage.remote-fieldsは、受け入れてリモートサービスに伝達するヘッダー名のリストです。spring.sleuth.baggage.local-fieldsは、ローカルに伝播する名前のリストです
これらのキーには接頭辞は適用されません。設定するのは文字通り使用されるものです。
これらのプロパティのいずれかに名前を設定すると、同じ名前の Baggage になります。
バゲッジの値を Slf4j の MDC に自動的に設定するには、許可されているローカルキーまたはリモートキーのリストを使用して spring.sleuth.baggage.correlation-fields プロパティを設定する必要があります。例: spring.sleuth.baggage.correlation-fields=country-code は、country-code バゲッジの値を MDC に設定します。
次のダウンストリームトレースコンテキストから開始して、追加のフィールドが伝播され、MDC に追加されることに注意してください。現在のトレースコンテキストで MDC にフィールドをすぐに追加するには、更新時にフラッシュするようにフィールドを構成します。
// configuration
@Bean
BaggageField countryCodeField() {
return BaggageField.create("country-code");
}
@Bean
ScopeDecorator mdcScopeDecorator() {
return MDCScopeDecorator.newBuilder()
.clear()
.add(SingleCorrelationField.newBuilder(countryCodeField())
.flushOnUpdate()
.build())
.build();
}
// service
@Autowired
BaggageField countryCodeField;
countryCodeField.updateValue("new-value");| MDC にエントリを追加すると、アプリケーションのパフォーマンスが大幅に低下する可能性があることに注意してください。 |
バゲッジエントリをタグとして追加する場合は、バゲッジエントリを介してスパンを検索できるようにするために、許可されたバゲッジキーのリストを使用して spring.sleuth.baggage.tag-fields の値を設定できます。この機能を無効にするには、spring.sleuth.propagation.tag.enabled=false プロパティを渡す必要があります。
3.1. バゲッジとタグ
トレース ID と同様に、Baggage は通常はヘッダーとしてメッセージまたはリクエストに添付されます。タグは、スパンで Zipkin に送信されるキーと値のペアです。デフォルトではバゲッジの値は追加されたスパンではないため、オプトインしない限りバゲッジに基づいて検索することはできません。
バゲッジにもタグを付けるには、次のようにプロパティ spring.sleuth.baggage.tag-fields を使用します。
spring:
sleuth:
baggage:
foo: bar
remoteFields:
- country-code
- x-vcap-request-id
tagFields:
- country-code4. OpenZipkin Brave トレーサー統合
Spring Cloud Sleuth は、spring-cloud-sleuth-brave モジュールで使用可能なブリッジを介して OpenZipkin Brave トレーサーと統合されます。このセクションでは、特定の Brave 統合について読むことができます。
Sleuth の API または Brave API のいずれかをコードで直接使用することを選択できます(たとえば、Sleuth の Tracer または Brave の Tracer のいずれか)。このトレーサー実装の API を直接使用する場合は、ドキュメント [GitHub] (英語) を読んで詳細を確認してください。
4.1. Brave の基本
使用する可能性のある最もコア型は次のとおりです。
brave.SpanCustomizer- 現在進行中のスパンを変更するにはbrave.Tracer- アドホックに新しいスパンを開始する
OpenZipkin Brave プロジェクトからの最も関連性の高いリンクは次のとおりです。
4.2. Brave サンプリング
サンプリングは、Zipkin などのトレースバックエンドにのみ適用されます。トレース ID は、サンプルレートに関係なくログに表示されます。サンプリングは、すべてではなく一部のリクエストを一貫して追跡することで、システムのオーバーロードを防ぐ方法です。
1 秒あたり 10 トレースのデフォルトの速度は、spring.sleuth.sampler.rate プロパティによって制御され、ロギング以外の理由で Sleuth が使用されていることがわかっている場合に適用されます。トレースシステムにオーバーロードがかかる可能性があるため、1 秒あたり 100 トレースを超えるレートを使用する場合は細心の注意を払ってください。
次の例に示すように、サンプラーは JavaConfig でも設定できます。
@Bean
public Sampler defaultSampler() {
return Sampler.ALWAYS_SAMPLE;
}
HTTP ヘッダー b3 を 1 に設定するか、メッセージングを行うときに spanFlags ヘッダーを 1 に設定できます。これを行うと、構成に関係なく、現在のリクエストが強制的にサンプリングされます。 |
デフォルトでは、サンプラーはスコープのリフレッシュメカニズムで動作します。つまり、実行時にサンプリングプロパティを変更し、アプリケーションをリフレッシュすると、変更が反映されます。ただし、サンプラーの周囲にプロキシを作成し、それを早すぎる方法で呼び出す(@PostConstruct アノテーション付きメソッドから)という事実により、デッドロックが発生する場合があります。このような場合は、サンプラー Bean を明示的に作成するか、プロパティ spring.sleuth.sampler.refresh.enabled を false に設定して、リフレッシュスコープのサポートを無効にします。
4.3. Brave バゲッジ Java 構成
上記よりも高度なことを行う必要がある場合は、プロパティを定義せず、代わりに、使用するバゲッジフィールドに @Bean 構成を使用してください。
BaggagePropagationCustomizerはバゲッジフィールドを設定しますSingleBaggageFieldを追加して、Baggageのヘッダー名を制御します。CorrelationScopeCustomizerは MDC フィールドを設定しますSingleCorrelationFieldを追加して、Baggageの MDC 名を変更するか、更新がフラッシュする場合。
4.4. Brave のカスタマイズ
brave.Tracer オブジェクトは sleuth によって完全に管理されているため、影響を与える必要はほとんどありません。とは言うものの、Sleuth は多くの Customizer 型をサポートしており、自動構成またはプロパティを使用して、Sleuth によってまだ実行されていないものを構成できます。
次のいずれかを Bean として定義すると、Sleuth はそれを呼び出して動作をカスタマイズします。
RpcTracingCustomizer- RPC タグ付けおよびサンプリングポリシー用HttpTracingCustomizer- HTTP タグ付けおよびサンプリングポリシー用MessagingTracingCustomizer- メッセージングのタグ付けとサンプリングポリシーCurrentTraceContextCustomizer- 相関などのデコレータを統合します。BaggagePropagationCustomizer- 処理中およびヘッダー上でバゲッジフィールドを伝播するためCorrelationScopeDecoratorCustomizer- MDC(ロギング)フィールド相関などのスコープ装飾用
4.4.1. Brave サンプリングのカスタマイズ
クライアント /server サンプリングが必要な場合は、型 brave.sampler.SamplerFunction<HttpRequest> の Bean を登録し、クライアントサンプラーの場合は Bean sleuthHttpClientSampler、サーバーサンプラーの場合は sleuthHttpServerSampler という名前を付けます。
便宜上、@HttpClientSampler および @HttpServerSampler アノテーションを使用して、適切な Bean を挿入したり、静的な文字列 NAME フィールドを介して Bean 名を参照したりできます。
パスベースのサンプラー github.com/openzipkin/brave/tree/master/instrumentation/http#sampling-policy (英語) を作成する方法の例については、Brave のコードを確認してください。
HttpTracing Bean を完全に書き直したい場合は、SkipPatternProvider インターフェースを使用して、サンプリングされるべきではないスパンの URL Pattern を取得できます。以下に、サーバー側 Sampler<HttpRequest> 内での SkipPatternProvider の使用例を示します。
@Configuration(proxyBeanMethods = false)
class Config {
@Bean(name = HttpServerSampler.NAME)
SamplerFunction<HttpRequest> myHttpSampler(SkipPatternProvider provider) {
Pattern pattern = provider.skipPattern();
return request -> {
String url = request.path();
boolean shouldSkip = pattern.matcher(url).matches();
if (shouldSkip) {
return false;
}
return null;
};
}
}
4.5. Brave メッセージング
Sleuth は、Kafka や JMS などのメッセージングインストルメンテーションの基盤として機能する MessagingTracing Bean を自動的に構成します。
メッセージングトレースのプロデューサー / コンシューマーサンプリングのカスタマイズが必要な場合は、型 brave.sampler.SamplerFunction<MessagingRequest> の Bean を登録し、プロデューサーサンプラーには Bean sleuthProducerSampler、コンシューマーサンプラーには sleuthConsumerSampler という名前を付けます。
便宜上、@ProducerSampler および @ConsumerSampler アノテーションを使用して、適切な Bean を挿入したり、静的な文字列 NAME フィールドを介して Bean 名を参照したりできます。
例これは、「アラート」チャネルを除いて、1 秒あたり 100 件のコンシューマーリクエストを追跡するサンプラーです。その他のリクエストでは、Tracing コンポーネントによって提供されるグローバルレートが使用されます。
@Configuration(proxyBeanMethods = false)
class Config {
@Bean(name = ConsumerSampler.NAME)
SamplerFunction<MessagingRequest> myMessagingSampler() {
return MessagingRuleSampler.newBuilder().putRule(channelNameEquals("alerts"), Sampler.NEVER_SAMPLE)
.putRule(Matchers.alwaysMatch(), RateLimitingSampler.create(100)).build();
}
}
4.6. Brave オープントレース
io.opentracing.brave:brave-opentracing ブリッジを介して Brave および OpenTracing (英語) と統合できます。クラスパスに追加するだけで、OpenTracing Tracer が自動的にセットアップされます。
5. Zipkin へのスパンの送信
Spring Cloud Sleuth は、OpenZipkin (英語) 分散トレースシステムとのさまざまな統合を提供します。選択したトレーサ実装に関係なく、spring-cloud-sleuth-zipkin をクラスパスに追加して、Zipkin へのスパンの送信を開始するだけで十分です。これを HTTP 経由で行うかメッセージング経由で行うかを選択できます。その方法について詳しくは、「 How to セクション」を参照してください。
スパンが閉じられると、HTTP 経由で Zipkin に送信されます。通信は非同期です。次のように spring.zipkin.baseUrl プロパティを設定することで URL を構成できます。
spring.zipkin.baseUrl: https://192.168.99.100:9411/ サービス検出を通じて Zipkin を検索する場合は、次の zipkinserver サービス ID の例に示すように、URL 内で Zipkin のサービス ID を渡すことができます。
spring.zipkin.baseUrl: https://zipkinserver/ この機能を無効にするには、spring.zipkin.discovery-client-enabled を false に設定するだけです。
Discovery Client 機能が有効になっている場合、Sleuth は LoadBalancerClient を使用して Zipkin サーバーの URL を検索します。これは、負荷分散構成をセットアップできることを意味します。
クラスパスに web、rabbit、activemq または kafka が一緒にある場合は、スパンを zipkin に送信する方法を選択する必要がある場合があります。これを行うには、web、rabbit、activemq または kafka を spring.zipkin.sender.type プロパティに設定します。次の例は、web の送信者型の設定を示しています。
spring.zipkin.sender.type: web 非リアクティブアプリケーションを実行している場合は、RestTemplate ベースのスパンセンダーを使用します。それ以外の場合は、WebClient ベースのスパンセンダーが選択されます。
HTTP 経由でスパンを Zipkin に送信する RestTemplate をカスタマイズするには、@Configuration アノテーション付き Spring 構成クラスに ZipkinRestTemplateCustomizer Bean を登録できます。
@Bean
ZipkinRestTemplateCustomizer myZipkinRestTemplateCustomizer() {
return new ZipkinRestTemplateCustomizer() {
@Override
public RestTemplate customizeTemplate(RestTemplate restTemplate) {
// customize the RestTemplate
return restTemplate;
}
};
}
ただし、RestTemplate オブジェクトを作成するプロセス全体を制御する場合は、ZipkinRestTemplateProvider 型の Bean を作成する必要があります。
@Bean
ZipkinRestTemplateProvider myZipkinRestTemplateProvider() {
return MyRestTemplate::new;
}
デフォルトでは、エンコーダーのバージョンに応じて、API パスが api/v2/spans または api/v1/spans に設定されます。カスタム API パスを使用する場合は、次のプロパティを使用して構成できます (空のケース、""" を設定)。
spring.zipkin.api-path: v2/path2 リアクティブアプリケーションの場合、単純な WebClient.Builder インスタンスを作成しています。独自のものを提供するか、既存のものを再利用する場合は、ZipkinWebClientBuilderProvider Bean のインスタンスを作成する必要があります。
@Bean
ZipkinWebClientBuilderProvider myZipkinWebClientBuilderProvider() {
// create your own instance or inject one from the Spring Context
return () -> WebClient.builder();
}
5.1. カスタムサービス名
デフォルトでは、Sleuth は、スパンを Zipkin に送信するときに、スパンのサービス名が spring.application.name プロパティの値と同じであることを想定します。ただし、常にそうとは限りません。アプリケーションからのすべてのスパンに異なるサービス名を明示的に指定したい場合があります。これを実現するには、次のプロパティをアプリケーションに渡してその値をオーバーライドします (例は myService という名前のサービスの場合です)。
spring.zipkin.service.name: myService5.2. ホストロケーター
| このセクションでは、サービス検出からのホストの定義について説明します。サービスディスカバリを通じて Zipkin を見つけることが目的ではありません。 |
特定のスパンに対応するホストを定義するには、ホスト名とポートを解決する必要があります。デフォルトのアプローチは、サーバーのプロパティからこれらの値を取得することです。それらが設定されていない場合は、ネットワークインターフェースからホスト名を取得しようとします。
検出クライアントを有効にしていて、サービスレジストリに登録されているインスタンスからホストアドレスを取得する場合は、次のように spring.zipkin.locator.discovery.enabled プロパティを設定する必要があります(HTTP ベースとストリームベースの両方のスパンレポートに適用できます)。
spring.zipkin.locator.discovery.enabled: true5.3. 報告されたスパンのカスタマイズ
Sleuth では、固定名のスパンを生成します。一部のユーザーは、タグの値に応じて名前を変更したいと考えています。
Sleuth は、指定された名前パターンのレポートスパンを自動的にスキップできる SpanFilter Bean を登録します。プロパティ spring.sleuth.span-filter.span-name-patterns-to-skip には、スパン名のデフォルトのスキップパターンが含まれています。プロパティ spring.sleuth.span-filter.additional-span-name-patterns-to-skip は、提供されたスパン名パターンを既存のものに追加します。この機能を無効にするには、spring.sleuth.span-filter.enabled を false に設定するだけです。
5.3.1. 報告されたスパンの Brave カスタマイズ
| このセクションは、Brave トレーサーにのみ適用されます。 |
スパンを (Zipkin などに) 報告する前に、何らかの方法でそのスパンを変更することが必要な場合があります。これを行うには、SpanHandler を実装します。
次の例は、SpanHandler を実装する 2 つの Bean を登録する方法を示しています。
@Bean
SpanHandler handlerOne() {
return new SpanHandler() {
@Override
public boolean end(TraceContext traceContext, MutableSpan span, Cause cause) {
span.name("foo");
return true; // keep this span
}
};
}
@Bean
SpanHandler handlerTwo() {
return new SpanHandler() {
@Override
public boolean end(TraceContext traceContext, MutableSpan span, Cause cause) {
span.name(span.name() + " bar");
return true; // keep this span
}
};
}
前述の例では、報告されるスパンの名前が、報告される直前に foo bar に変更されます (たとえば、Zipkin)。
5.4. Zipkin の自動構成をオーバーライドする
Spring Cloud Sleuth は、バージョン 2.1.0 以降、複数のトレースシステムへのトレースの送信をサポートしています。これを機能させるには、すべてのトレースシステムに Reporter<Span> と Sender が必要です。提供された Bean をオーバーライドする場合は、特定の名前を付ける必要があります。これを行うには、それぞれ ZipkinAutoConfiguration.REPORTER_BEAN_NAME と ZipkinAutoConfiguration.SENDER_BEAN_NAME を使用できます。
@Configuration(proxyBeanMethods = false)
protected static class MyConfig {
@Bean(ZipkinAutoConfiguration.REPORTER_BEAN_NAME)
Reporter<zipkin2.Span> myReporter(@Qualifier(ZipkinAutoConfiguration.SENDER_BEAN_NAME) MySender mySender) {
return AsyncReporter.create(mySender);
}
@Bean(ZipkinAutoConfiguration.SENDER_BEAN_NAME)
MySender mySender() {
return new MySender();
}
static class MySender extends Sender {
private boolean spanSent = false;
boolean isSpanSent() {
return this.spanSent;
}
@Override
public Encoding encoding() {
return Encoding.JSON;
}
@Override
public int messageMaxBytes() {
return Integer.MAX_VALUE;
}
@Override
public int messageSizeInBytes(List<byte[]> encodedSpans) {
return encoding().listSizeInBytes(encodedSpans);
}
@Override
public Call<Void> sendSpans(List<byte[]> encodedSpans) {
this.spanSent = true;
return Call.create(null);
}
}
}
6. ログ統合
Sleuth は、サービス名(%{spring.zipkin.service.name} または前のものが設定されていない場合は %{spring.application.name})、スパン ID(%{spanId})、トレース ID(%{traceId})などの変数を使用してロギングコンテキストを構成します。これらは、ログを分散トレースに接続するのに役立ち、サービスのトラブルシューティングに使用するツールを選択できます。
エラーのあるログを見つけたら、メッセージでトレース ID を探すことができます。それを分散トレースシステムに貼り付けて、最初のリクエストがヒットしたサービスの数に関係なく、トレース全体を視覚化します。
backend.log: 2020-04-09 17:45:40.516 ERROR [backend,5e8eeec48b08e26882aba313eb08f0a4,dcc1df555b5777b3] 97203 --- [nio-9000-exec-1] o.s.c.s.i.web.ExceptionLoggingFilter : Uncaught exception thrown
frontend.log:2020-04-09 17:45:40.574 ERROR [frontend,5e8eeec48b08e26882aba313eb08f0a4,82aba313eb08f0a4] 97192 --- [nio-8081-exec-2] o.s.c.s.i.web.ExceptionLoggingFilter : Uncaught exception thrown 上記では、たとえば、トレース ID が 5e8eeec48b08e26882aba313eb08f0a4 であることがわかります。このログ構成は、Sleuth によって自動的に設定されました。spring.sleuth.enabled=false プロパティを介して Sleuth を無効にするか、独自の logging.pattern.level プロパティを設定することで、無効にすることができます。
ログ集約ツール(キバナ (英語) 、Splunk (英語) など)を使用する場合は、発生したイベントをオーダーできます。Kibana の例は、次のイメージのようになります。
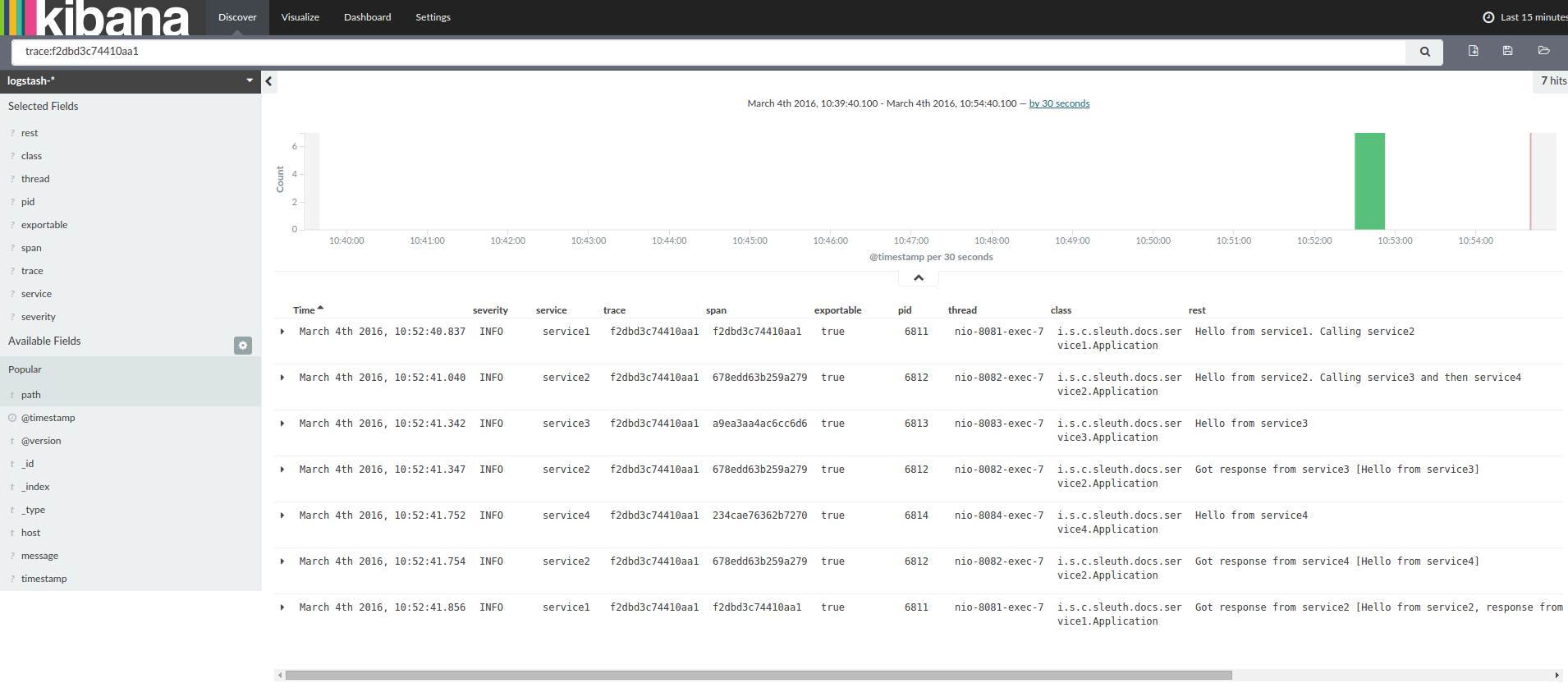
Logstash (英語) を使用する場合、次のリストは Logstash の Grok パターンを示しています。
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
date {
match => ["timestamp", "ISO8601"]
}
mutate {
remove_field => ["timestamp"]
}
}| Grok を Cloud Foundry のログと一緒に使用する場合は、次のパターンを使用する必要があります。 |
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
date {
match => ["timestamp", "ISO8601"]
}
mutate {
remove_field => ["timestamp"]
}
}6.1. Logstash を使用した JSON Logback
多くの場合、ログをテキストファイルではなく、Logstash がすぐに選択できる JSON ファイルに保存する必要があります。これを行うには、次のことを行う必要があります(読みやすくするために、依存関係を groupId:artifactId:version 表記で渡します)。
依存関係の設定
Logback がクラスパス(
ch.qos.logback:logback-core)にあることを確認します。Logstash Logback エンコードを追加します。例: バージョン
4.6を使用するには、net.logstash.logback:logstash-logback-encoder:4.6を追加します。
Logback セットアップ
次の Logback 構成ファイル(logback-spring.xml)の例について考えてみます。
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"timestamp": "@timestamp",
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{traceId:-}",
"span": "%X{spanId:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>その Logback 構成ファイル:
アプリケーションからの情報を JSON 形式で
build/${spring.application.name}.jsonファイルに記録します。コンソールと標準ログファイルの 2 つの追加アペンダーをコメントアウトしました。
前のセクションで示したものと同じログパターンがあります。
カスタム logback-spring.xml を使用する場合は、application プロパティファイルではなく、bootstrap で spring.application.name を渡す必要があります。そうしないと、カスタム logback ファイルがプロパティを正しく読み取れません。 |
7. 自己ドキュメント化スパン
スパン構成を表す宣言形式は、DocumentedSpan 抽象化を介して導入されました。Sleuth のソースコードを分析することにより、すべてのスパン特性(許可されたタグキーとイベント名を含む)を含む付録が作成されます。詳細については、SleuthSpans 付録を確認してください。
8. アクチュエーターエンドポイントをトレースします
Spring Cloud Sleuth には、完成したスパンを保存できる traces アクチュエーターエンドポイントが付属しています。エンドポイントは、保存されているスパンのリストを取得するための HTTP Get メソッドを介して、またはリストを取得してクリアするための HTTPPost メソッドを介して照会できます。
スパンが保管されるキューのサイズは、management.endpoint.traces.queue-size プロパティを介して構成できます。
アクチュエーターエンドポイント構成オプションの詳細については、ドキュメントの Spring Boot Actuator: 本番対応機能セクションを参照してください。
9. 次のステップ
このセクションで説明されているクラスのいずれかについて詳しく知りたい場合は、ソースコードを直接 [GitHub] (英語) 参照できます。特定の質問がある場合は、使い方セクションを参照してください。
Spring Cloud Sleuth のコア機能に慣れている場合は、続行して Spring Cloud Sleuth の統合について読むことができます。